查询缓存
查询缓存是 StarRocks 的一项强大功能,可以显著提高聚合查询的性能。通过将本地聚合的中间结果存储在内存中,查询缓存可以避免对与之前查询相同或相似的新查询进行不必要的磁盘访问和计算。借助查询缓存,StarRocks 可以为聚合查询提供快速准确的结果,从而节省时间和资源,并实现更好的可扩展性。查询缓存对于许多用户对大型复杂数据集运行类似查询的高并发场景尤其有用。
自 v2.5 起,共享存储集群支持此功能;自 v3.4.0 起,共享数据集群也支持此功能。
在 v2.5 中,查询缓存仅支持对单个平面表执行聚合查询。自 v3.0 起,查询缓存还支持对以星型模式连接的多个表执行聚合查询。
应用场景
建议在以下场景中使用查询缓存
- 您经常在单个平面表或以星型模式连接的多个连接表上运行聚合查询。
- 您的大多数聚合查询都是非 GROUP BY 聚合查询和低基数列 GROUP BY 聚合查询。
- 您的数据以追加模式按时间分区加载,并且可以根据访问频率分为热数据和冷数据。
查询缓存支持满足以下条件的查询
-
查询引擎是 Pipeline。要启用 Pipeline 引擎,请将会话变量
enable_pipeline_engine设置为true。注意
其他查询引擎不支持查询缓存。
-
查询是在原生 OLAP 表(从 v2.5 开始)或云原生表(从 v3.0 开始)上进行的。查询缓存不支持对外部表的查询。查询缓存还支持其计划需要访问同步物化视图的查询。但是,查询缓存不支持其计划需要访问异步物化视图的查询。
-
查询是对单个表或多个连接表的聚合查询。
注意
- 查询缓存支持 Broadcast Join 和 Bucket Shuffle Join。
- 查询缓存支持包含 Join 算子的两种树结构:Aggregation-Join 和 Join-Aggregation。Shuffle 连接在 Aggregation-Join 树结构中不受支持,而 Hash 连接在 Join-Aggregation 树结构中不受支持。
-
查询不包括非确定性函数,例如
rand、random、uuid和sleep。
查询缓存支持对使用以下任何分区策略的表进行查询:未分区、多列分区和单列分区。
功能边界
- 查询缓存基于 Pipeline 引擎的每个 Tablet 计算。每个 Tablet 计算意味着管道驱动程序可以逐个处理整个 Tablet,而不是处理 Tablet 的一部分或许多 Tablet 交错在一起。如果每个 BE 需要处理的 Tablet 数量大于或等于为运行此查询而调用的管道驱动程序的数量,则查询缓存有效。调用的管道驱动程序的数量表示实际的并行度 (DOP)。如果 Tablet 数量小于管道驱动程序的数量,则每个管道驱动程序仅处理特定 Tablet 的一部分。在这种情况下,无法生成每个 Tablet 的计算结果,因此查询缓存不起作用。
- 在 StarRocks 中,聚合查询至少包含四个阶段。只有当 OlapScanNode 和 AggregateNode 计算来自同一 Fragment 的数据时,才能缓存第一阶段 AggregateNode 生成的每个 Tablet 计算结果。无法缓存其他阶段 AggregateNode 生成的每个 Tablet 计算结果。对于某些 DISTINCT 聚合查询,如果将会话变量
cbo_cte_reuse设置为true,则当生成数据的 OlapScanNode 和消耗生成数据的 stage-1 AggregateNode 计算来自不同 Fragment 的数据并由 ExchangeNode 连接时,查询缓存不起作用。以下两个示例展示了执行 CTE 优化的场景,因此查询缓存不起作用- 输出列通过使用聚合函数
avg(distinct)来计算。 - 输出列通过多个 DISTINCT 聚合函数计算。
- 输出列通过使用聚合函数
- 如果在聚合之前对数据进行混洗,则查询缓存无法加速对该数据的查询。
- 如果表的分组列或去重列是高基数列,则针对该表的聚合查询将生成大量结果。在这些情况下,查询将在运行时绕过查询缓存。
- 查询缓存占用 BE 提供的一小部分内存来保存计算结果。查询缓存的大小默认为 512 MB。因此,查询缓存不适合保存大型数据项。此外,启用查询缓存后,如果缓存命中率低,查询性能会下降。因此,如果为 Tablet 生成的计算结果的大小超过
query_cache_entry_max_bytes或query_cache_entry_max_rows参数指定的阈值,则查询缓存不再适用于该查询,并且该查询将切换到 Passthrough 模式。
工作原理
启用查询缓存后,每个 BE 将查询的本地聚合拆分为以下两个阶段
-
每个 Tablet 聚合
BE 单独处理每个 Tablet。当 BE 开始处理 Tablet 时,它首先探测查询缓存,以查看该 Tablet 上的聚合的中间结果是否在查询缓存中。如果是(缓存命中),BE 直接从查询缓存中获取中间结果。如果没有(缓存未命中),BE 访问磁盘上的数据并执行本地聚合以计算中间结果。当 BE 完成处理 Tablet 时,它会将该 Tablet 上的聚合的中间结果填充到查询缓存中。
-
Tablet 间聚合
BE 收集来自查询中涉及的所有 Tablet 的中间结果,并将它们合并为最终结果。
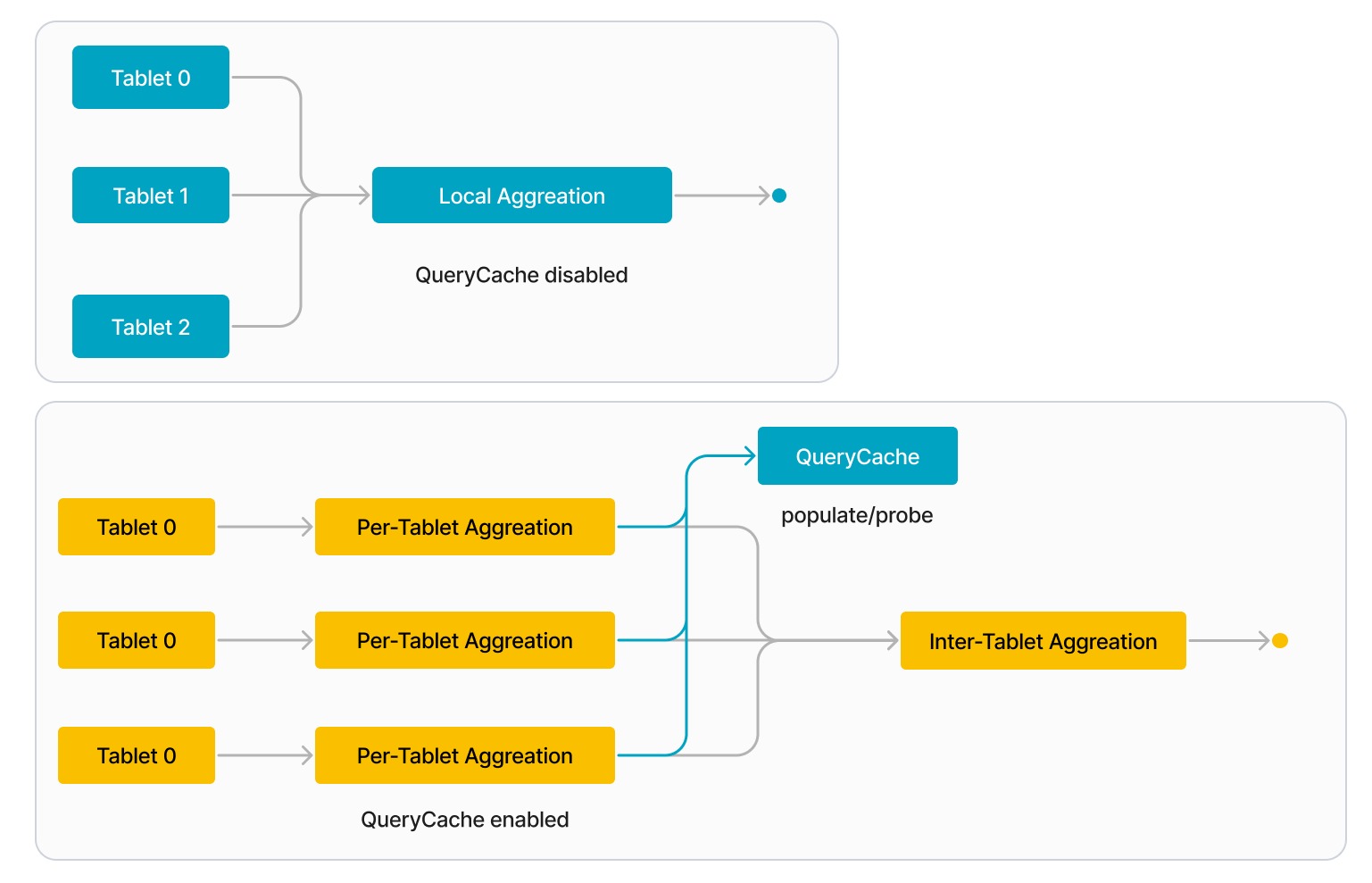
当将来发出类似查询时,它可以重用先前查询的缓存结果。例如,下图所示的查询涉及三个 Tablet(Tablet 0 到 2),并且第一个 Tablet(Tablet 0)的中间结果已在查询缓存中。对于此示例,BE 可以直接从查询缓存中获取 Tablet 0 的结果,而不是访问磁盘上的数据。如果查询缓存已完全预热,则它可以包含所有三个 Tablet 的中间结果,因此 BE 不需要访问任何磁盘上的数据。
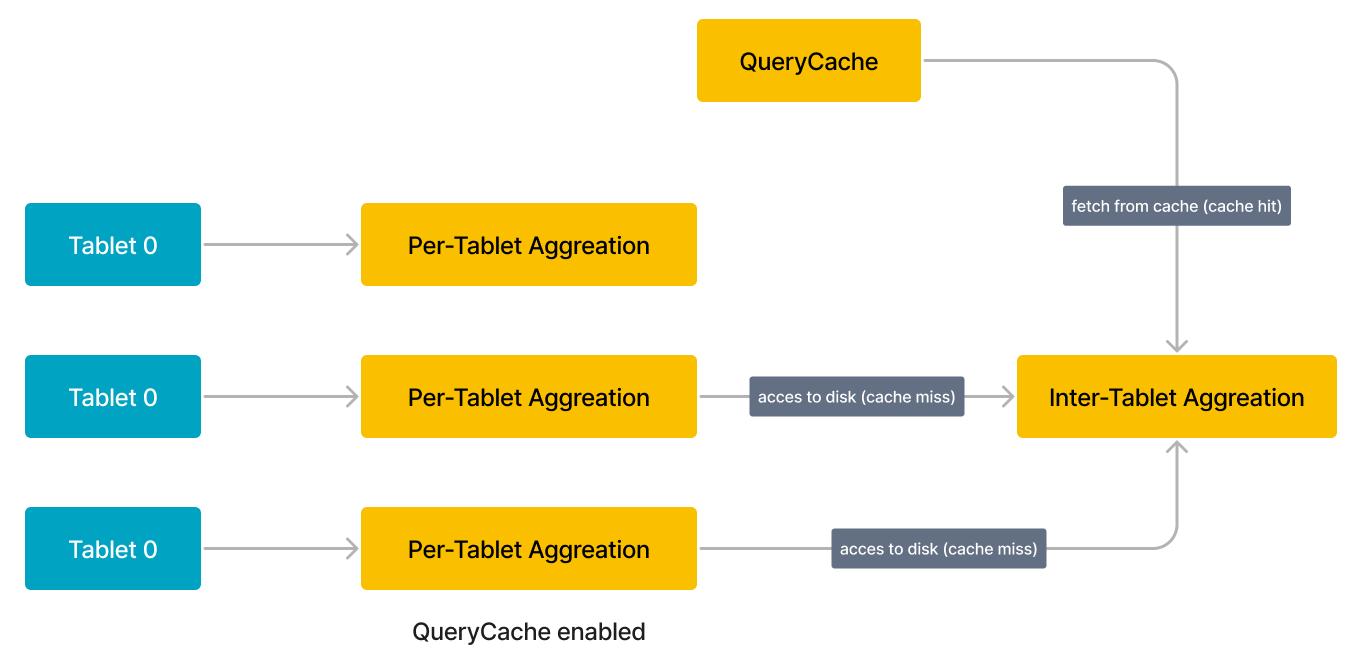
为了释放额外的内存,查询缓存采用基于最近最少使用 (LRU) 的驱逐策略来管理其中的缓存条目。根据此驱逐策略,当查询缓存占用的内存量超过其预定义的大小 (query_cache_capacity) 时,最近最少使用的缓存条目将被从查询缓存中驱逐出去。
注意
将来,StarRocks 还将支持基于生存时间 (TTL) 的驱逐策略,根据该策略,缓存条目可以从查询缓存中驱逐出去。
FE 确定是否需要使用查询缓存加速每个查询,并对查询进行规范化以消除对查询语义没有影响的微不足道的字面量细节。
为了防止查询缓存的不良情况造成的性能损失,BE 采用自适应策略在运行时绕过查询缓存。
启用查询缓存
本节介绍用于启用和配置查询缓存的参数和会话变量。
FE 会话变量
| 变量 | 默认值 | 可以动态配置 | 描述 |
|---|---|---|---|
| enable_query_cache | false | 是 | 指定是否启用查询缓存。有效值:true 和 false。true 指定启用此功能,false 指定禁用此功能。启用查询缓存后,它仅适用于满足本主题的“应用场景”部分中指定的条件的查询。 |
| query_cache_entry_max_bytes | 4194304 | 是 | 指定触发 Passthrough 模式的阈值。有效值:0 到 9223372036854775807。当查询访问的特定 Tablet 的计算结果的字节数或行数超过 query_cache_entry_max_bytes 或 query_cache_entry_max_rows 参数指定的阈值时,查询将切换到 Passthrough 模式。如果将 query_cache_entry_max_bytes 或 query_cache_entry_max_rows 参数设置为 0,即使没有从涉及的 Tablet 生成计算结果,也会使用 Passthrough 模式。 |
| query_cache_entry_max_rows | 409600 | 是 | 同上。 |
BE 参数
您需要在 BE 配置文件 be.conf 中配置以下参数。在为 BE 重新配置此参数后,您必须重新启动 BE 才能使新的参数设置生效。
| 参数 | 必需 | 描述 |
|---|---|---|
| query_cache_capacity | 否 | 指定查询缓存的大小。单位:字节。默认大小为 512 MB。 每个 BE 都有其自己的内存中的本地查询缓存,并且它仅填充和探测其自己的查询缓存。 请注意,查询缓存大小不能小于 4 MB。如果 BE 的内存容量不足以提供您期望的查询缓存大小,则可以增加 BE 的内存容量。 |
专为在所有场景中实现最大缓存命中率而设计
考虑三种场景,即使查询在字面上不相同,查询缓存仍然有效。这三个场景是
- 语义等效查询
- 扫描的分区重叠的查询
- 针对仅追加数据更改的数据的查询(没有 UPDATE 或 DELETE 操作)
语义等效查询
当两个查询相似时,这并不意味着它们必须在字面上等效,而是意味着它们在其执行计划中包含语义等效的片段,则它们被认为是语义等效的,并且可以重用彼此的计算结果。从广义上讲,如果两个查询从同一来源查询数据、使用相同的计算方法并具有相同的执行计划,则它们在语义上是等效的。StarRocks 应用以下规则来评估两个查询是否在语义上等效
-
如果两个查询包含多个聚合,只要它们的第一个聚合在语义上等效,它们就会被评估为语义等效。例如,以下两个查询 Q1 和 Q2 都包含多个聚合,但它们的第一个聚合在语义上是等效的。因此,Q1 和 Q2 被评估为语义等效。
-
Q1
SELECT
(
ifnull(sum(murmur_hash3_32(hour)), 0) + ifnull(sum(murmur_hash3_32(k0)), 0) + ifnull(sum(murmur_hash3_32(__c_0)), 0)
) AS fingerprint
FROM
(
SELECT
date_trunc('hour', ts) AS hour,
k0,
sum(v1) AS __c_0
FROM
t0
WHERE
ts between '2022-01-03 00:00:00'
and '2022-01-03 23:59:59'
GROUP BY
date_trunc('hour', ts),
k0
) AS t; -
Q2
SELECT
date_trunc('hour', ts) AS hour,
k0,
sum(v1) AS __c_0
FROM
t0
WHERE
ts between '2022-01-03 00:00:00'
and '2022-01-03 23:59:59'
GROUP BY
date_trunc('hour', ts),
k0
-
-
如果两个查询都属于以下查询类型之一,则可以将它们评估为语义等效。请注意,包含 HAVING 子句的查询不能被评估为与不包含 HAVING 子句的查询在语义上等效。但是,包含 ORDER BY 或 LIMIT 子句不会影响评估两个查询是否在语义上等效。
-
GROUP BY 聚合
SELECT <GroupByItems>, <AggFunctionItems>
FROM <Table>
WHERE <Predicates> [and <PartitionColumnRangePredicate>]
GROUP BY <GroupByItems>
[HAVING <HavingPredicate>]注意
在前面的示例中,HAVING 子句是可选的。
-
GROUP BY DISTINCT 聚合
SELECT DISTINCT <GroupByItems>, <Items>
FROM <Table>
WHERE <Predicates> [and <PartitionColumnRangePredicate>]
GROUP BY <GroupByItems>
HAVING <HavingPredicate>注意
在前面的示例中,HAVING 子句是可选的。
-
非 GROUP BY 聚合
SELECT <AggFunctionItems> FROM <Table>
WHERE <Predicates> [and <PartitionColumnRangePredicate>] -
非 GROUP BY DISTINCT 聚合
SELECT DISTINCT <Items> FROM <Table>
WHERE <Predicates> [and <PartitionColumnRangePredicate>]
-
-
如果任一查询包含
PartitionColumnRangePredicate,则在评估两个查询的语义等效性之前,将删除PartitionColumnRangePredicate。PartitionColumnRangePredicate指定引用分区列的以下类型的谓词之一col between v1 and v2:分区列的值落在 [v1, v2] 范围内,其中v1和v2是常量表达式。v1 < col and col < v2:分区列的值落在 (v1, v2) 范围内,其中v1和v2是常量表达式。v1 < col and col <= v2:分区列的值落在 (v1, v2] 范围内,其中v1和v2是常量表达式。v1 <= col and col < v2:分区列的值落在 [v1, v2) 范围内,其中v1和v2是常量表达式。v1 <= col and col <= v2:分区列的值落在 [v1, v2] 范围内,其中v1和v2是常量表达式。
-
如果在重新排列后,两个查询的 SELECT 子句的输出列相同,则两个查询被评估为语义等效。
-
如果在重新排列后,两个查询的 GROUP BY 子句的输出列相同,则两个查询被评估为语义等效。
-
如果在删除
PartitionColumnRangePredicate后,两个查询的 WHERE 子句的剩余谓词在语义上等效,则两个查询被评估为语义等效。 -
如果两个查询的 HAVING 子句中的谓词在语义上等效,则两个查询被评估为语义等效。
使用以下表 lineorder_flat 作为示例
CREATE TABLE `lineorder_flat`
(
`lo_orderdate` date NOT NULL COMMENT "",
`lo_orderkey` int(11) NOT NULL COMMENT "",
`lo_linenumber` tinyint(4) NOT NULL COMMENT "",
`lo_custkey` int(11) NOT NULL COMMENT "",
`lo_partkey` int(11) NOT NULL COMMENT "",
`lo_suppkey` int(11) NOT NULL COMMENT "",
`lo_orderpriority` varchar(100) NOT NULL COMMENT "",
`lo_shippriority` tinyint(4) NOT NULL COMMENT "",
`lo_quantity` tinyint(4) NOT NULL COMMENT "",
`lo_extendedprice` int(11) NOT NULL COMMENT "",
`lo_ordtotalprice` int(11) NOT NULL COMMENT "",
`lo_discount` tinyint(4) NOT NULL COMMENT "",
`lo_revenue` int(11) NOT NULL COMMENT "",
`lo_supplycost` int(11) NOT NULL COMMENT "",
`lo_tax` tinyint(4) NOT NULL COMMENT "",
`lo_commitdate` date NOT NULL COMMENT "",
`lo_shipmode` varchar(100) NOT NULL COMMENT "",
`c_name` varchar(100) NOT NULL COMMENT "",
`c_address` varchar(100) NOT NULL COMMENT "",
`c_city` varchar(100) NOT NULL COMMENT "",
`c_nation` varchar(100) NOT NULL COMMENT "",
`c_region` varchar(100) NOT NULL COMMENT "",
`c_phone` varchar(100) NOT NULL COMMENT "",
`c_mktsegment` varchar(100) NOT NULL COMMENT "",
`s_name` varchar(100) NOT NULL COMMENT "",
`s_address` varchar(100) NOT NULL COMMENT "",
`s_city` varchar(100) NOT NULL COMMENT "",
`s_nation` varchar(100) NOT NULL COMMENT "",
`s_region` varchar(100) NOT NULL COMMENT "",
`s_phone` varchar(100) NOT NULL COMMENT "",
`p_name` varchar(100) NOT NULL COMMENT "",
`p_mfgr` varchar(100) NOT NULL COMMENT "",
`p_category` varchar(100) NOT NULL COMMENT "",
`p_brand` varchar(100) NOT NULL COMMENT "",
`p_color` varchar(100) NOT NULL COMMENT "",
`p_type` varchar(100) NOT NULL COMMENT "",
`p_size` tinyint(4) NOT NULL COMMENT "",
`p_container` varchar(100) NOT NULL COMMENT ""
)
ENGINE=OLAP
DUPLICATE KEY(`lo_orderdate`, `lo_orderkey`)
COMMENT "olap"
PARTITION BY RANGE(`lo_orderdate`)
(PARTITION p1 VALUES [('0000-01-01'), ('1993-01-01')),
PARTITION p2 VALUES [('1993-01-01'), ('1994-01-01')),
PARTITION p3 VALUES [('1994-01-01'), ('1995-01-01')),
PARTITION p4 VALUES [('1995-01-01'), ('1996-01-01')),
PARTITION p5 VALUES [('1996-01-01'), ('1997-01-01')),
PARTITION p6 VALUES [('1997-01-01'), ('1998-01-01')),
PARTITION p7 VALUES [('1998-01-01'), ('1999-01-01')))
DISTRIBUTED BY HASH(`lo_orderkey`)
PROPERTIES
(
"replication_num" = "3",
"colocate_with" = "groupxx1",
"storage_format" = "DEFAULT",
"enable_persistent_index" = "true",
"compression" = "LZ4"
);
以下两个查询 Q1 和 Q2 在按如下方式处理后,表 lineorder_flat 在语义上是等效的
- 重新排列 SELECT 语句的输出列。
- 重新排列 GROUP BY 子句的输出列。
- 删除 ORDER BY 子句的输出列。
- 重新排列 WHERE 子句中的谓词。
- 添加
PartitionColumnRangePredicate。
-
Q1
SELECT sum(lo_revenue), year(lo_orderdate) AS year,p_brand
FROM lineorder_flat
WHERE p_category = 'MFGR#12' AND s_region = 'AMERICA'
GROUP BY year,p_brand
ORDER BY year,p_brand; -
Q2
SELECT year(lo_orderdate) AS year, p_brand, sum(lo_revenue)
FROM lineorder_flat
WHERE s_region = 'AMERICA' AND p_category = 'MFGR#12' AND
lo_orderdate >= '1993-01-01' AND lo_orderdate <= '1993-12-31'
GROUP BY p_brand, year(lo_orderdate)
语义等效性基于查询的物理计划进行评估。因此,查询中的字面量差异不会影响语义等效性的评估。此外,常量表达式将从查询中删除,并且 cast 表达式在查询优化期间删除。因此,这些表达式不会影响语义等效性的评估。第三,列和关系的别名也不会影响语义等效性的评估。
扫描的分区重叠的查询
查询缓存支持基于谓词的查询拆分。
基于谓词语义拆分查询有助于实现部分计算结果的重用。当查询包含引用表的分区列的谓词,并且谓词指定值范围时,StarRocks 可以根据表分区将范围拆分为多个间隔。每个间隔的计算结果可以由其他查询单独重用。
使用以下表 t0 作为示例
CREATE TABLE if not exists t0
(
ts DATETIME NOT NULL,
k0 VARCHAR(10) NOT NULL,
k1 BIGINT NOT NULL,
v1 DECIMAL64(7, 2) NOT NULL
)
ENGINE=OLAP
DUPLICATE KEY(`ts`, `k0`, `k1`)
COMMENT "OLAP"
PARTITION BY RANGE(ts)
(
START ("2022-01-01 00:00:00") END ("2022-02-01 00:00:00") EVERY (INTERVAL 1 day)
)
DISTRIBUTED BY HASH(`ts`, `k0`, `k1`)
PROPERTIES
(
"replication_num" = "3",
"storage_format" = "default"
);
表 t0 按天分区,列 ts 是表的分区列。在以下四个查询中,Q2、Q3 和 Q4 可以重用为 Q1 缓存的部分计算结果
-
Q1
SELECT date_trunc('day', ts) as day, sum(v0)
FROM t0
WHERE ts BETWEEN '2022-01-02 12:30:00' AND '2022-01-14 23:59:59'
GROUP BY day;Q1 的谓词
ts between '2022-01-02 12:30:00' and '2022-01-14 23:59:59'指定的值范围可以拆分为以下间隔1. [2022-01-02 12:30:00, 2022-01-03 00:00:00),
2. [2022-01-03 00:00:00, 2022-01-04 00:00:00),
3. [2022-01-04 00:00:00, 2022-01-05 00:00:00),
...
12. [2022-01-13 00:00:00, 2022-01-14 00:00:00),
13. [2022-01-14 00:00:00, 2022-01-15 00:00:00), -
Q2
SELECT date_trunc('day', ts) as day, sum(v0)
FROM t0
WHERE ts >= '2022-01-02 12:30:00' AND ts < '2022-01-05 00:00:00'
GROUP BY day;Q2 可以重用 Q1 以下间隔内的计算结果
1. [2022-01-02 12:30:00, 2022-01-03 00:00:00),
2. [2022-01-03 00:00:00, 2022-01-04 00:00:00),
3. [2022-01-04 00:00:00, 2022-01-05 00:00:00), -
Q3
SELECT date_trunc('day', ts) as day, sum(v0)
FROM t0
WHERE ts >= '2022-01-01 12:30:00' AND ts <= '2022-01-10 12:00:00'
GROUP BY day;Q3 可以重用 Q1 以下间隔内的计算结果
2. [2022-01-03 00:00:00, 2022-01-04 00:00:00),
3. [2022-01-04 00:00:00, 2022-01-05 00:00:00),
...
8. [2022-01-09 00:00:00, 2022-01-10 00:00:00), -
Q4
SELECT date_trunc('day', ts) as day, sum(v0)
FROM t0
WHERE ts BETWEEN '2022-01-02 12:30:00' and '2022-01-02 23:59:59'
GROUP BY day;Q4 可以重用 Q1 以下间隔内的计算结果
1. [2022-01-02 12:30:00, 2022-01-03 00:00:00),
对部分计算结果重用的支持程度取决于所使用的分区策略,如下表所述。
| 分区策略 | 对部分计算结果重用的支持 |
|---|---|
| 未分区 | 不支持 |
| 多列分区 | 不支持 注意 将来可能会支持此功能。 |
| 单列分区 | 支持 |
针对仅追加数据更改的数据的查询
查询缓存支持多版本缓存。
进行数据加载时,会生成新的 Tablet 版本。因此,从 Tablet 的先前版本生成的缓存计算结果将变得陈旧,并且会滞后于最新的 Tablet 版本。在这种情况下,多版本缓存机制尝试将保存在查询缓存中的陈旧结果和存储在磁盘上的 Tablet 的增量版本合并到 Tablet 的最终结果中,以便新查询可以携带最新的 Tablet 版本。多版本缓存受到表类型、查询类型和数据更新类型的约束。
对多版本缓存的支持程度取决于表类型和查询类型,如下表所述。
| 表类型 | 查询 类型 | 对多版本缓存的支持 |
|---|---|---|
| Duplicate Key 表 |
|
|
| Aggregate 表 | 对基本表的查询或对同步物化视图的查询 | 除了以下情况之外,在所有情况下都支持:基表的模式包含聚合函数 replace。查询的 GROUP BY、HAVING 或 WHERE 子句引用聚合列。增量 Tablet 版本包含数据删除记录。 |
| Unique Key 表 | 不适用 | 不支持。但是,支持查询缓存。 |
| 主键表 | 不适用 | 不支持。但是,支持查询缓存。 |
数据更新类型对多版本缓存的影响如下
-
数据删除
如果 Tablet 的增量版本包含删除操作,则多版本缓存无法工作。
-
数据插入
- 如果为 Tablet 生成空版本,则查询缓存中 Tablet 的现有数据仍然有效,并且仍然可以检索。
- 如果为 Tablet 生成非空版本,则查询缓存中 Tablet 的现有数据仍然有效,但其版本滞后于 Tablet 的最新版本。在这种情况下,StarRocks 会读取从现有数据版本到 Tablet 最新版本生成的增量数据,将现有数据与增量数据合并,并将合并后的数据填充到查询缓存中。
-
架构更改和 Tablet 截断
如果更改了表的架构或截断了表的特定 Tablet,则会为该表生成新的 Tablet。因此,查询缓存中表的 Tablet 的现有数据将变为无效。
指标
查询缓存工作的查询的 Profile 包含 CacheOperator 统计信息。
在查询的源计划中,如果管道包含 OlapScanOperator,则 OlapScanOperator 和聚合算子的名称以 ML_ 为前缀,表示管道使用 MultilaneOperator 执行每个 Tablet 的计算。在 ML_CONJUGATE_AGGREGATE 之前插入 CacheOperator 以处理控制查询缓存在 Passthrough、Populate 和 Probe 模式下运行方式的逻辑。查询的 Profile 包含以下 CacheOperator 指标,可帮助您了解查询缓存的使用情况。
| 指标 | 描述 |
|---|---|
| CachePassthroughBytes | 在 Passthrough 模式下生成的字节数。 |
| CachePassthroughChunkNum | 在 Passthrough 模式下生成的 Chunk 数。 |
| CachePassthroughRowNum | 在 Passthrough 模式下生成的行数。 |
| CachePassthroughTabletNum | 在 Passthrough 模式下生成的 Tablet 数。 |
| CachePassthroughTime | 在 Passthrough 模式下花费的计算时间。 |
| CachePopulateBytes | 在 Populate 模式下生成的字节数。 |
| CachePopulateChunkNum | 在 Populate 模式下生成的 Chunk 数。 |
| CachePopulateRowNum | 在 Populate 模式下生成的行数。 |
| CachePopulateTabletNum | 在 Populate 模式下生成的 Tablet 数。 |
| CachePopulateTime | 在 Populate 模式下花费的计算时间。 |
| CacheProbeBytes | 在 Probe 模式下为缓存命中生成的字节数。 |
| CacheProbeChunkNum | 在 Probe 模式下为缓存命中生成的 Chunk 数。 |
| CacheProbeRowNum | 在 Probe 模式下为缓存命中生成的行数。 |
| CacheProbeTabletNum | 在 Probe 模式下为缓存命中生成的 Tablet 数。 |
| CacheProbeTime | 在 Probe 模式下花费的计算时间。 |
CachePopulateXXX 指标提供有关未命中查询缓存但已更新查询缓存的统计信息。
CachePassthroughXXX 指标提供有关未命中查询缓存但未更新查询缓存的统计信息,因为生成的每个 Tablet 计算结果的大小很大。
CacheProbeXXX 指标提供有关查询缓存命中的统计信息。
在多版本缓存机制中,CachePopulate 指标和 CacheProbe 指标可能包含相同的 Tablet 统计信息,CachePassthrough 指标和 CacheProbe 指标也可能包含相同的 Tablet 统计信息。例如,当 StarRocks 计算每个 Tablet 的数据时,它会命中在 Tablet 的历史版本上生成的计算结果。在这种情况下,StarRocks 会读取从历史版本到 Tablet 最新版本生成的增量数据,计算数据,并将增量数据与缓存数据合并。如果在合并后生成的计算结果的大小不超过 query_cache_entry_max_bytes 或 query_cache_entry_max_rows 参数指定的阈值,则会将 Tablet 的统计信息收集到 CachePopulate 指标中。否则,Tablet 的统计信息将收集到 CachePassthrough 指标中。
RESTful API 操作
-
metrics |grep query_cache此 API 操作用于查询与查询缓存相关的指标。
curl -s http://<be_host>:<be_http_port>/metrics |grep query_cache
# TYPE starrocks_be_query_cache_capacity gauge
starrocks_be_query_cache_capacity 536870912
# TYPE starrocks_be_query_cache_hit_count gauge
starrocks_be_query_cache_hit_count 5084393
# TYPE starrocks_be_query_cache_hit_ratio gauge
starrocks_be_query_cache_hit_ratio 0.984098
# TYPE starrocks_be_query_cache_lookup_count gauge
starrocks_be_query_cache_lookup_count 5166553
# TYPE starrocks_be_query_cache_usage gauge
starrocks_be_query_cache_usage 0
# TYPE starrocks_be_query_cache_usage_ratio gauge
starrocks_be_query_cache_usage_ratio 0.000000 -
api/query_cache/stat此 API 操作用于查询查询缓存的使用情况。
curl http://<be_host>:<be_http_port>/api/query_cache/stat
{
"capacity": 536870912,
"usage": 0,
"usage_ratio": 0.0,
"lookup_count": 5025124,
"hit_count": 4943720,
"hit_ratio": 0.983800598751394
} -
api/query_cache/invalidate_all此 API 操作用于清除查询缓存。
curl -XPUT http://<be_host>:<be_http_port>/api/query_cache/invalidate_all
{
"status": "OK"
}
上述 API 操作中的参数如下
be_host:BE 所在的节点的 IP 地址。be_http_port:BE 所在的节点的 HTTP 端口号。
注意事项
- StarRocks 需要使用首次启动的查询的计算结果填充查询缓存。因此,查询性能可能略低于预期,并且查询延迟会增加。
- 如果您配置较大的查询缓存大小,则可以提供给 BE 上查询评估的内存量会减少。我们建议查询缓存大小不要超过提供给查询评估的内存容量的 1/6。
- 如果需要处理的 Tablet 数量小于
pipeline_dop的值,则查询缓存不起作用。要使查询缓存工作,您可以将pipeline_dop设置为较小的值,例如1。从 v3.0 开始,StarRocks 会根据查询并行度自适应地调整此参数。
示例
数据集
-
登录到您的 StarRocks 集群,转到目标数据库,然后运行以下命令以创建名为
t0的表CREATE TABLE t0
(
`ts` datetime NOT NULL COMMENT "",
`k0` varchar(10) NOT NULL COMMENT "",
`k1` char(6) NOT NULL COMMENT "",
`v0` bigint(20) NOT NULL COMMENT "",
`v1` decimal64(7, 2) NOT NULL COMMENT ""
)
ENGINE=OLAP
DUPLICATE KEY(`ts`, `k0`, `k1`)
COMMENT "OLAP"
PARTITION BY RANGE(`ts`)
(
START ("2022-01-01 00:00:00") END ("2022-02-01 00:00:00") EVERY (INTERVAL 1 DAY)
)
DISTRIBUTED BY HASH(`ts`, `k0`, `k1`)
PROPERTIES
(
"replication_num" = "3",
"storage_format" = "DEFAULT",
"enable_persistent_index" = "true"
); -
将以下数据记录插入到
t0中INSERT INTO t0
VALUES
('2022-01-11 20:42:26', 'n4AGcEqYp', 'hhbawx', '799393174109549', '8029.42'),
('2022-01-27 18:17:59', 'i66lt', 'mtrtzf', '100400167', '10000.88'),
('2022-01-28 20:10:44', 'z6', 'oqkeun', '-58681382337', '59881.87'),
('2022-01-29 14:54:31', 'qQ', 'dzytua', '-19682006834', '43807.02'),
('2022-01-31 08:08:11', 'qQ', 'dzytua', '7970665929984223925', '-8947.74'),
('2022-01-15 00:40:58', '65', 'hhbawx', '4054945', '156.56'),
('2022-01-24 16:17:51', 'onqR3JsK1', 'udtmfp', '-12962', '-72127.53'),
('2022-01-01 22:36:24', 'n4AGcEqYp', 'fabnct', '-50999821', '17349.85'),
('2022-01-21 08:41:50', 'Nlpz1j3h', 'dzytua', '-60162', '287.06'),
('2022-01-30 23:44:55', '', 'slfght', '62891747919627339', '8014.98'),
('2022-01-18 19:14:28', 'z6', 'dzytua', '-1113001726', '73258.24'),
('2022-01-30 14:54:59', 'z6', 'udtmfp', '111175577438857975', '-15280.41'),
('2022-01-08 22:08:26', 'z6', 'ympyls', '3', '2.07'),
('2022-01-03 08:17:29', 'Nlpz1j3h', 'udtmfp', '-234492', '217.58'),
('2022-01-27 07:28:47', 'Pc', 'cawanm', '-1015', '-20631.50'),
('2022-01-17 14:07:47', 'Nlpz1j3h', 'lbsvqu', '2295574006197343179', '93768.75'),
('2022-01-31 14:00:12', 'onqR3JsK1', 'umlkpo', '-227', '-66199.05'),
('2022-01-05 20:31:26', '65', 'lbsvqu', '684307', '36412.49'),
('2022-01-06 00:51:34', 'z6', 'dzytua', '11700309310', '-26064.10'),
('2022-01-26 02:59:00', 'n4AGcEqYp', 'slfght', '-15320250288446', '-58003.69'),
('2022-01-05 03:26:26', 'z6', 'cawanm', '19841055192960542', '-5634.36'),
('2022-01-17 08:51:23', 'Pc', 'ghftus', '35476438804110', '13625.99'),
('2022-01-30 18:56:03', 'n4AGcEqYp', 'lbsvqu', '3303892099598', '8.37'),
('2022-01-22 14:17:18', 'i66lt', 'umlkpo', '-27653110', '-82306.25'),
('2022-01-02 10:25:01', 'qQ', 'ghftus', '-188567166', '71442.87'),
('2022-01-30 04:58:14', 'Pc', 'ympyls', '-9983', '-82071.59'),
('2022-01-05 00:16:56', '7Bh', 'hhbawx', '43712', '84762.97'),
('2022-01-25 03:25:53', '65', 'mtrtzf', '4604107', '-2434.69'),
('2022-01-27 21:09:10', '65', 'udtmfp', '476134823953365199', '38736.04'),
('2022-01-11 13:35:44', '65', 'qmwhvr', '1', '0.28'),
('2022-01-03 19:13:07', '', 'lbsvqu', '11', '-53084.04'),
('2022-01-20 02:27:25', 'i66lt', 'umlkpo', '3218824416', '-71393.20'),
('2022-01-04 04:52:36', '7Bh', 'ghftus', '-112543071', '-78377.93'),
('2022-01-27 18:27:06', 'Pc', 'umlkpo', '477', '-98060.13'),
('2022-01-04 19:40:36', '', 'udtmfp', '433677211', '-99829.94'),
('2022-01-20 23:19:58', 'Nlpz1j3h', 'udtmfp', '361394977', '-19284.18'),
('2022-01-05 02:17:56', 'Pc', 'oqkeun', '-552390906075744662', '-25267.92'),
('2022-01-02 16:14:07', '65', 'dzytua', '132', '2393.77'),
('2022-01-28 23:17:14', 'z6', 'umlkpo', '61', '-52028.57'),
('2022-01-12 08:05:44', 'qQ', 'hhbawx', '-9579605666539132', '-87801.81'),
('2022-01-31 19:48:22', 'z6', 'lbsvqu', '9883530877822', '34006.42'),
('2022-01-11 20:38:41', '', 'piszhr', '56108215256366', '-74059.80'),
('2022-01-01 04:15:17', '65', 'cawanm', '-440061829443010909', '88960.51'),
('2022-01-05 07:26:09', 'qQ', 'umlkpo', '-24889917494681901', '-23372.12'),
('2022-01-29 18:13:55', 'Nlpz1j3h', 'cawanm', '-233', '-24294.42'),
('2022-01-10 00:49:45', 'Nlpz1j3h', 'ympyls', '-2396341', '77723.88'),
('2022-01-29 08:02:58', 'n4AGcEqYp', 'slfght', '45212', '93099.78'),
('2022-01-28 08:59:21', 'onqR3JsK1', 'oqkeun', '76', '-78641.65'),
('2022-01-26 14:29:39', '7Bh', 'umlkpo', '176003552517', '-99999.96'),
('2022-01-03 18:53:37', '7Bh', 'piszhr', '3906151622605106', '55723.01'),
('2022-01-04 07:08:19', 'i66lt', 'ympyls', '-240097380835621', '-81800.87'),
('2022-01-28 14:54:17', 'Nlpz1j3h', 'slfght', '-69018069110121', '90533.64'),
('2022-01-22 07:48:53', 'Pc', 'ympyls', '22396835447981344', '-12583.39'),
('2022-01-22 07:39:29', 'Pc', 'uqkghp', '10551305', '52163.82'),
('2022-01-08 22:39:47', 'Nlpz1j3h', 'cawanm', '67905472699', '87831.30'),
('2022-01-05 14:53:34', '7Bh', 'dzytua', '-779598598706906834', '-38780.41'),
('2022-01-30 17:34:41', 'onqR3JsK1', 'oqkeun', '346687625005524', '-62475.31'),
('2022-01-29 12:14:06', '', 'qmwhvr', '3315', '22076.88'),
('2022-01-05 06:47:04', 'Nlpz1j3h', 'udtmfp', '-469', '42747.17'),
('2022-01-19 15:20:20', '7Bh', 'lbsvqu', '347317095885', '-76393.49'),
('2022-01-08 16:18:22', 'z6', 'fghmcd', '2', '90315.60'),
('2022-01-02 00:23:06', 'Pc', 'piszhr', '-3651517384168400', '58220.34'),
('2022-01-12 08:23:31', 'onqR3JsK1', 'udtmfp', '5636394870355729225', '33224.25'),
('2022-01-28 10:46:44', 'onqR3JsK1', 'oqkeun', '-28102078612755', '6469.53'),
('2022-01-23 23:16:11', 'onqR3JsK1', 'ghftus', '-707475035515433949', '63422.66'),
('2022-01-03 05:32:31', 'z6', 'hhbawx', '-45', '-49680.52'),
('2022-01-27 03:24:33', 'qQ', 'qmwhvr', '375943906057539870', '-66092.96'),
('2022-01-25 20:07:22', '7Bh', 'slfght', '1', '72440.21'),
('2022-01-04 16:07:24', 'qQ', 'uqkghp', '751213107482249', '16417.31'),
('2022-01-23 19:22:00', 'Pc', 'hhbawx', '-740731249600493', '88439.40'),
('2022-01-05 09:04:20', '7Bh', 'cawanm', '23602', '302.44');
查询示例
本节中查询缓存相关指标的统计信息是示例,仅供参考。
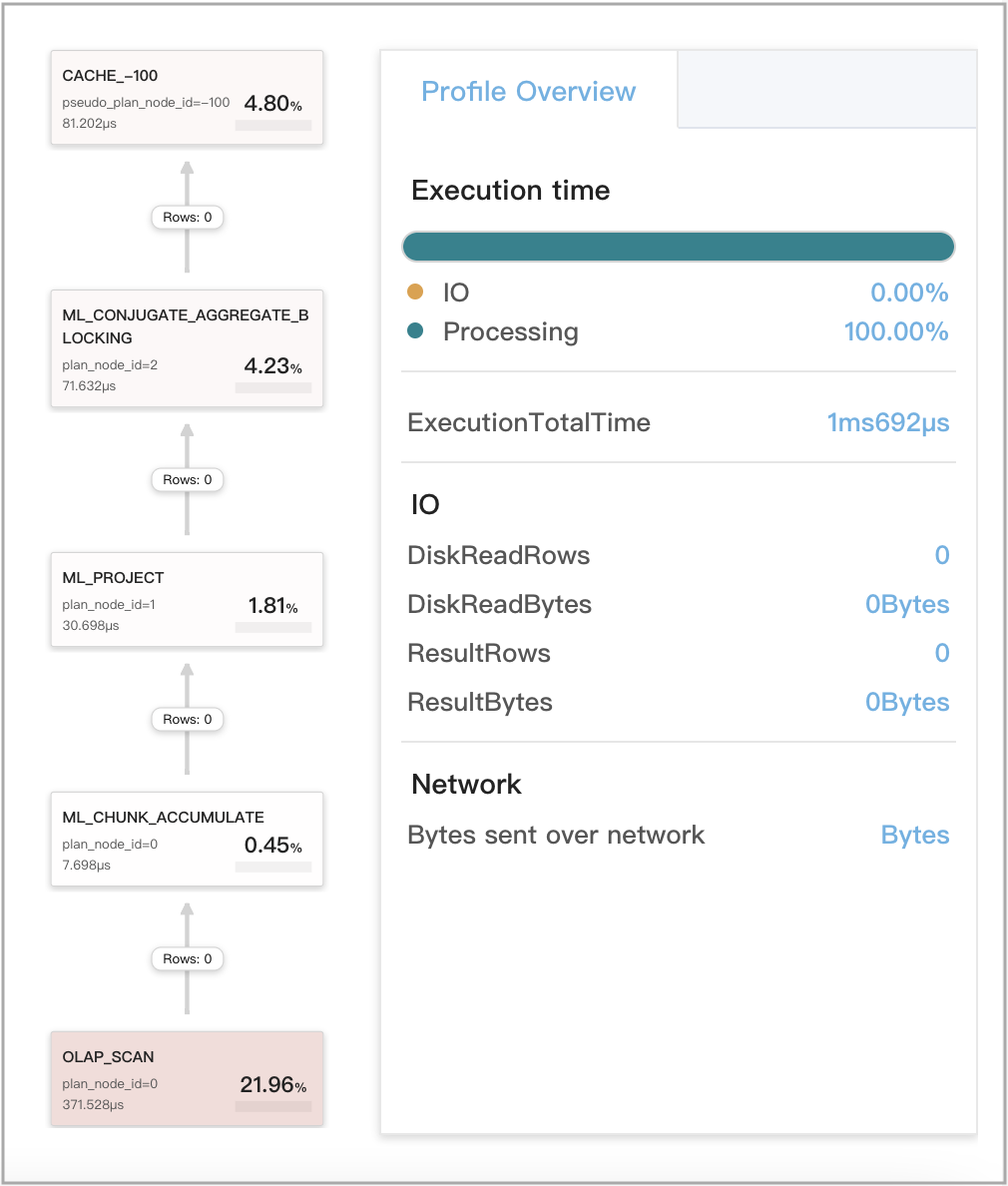
查询缓存适用于 stage 1 的本地聚合
这包括三种情况
- 查询仅访问单个 Tablet。
- 查询访问来自本身包含 Colocate Group 的表的多个分区的多个 Tablet,并且无需对聚合进行混洗数据。
- 查询访问来自表的同一分区的多个 Tablet,并且无需对聚合进行混洗数据。
查询示例
SELECT
date_trunc('hour', ts) AS hour,
k0,
sum(v1) AS __c_0
FROM
t0
WHERE
ts between '2022-01-03 00:00:00'
and '2022-01-03 23:59:59'
GROUP BY
date_trunc('hour', ts),
k0
下图显示了查询 Profile 中的查询缓存相关指标。
查询缓存不适用于 stage 1 的远程聚合
当强制在 stage 1 执行对多个 Tablet 的聚合时,会首先对数据进行混洗,然后再进行聚合。
查询示例
SET new_planner_agg_stage = 1;
SELECT
date_trunc('hour', ts) AS hour,
v0 % 2 AS is_odd,
sum(v1) AS __c_0
FROM
t0
WHERE
ts between '2022-01-03 00:00:00'
and '2022-01-03 23:59:59'
GROUP BY
date_trunc('hour', ts),
is_odd
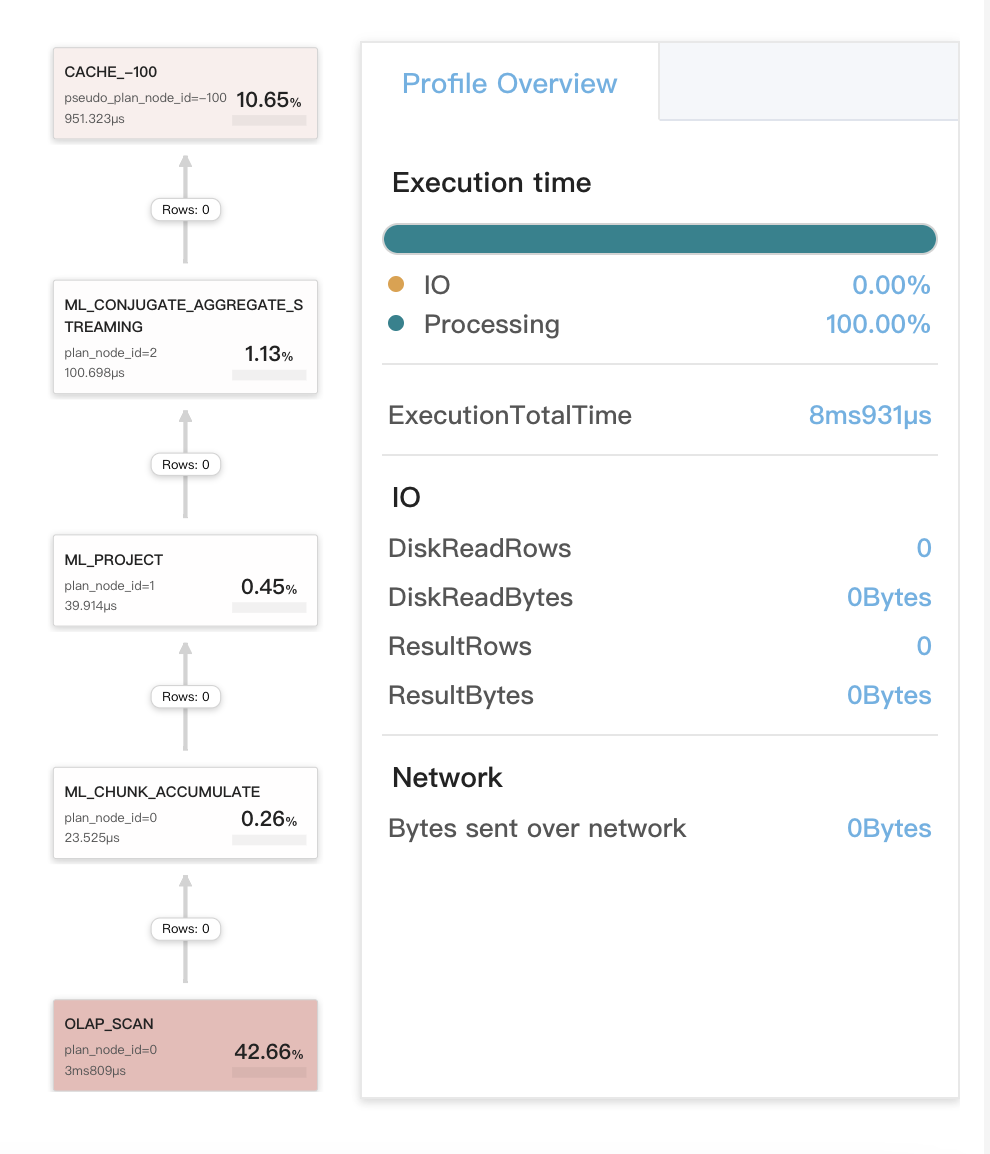
查询缓存适用于 stage 2 的本地聚合
这包括三种情况
- 查询的 stage 2 的聚合被编译为比较相同类型的数据。第一个聚合是本地聚合。在第一个聚合完成后,会计算从第一个聚合生成的结果以执行第二个聚合,这是一个全局聚合。
- 查询是 SELECT DISTINCT 查询。
- 查询包括以下 DISTINCT 聚合函数之一:
sum(distinct)、count(distinct)和avg(distinct)。在大多数情况下,对于此类查询,聚合是在 stage 3 或 4 中执行的。但是,您可以运行set new_planner_agg_stage = 1以强制在查询的 stage 2 中执行聚合。如果查询包含avg(distinct)并且您想要在 stage 中执行聚合,则还需要运行set cbo_cte_reuse = false以禁用 CTE 优化。
查询示例
SELECT
date_trunc('hour', ts) AS hour,
v0 % 2 AS is_odd,
sum(v1) AS __c_0
FROM
t0
WHERE
ts between '2022-01-03 00:00:00'
and '2022-01-03 23:59:59'
GROUP BY
date_trunc('hour', ts),
is_odd
下图显示了查询 Profile 中的查询缓存相关指标。
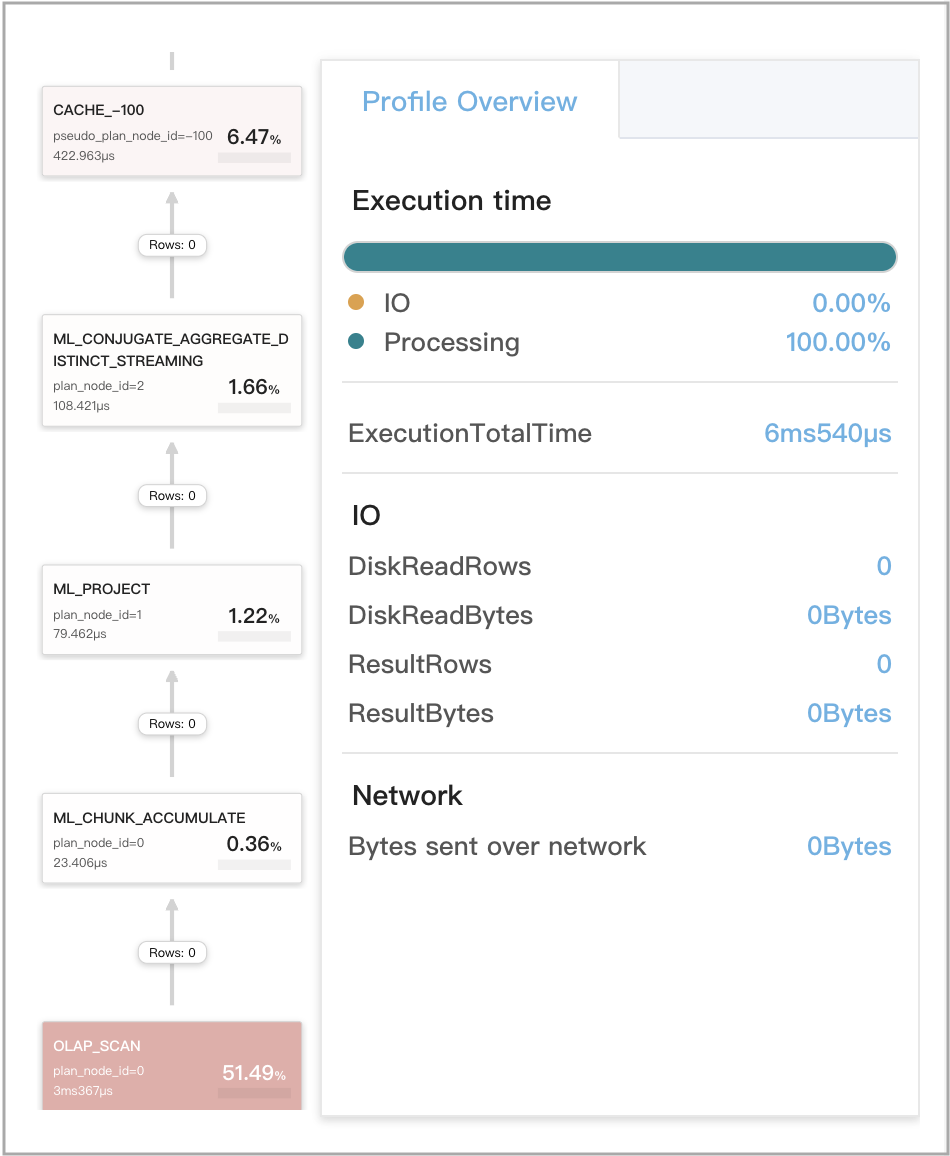
查询缓存适用于 stage 3 的本地聚合
查询是 GROUP BY 聚合查询,其中包括单个 DISTINCT 聚合函数。
支持的 DISTINCT 聚合函数是 sum(distinct)、count(distinct) 和 avg(distinct)。
注意
如果查询包含
avg(distinct),则还需要运行set cbo_cte_reuse = false以禁用 CTE 优化。
查询示例
SELECT
date_trunc('hour', ts) AS hour,
v0 % 2 AS is_odd,
sum(distinct v1) AS __c_0
FROM
t0
WHERE
ts between '2022-01-03 00:00:00'
and '2022-01-03 23:59:59'
GROUP BY
date_trunc('hour', ts),
is_odd;
下图显示了查询 Profile 中的查询缓存相关指标。
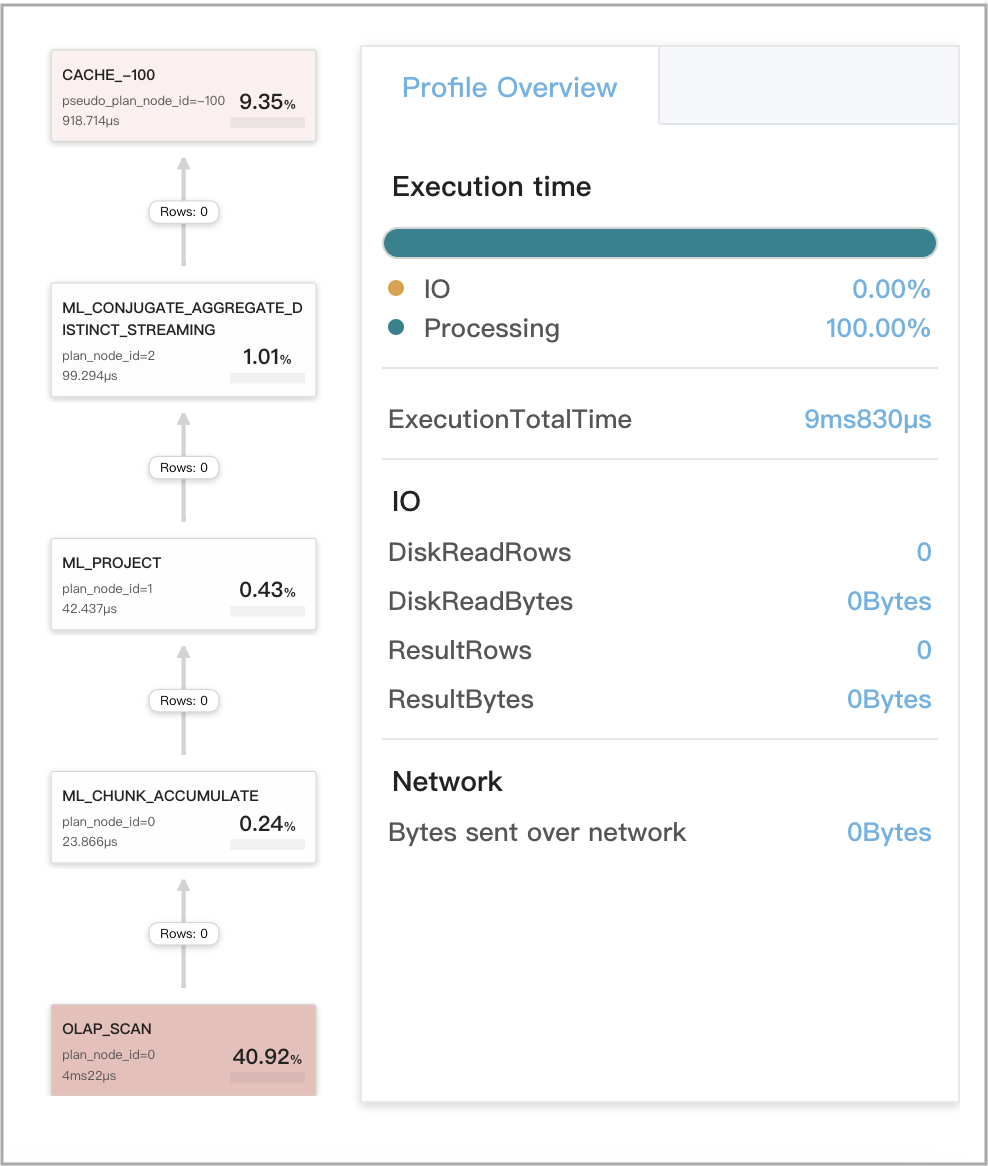
查询缓存适用于第 4 阶段的本地聚合
该查询是一个非 GROUP BY 聚合查询,包含一个 DISTINCT 聚合函数。此类查询包括删除重复数据的经典查询。
查询示例
SELECT
count(distinct v1) AS __c_0
FROM
t0
WHERE
ts between '2022-01-03 00:00:00'
and '2022-01-03 23:59:59'
下图显示了查询 Profile 中的查询缓存相关指标。
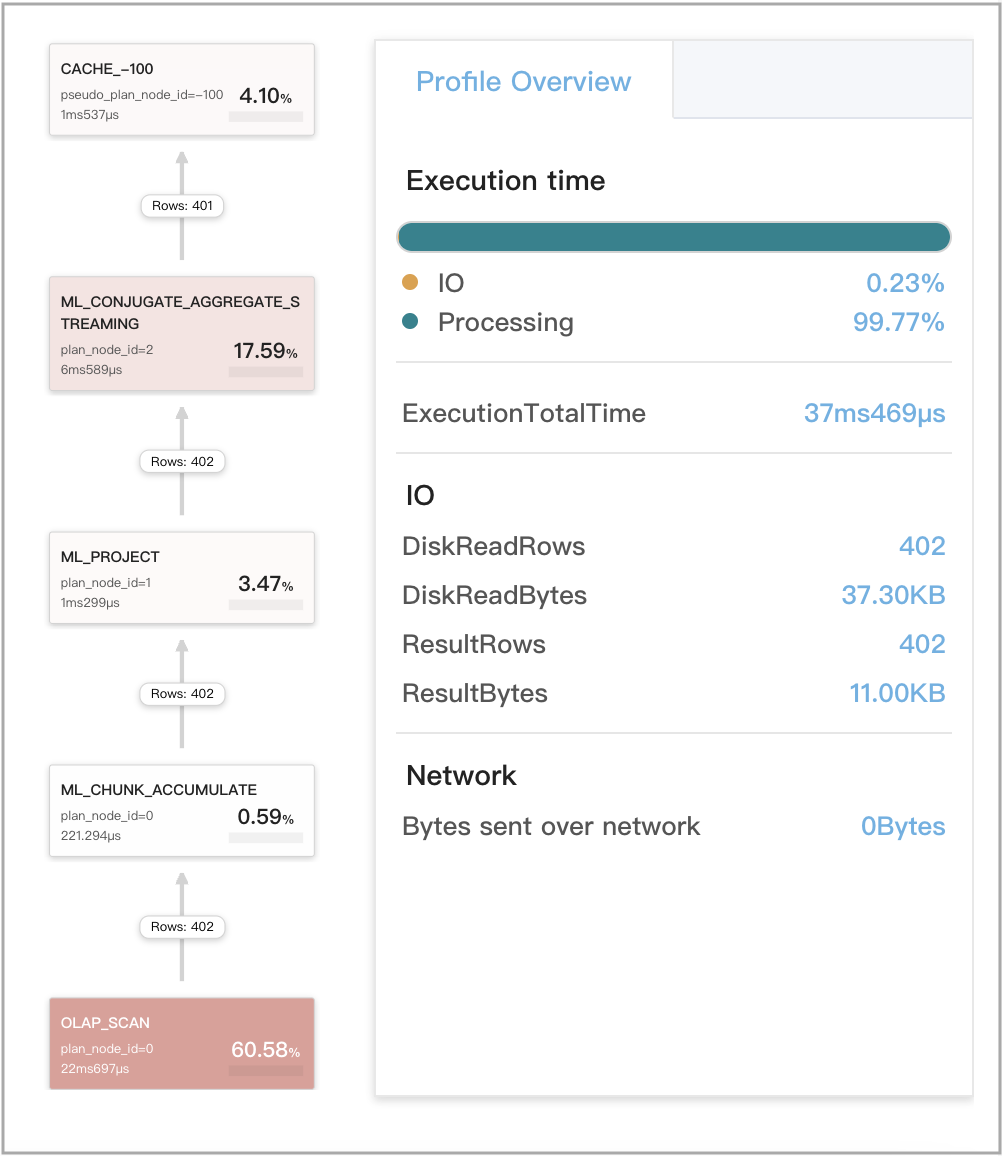
缓存结果可以被两个语义等效的首次聚合查询重用
使用以下两个查询 Q1 和 Q2 作为示例。Q1 和 Q2 都包含多个聚合,但它们的首次聚合在语义上是等效的。因此,Q1 和 Q2 被评估为语义等效,并且可以重用彼此保存在查询缓存中的计算结果。
-
Q1
SELECT
(
ifnull(sum(murmur_hash3_32(hour)), 0) + ifnull(sum(murmur_hash3_32(k0)), 0) + ifnull(sum(murmur_hash3_32(__c_0)), 0)
) AS fingerprint
FROM
(
SELECT
date_trunc('hour', ts) AS hour,
k0,
sum(v1) AS __c_0
FROM
t0
WHERE
ts between '2022-01-03 00:00:00'
and '2022-01-03 23:59:59'
GROUP BY
date_trunc('hour', ts),
k0
) AS t; -
Q2
SELECT
date_trunc('hour', ts) AS hour,
k0,
sum(v1) AS __c_0
FROM
t0
WHERE
ts between '2022-01-03 00:00:00'
and '2022-01-03 23:59:59'
GROUP BY
date_trunc('hour', ts),
k0
下图显示了 Q1 的 CachePopulate 指标。
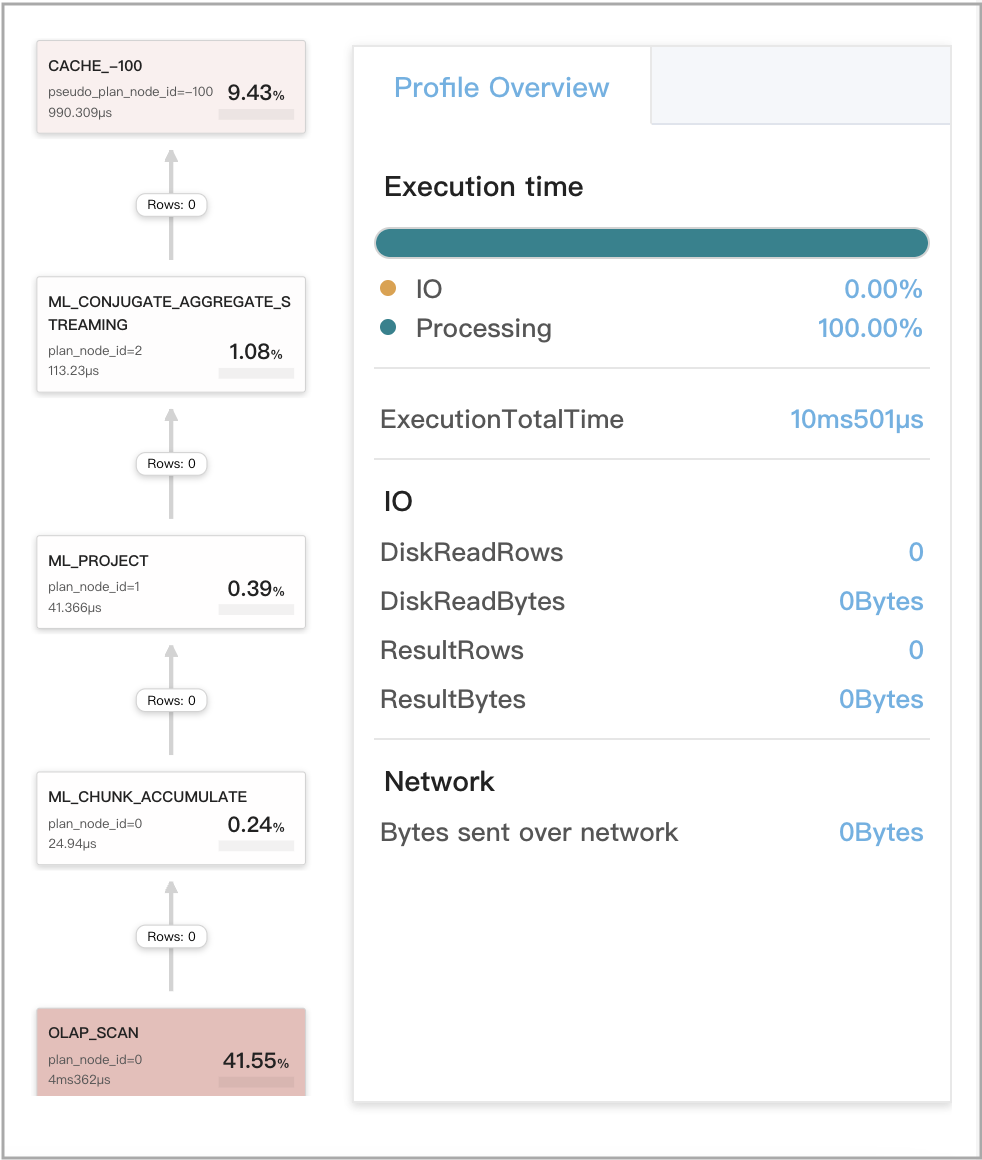
下图显示了 Q2 的 CacheProbe 指标。
对于启用了 CTE 优化的 DISTINCT 查询,查询缓存不起作用
运行 set cbo_cte_reuse = true 以启用 CTE 优化后,包含 DISTINCT 聚合函数的特定查询的计算结果将无法被缓存。以下是一些示例:
-
查询包含单个 DISTINCT 聚合函数
avg(distinct)SELECT
avg(distinct v1) AS __c_0
FROM
t0
WHERE
ts between '2022-01-03 00:00:00'
and '2022-01-03 23:59:59';
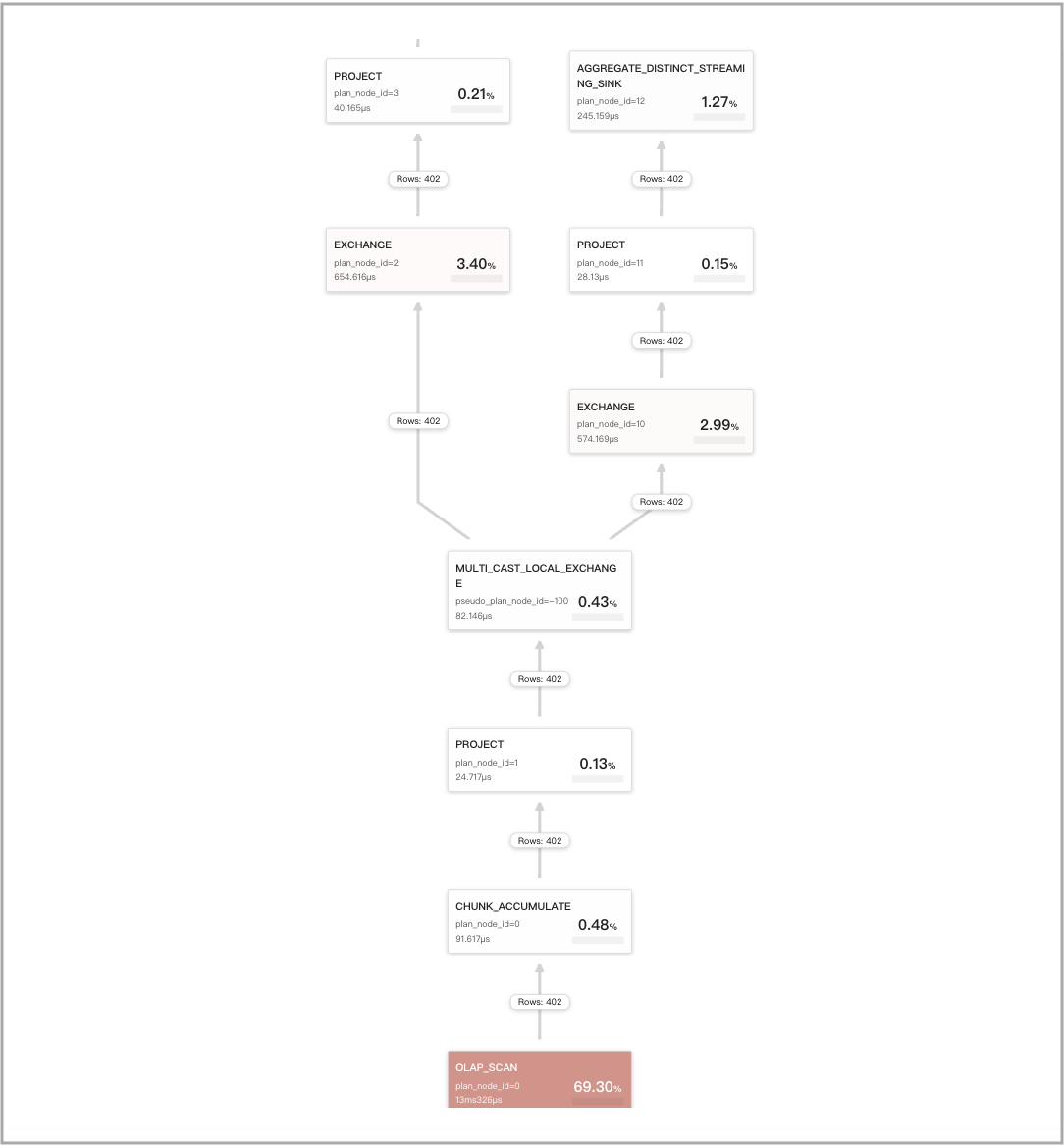
-
查询包含引用同一列的多个 DISTINCT 聚合函数
SELECT
avg(distinct v1) AS __c_0,
sum(distinct v1) AS __c_1,
count(distinct v1) AS __c_2
FROM
t0
WHERE
ts between '2022-01-03 00:00:00'
and '2022-01-03 23:59:59';

-
查询包含各自引用不同列的多个 DISTINCT 聚合函数
SELECT
sum(distinct v1) AS __c_1,
count(distinct v0) AS __c_2
FROM
t0
WHERE
ts between '2022-01-03 00:00:00'
and '2022-01-03 23:59:59';

最佳实践
创建表时,指定合理的分区描述和合理的分布方式,包括
- 选择单个 DATE 类型列作为分区列。如果表包含多个 DATE 类型列,请选择其值随数据增量摄取而向前滚动的列,并用于定义您感兴趣的查询时间范围。
- 选择适当的分区宽度。最近摄取的数据可能会修改表的最新分区。因此,涉及最新分区的缓存条目不稳定,容易失效。
- 在表创建语句的分布描述中指定几十个存储桶数。如果存储桶数过小,当 BE 需要处理的 Tablet 数量小于
pipeline_dop的值时,查询缓存将无法生效。