使用 Bitmap 进行精确去重计数
本文档介绍如何使用 Bitmap 在 StarRocks 中计算不同值的数量。
Bitmap 是用于计算数组中不同值数量的有用工具。 与传统的 Count Distinct 相比,此方法占用更少的存储空间,并且可以加快计算速度。 假设有一个名为 A 的数组,其值范围为 [0, n)。 通过使用 (n+7)/8 字节的 bitmap,可以计算数组中不同元素的数量。 为此,请将所有位初始化为 0,将元素的值设置为位的下标,然后将所有位设置为 1。 bitmap 中 1 的数量就是数组中不同元素的数量。
传统的 Count Distinct
StarRocks 使用 MPP 架构,可以在使用 Count Distinct 时保留详细数据。 但是,Count Distinct 功能在查询处理期间需要多次数据 shuffle,这会消耗更多资源,并导致性能随着数据量的增加而线性下降。
以下场景基于表 (dt, page, user_id) 中的详细数据计算 UV。
| dt | page | user_id |
|---|---|---|
| 20191206 | game | 101 |
| 20191206 | shopping | 102 |
| 20191206 | game | 101 |
| 20191206 | shopping | 101 |
| 20191206 | game | 101 |
| 20191206 | shopping | 101 |
StarRocks 根据下图计算数据。 它首先按 page 和 user_id 列对数据进行分组,然后对处理后的结果进行计数。
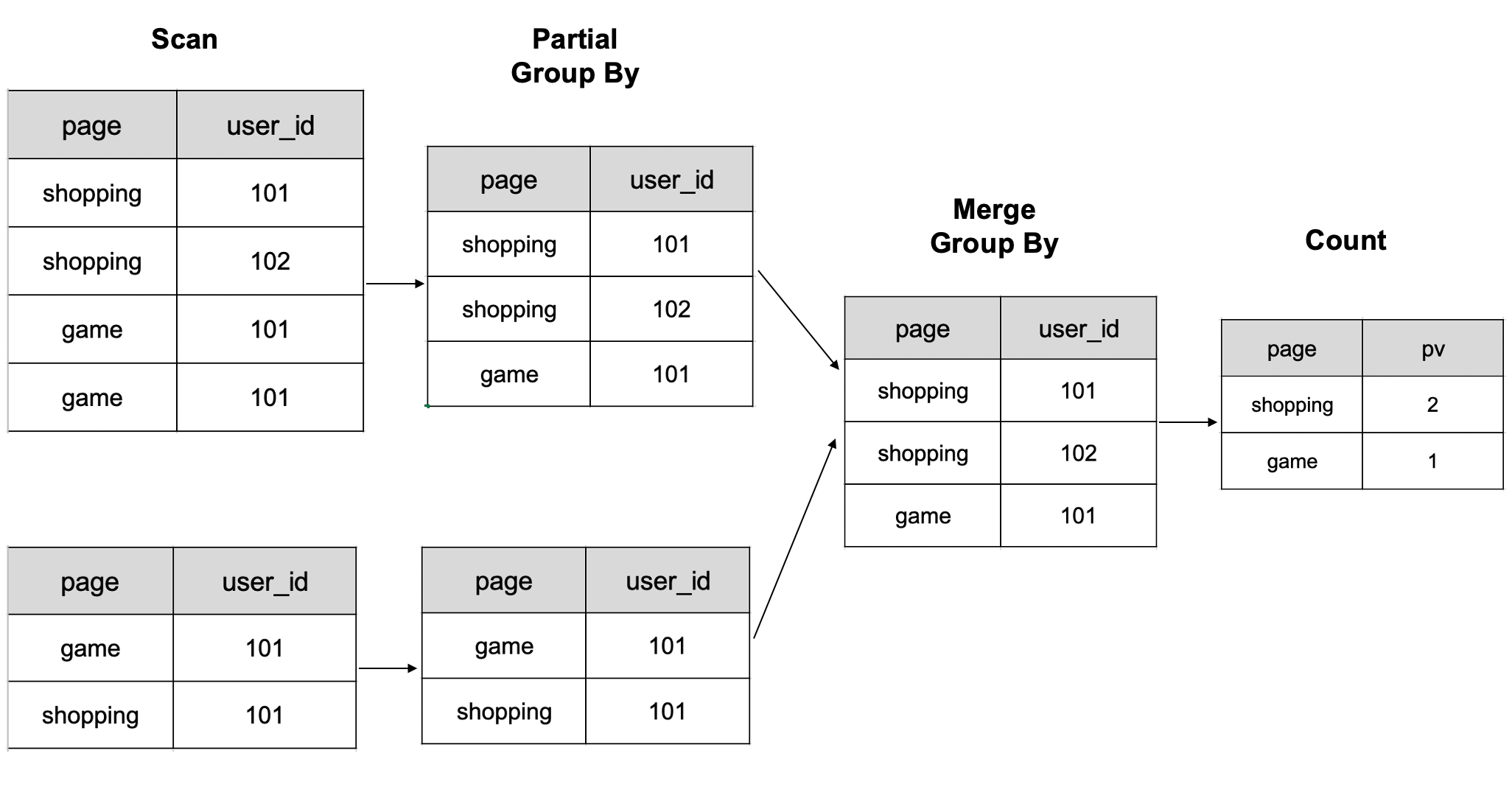
- 注意:该图显示了在两个 BE 节点上计算的 6 行数据的示意图。
当处理需要多次 shuffle 操作的大量数据时,所需的计算资源可能会显着增加。 这会减慢查询速度。 但是,使用 Bitmap 技术可以帮助解决此问题并提高此类场景中的查询性能。
按 page 分组计算 uv
select page, count(distinct user_id) as uv from table group by page;
| page | uv |
| :---: | :---: |
| game | 1 |
| shopping | 2 |
使用 Bitmap 进行 Count Distinct 的好处
与 COUNT(DISTINCT expr) 相比,您可以从以下几个方面受益于 Bitmap:
- 更少的存储空间:如果使用 bitmap 计算 INT32 数据的不同值的数量,则所需的存储空间仅为 COUNT(DISTINCT expr) 的 1/32。 StarRocks 利用压缩的 Roaring Bitmaps 来执行计算,与传统的 Bitmap 相比,进一步减少了存储空间的使用。
- 更快的计算速度:Bitmap 使用按位运算,与 COUNT(DISTINCT expr) 相比,计算速度更快。 在 StarRocks 中,不同值的数量的计算可以并行处理,从而进一步提高查询性能。
有关 Roaring Bitmap 的实现的更多信息,请参阅特定论文和实现。
使用说明
- Bitmap 索引和 Bitmap Count Distinct 都使用 Bitmap 技术。 但是,引入它们的目的和它们解决的问题完全不同。 前者用于过滤低基数的枚举列,而后者用于计算数据行的值列中不同元素的数量。
- StarRocks 2.3 及更高版本支持将值列定义为 BITMAP,而不管表类型(聚合表、Duplicate Key 表、主键表或 Unique Key 表)。 但是,表的排序键不能是 BITMAP 类型。
- 创建表时,可以将值列定义为 BITMAP,并将聚合函数定义为BITMAP_UNION。
- 您只能使用 Roaring Bitmaps 来计算以下类型数据的不同值的数量:TINYINT、SMALLINT、INT 和 BIGINT。 对于其他类型的数据,您需要构建全局字典。
使用 Bitmap 进行 Count Distinct
以页面 UV 的计算为例。
-
创建一个具有 BITMAP 列
visit_users的聚合表,该表使用聚合函数 BITMAP_UNION。CREATE TABLE `page_uv` (
`page_id` INT NOT NULL COMMENT 'page ID',
`visit_date` datetime NOT NULL COMMENT 'access time',
`visit_users` BITMAP BITMAP_UNION NOT NULL COMMENT 'user ID'
) ENGINE=OLAP
AGGREGATE KEY(`page_id`, `visit_date`)
DISTRIBUTED BY HASH(`page_id`)
PROPERTIES (
"replication_num" = "3",
"storage_format" = "DEFAULT"
); -
将数据加载到此表中。
使用 INSET INTO 加载数据
INSERT INTO page_uv VALUES
(1, '2020-06-23 01:30:30', to_bitmap(13)),
(1, '2020-06-23 01:30:30', to_bitmap(23)),
(1, '2020-06-23 01:30:30', to_bitmap(33)),
(1, '2020-06-23 02:30:30', to_bitmap(13)),
(2, '2020-06-23 01:30:30', to_bitmap(23));数据加载后
- 在行
page_id = 1, visit_date = '2020-06-23 01:30:30'中,visit_users字段包含三个 Bitmap 元素 (13, 23, 33)。 - 在行
page_id = 1, visit_date = '2020-06-23 02:30:30'中,visit_users字段包含一个 Bitmap 元素 (13)。 - 在行
page_id = 2, visit_date = '2020-06-23 01:30:30'中,visit_users字段包含一个 Bitmap 元素 (23)。
从本地文件加载数据
echo -e '1,2020-06-23 01:30:30,130\n1,2020-06-23 01:30:30,230\n1,2020-06-23 01:30:30,120\n1,2020-06-23 02:30:30,133\n2,2020-06-23 01:30:30,234' > tmp.csv |
curl --location-trusted -u <username>:<password> -H "label:label_1600960288798" \
-H "column_separator:," \
-H "columns:page_id,visit_date,visit_users, visit_users=to_bitmap(visit_users)" -T tmp.csv \
http://StarRocks_be0:8040/api/db0/page_uv/_stream_load - 在行
-
计算页面 UV。
SELECT page_id, count(distinct visit_users) FROM page_uv GROUP BY page_id;
+-----------+------------------------------+
| page_id | count(DISTINCT `visit_users`)|
+-----------+------------------------------+
| 1 | 3 |
| 2 | 1 |
+-----------+------------------------------+
2 row in set (0.00 sec)
全局字典
目前,基于 Bitmap 的 Count Distinct 机制要求输入为整数。 如果用户需要使用其他数据类型作为 Bitmap 的输入,则用户需要构建自己的全局字典,以将其他类型的数据(例如字符串类型)映射到整数类型。 构建全局字典有几种思路。
基于 Hive 表的全局字典
此方案中的全局字典本身就是一个 Hive 表,它有两列,一列用于原始值,一列用于编码的 Int 值。 生成全局字典的步骤如下
- 对事实表的字典列进行去重,以生成临时表
- 左连接临时表和全局字典,将
new value添加到临时表。 - 对
new value进行编码并将其插入到全局字典中。 - 左连接事实表和更新后的全局字典,将字典项替换为 ID。
这样,可以使用 Spark 或 MR 更新全局字典,并替换事实表中的值列。 与基于 trie 树的全局字典相比,此方法可以分布式,并且可以重复使用全局字典。
但是,有几件事需要注意:原始事实表被多次读取,并且有两个连接会在全局字典的计算过程中消耗大量额外资源。
基于 trie 树构建全局字典
用户还可以使用 trie 树(也称为前缀树或字典树)构建自己的全局字典。 trie 树对于节点后代具有公共前缀,这可用于减少查询时间并最大限度地减少字符串比较,因此非常适合用于实现字典编码。 但是,trie 树的实现不易于分布式,并且当数据量相对较大时可能会产生性能瓶颈。
通过构建全局字典并将其他类型的数据转换为整数数据,您可以使用 Bitmap 对非整数数据列执行精确的 Count Distinct 分析。