使用物化视图进行数据建模
本主题介绍如何借助 StarRocks 的异步物化视图执行数据建模。 这样做可以大大简化数据仓库的 ETL 流程,并显着提高数据质量和查询性能。
概述
数据建模是使用合理的方法对数据进行清理、分层、聚合和关联的过程。 它可以创建原始数据的可理解表示,这些数据过于粗糙、过于复杂或分析成本过高,并提供对数据的可行见解。
然而,现实世界中数据建模的常见挑战是建模过程难以跟上业务发展的步伐,并且难以衡量数据建模工作的投资回报率。 尽管建模方法很简单,但业务专家需要具备扎实的数据组织和治理背景,这是一个复杂的过程。 在业务的早期阶段,决策者很少为数据建模投入足够的资源,并且难以看到数据建模可以带来的价值。 此外,业务模型可能会快速变化,建模方法本身也需要迭代和发展。 因此,许多数据分析师倾向于避免建模而直接使用原始数据,这不可避免地导致数据质量和查询性能问题。 当需要建模时,很难重组已经建立的数据分析模式以匹配数据模型。
使用物化视图进行数据建模可以有效解决这些问题。 StarRocks 的异步物化视图可以
- 简化数据仓库架构:因为 StarRocks 可以提供一站式数据治理体验,所以您无需维护其他数据处理系统,从而节省花费在它们上面的人力和系统资源。
- 简化数据建模体验:任何只有基本 SQL 知识的数据分析师都能够使用 StarRocks 进行数据建模。 数据建模不再是经验丰富的数据工程师的专属领域。
- 降低维护复杂性:StarRocks 的异步物化视图可以自动管理数据层之间的沿袭关系和依赖关系,无需整个数据平台来处理此任务。
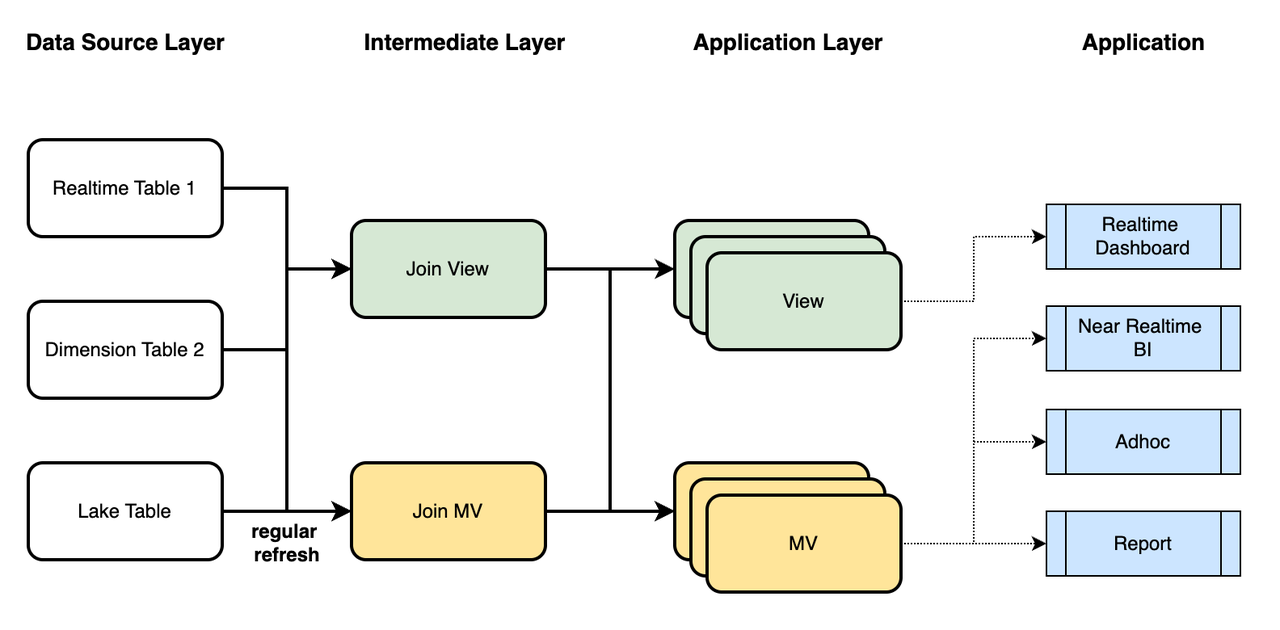
在实际情况中,您可以通过结合使用 StarRocks 的视图(逻辑视图)和异步物化视图来执行数据建模,如下所示
- 使用视图将实时数据与维度数据关联,并使用物化视图将数据湖中的历史数据与维度数据关联。 执行必要的数据清理和语义映射,以获取中间层的详细数据,该数据反映了您的业务场景中所需的语义。
- 在应用层中,执行针对不同业务场景量身定制的数据 Join、聚合、Union 和 Window 计算。 这将产生用于实时管道的视图和用于近实时管道的物化视图。
- 在应用端,根据您的及时性和性能要求,选择合适的分析数据存储 (ADS) 进行查询分析。 这些 ADS 可以服务于实时仪表板、近实时 BI、即席查询和计划报告。
在此过程中,您将利用 StarRocks 的几个内置功能,这些功能将在下一节中详细介绍。
异步物化视图的功能
StarRocks 的异步物化视图具有以下原子功能,可以帮助进行数据建模
- 自动刷新:将数据加载到基表后,可以自动刷新物化视图。 您无需在外部维护调度任务。
- 分区刷新:可以通过基于具有时间序列的表构建的物化视图的分区刷新来实现近实时计算。
- 与视图的协同作用:您可以通过使用物化视图和逻辑视图来实现多层建模,从而实现中间层的重用并简化数据模型。
- 模式更改:您可以通过简单的 SQL 语句更改计算结果,而无需修改复杂的数据管道。
借助这些功能,您可以设计全面且适应性强的数据模型,以满足各种业务需求和场景。
自动刷新
创建异步物化视图时,可以使用 REFRESH 子句指定刷新策略。 目前,StarRocks 支持异步物化视图的以下刷新策略
- 自动刷新 (
REFRESH ASYNC):每次基表中的数据发生更改时,都会触发刷新任务。 数据依赖关系由物化视图自动管理。 - 计划刷新 (
REFRESH ASYNC EVERY (INTERVAL <refresh_interval>)):刷新任务以固定的时间间隔触发,例如,每分钟、每天或每月。 如果基表中没有数据更改,则不会触发刷新任务。 - 手动刷新 (
REFRESH MANUAL):仅通过手动执行 REFRESH MATERIALIZED VIEW 触发刷新任务。 当您维护外部调度框架来触发刷新任务时,可以使用此刷新策略。
语法
CREATE MATERIALIZED VIEW <name>
REFRESH
[ ASYNC |
ASYNC [START <time>] EVERY(<interval>) |
MANUAL
]
AS <query>
分区刷新
创建异步物化视图时,可以使用 PARTITION BY 子句将基表的分区与物化视图的分区关联起来,从而实现分区级别的刷新。
PARTITION BY <column>:您可以为基表和物化视图引用相同的分区列。 结果,基表和物化视图以相同的粒度进行分区。PARTITION BY date_trunc(<column>):您可以使用 date_trunc 函数通过截断时间单位来为物化视图分配不同的分区策略(在粒度级别上)。PARTITION BY { time_slice | date_slice }(<column>):与 date_trunc 相比,time_slice 和 date_slice 提供了更灵活的时间粒度调整,可以更精细地控制基于时间的分区。
语法
CREATE MATERIALIZED VIEW <name>
REFRESH ASYNC
PARTITION BY
[
<base_table_column> |
date_trunc(<granularity>, <base_table_column>) |
time_slice(<base_table_column>, <granularity>) |
date_slice(<base_table_column>, <granularity>)
]
AS <query>
与视图的协同作用
- 可以基于视图创建物化视图。 在这种情况下,当视图引用的基表发生数据更改时,可以自动刷新物化视图。
- 您还可以基于其他物化视图创建物化视图,从而实现多级级联刷新机制。
- 可以基于物化视图创建视图,这等同于常规表。
模式更改
- 您可以使用 ALTER MATERIALIZED VIEW SWAP 语句在两个异步物化视图之间执行原子交换。 这使您可以创建一个具有添加的列或更改的列类型的新物化视图,然后用它替换旧的物化视图。
- 可以使用 ALTER VIEW 语句直接修改视图的定义。
- 可以使用 SWAP 或 ALTER 操作修改 StarRocks 中的常规表。
- 此外,当基表(可以是物化视图、视图或常规表)发生更改时,它会触发相应物化视图中的级联更改。
分层建模
在许多实际业务场景中,存在各种形式的数据源,包括实时详细数据、维度数据和来自数据湖的历史数据。 另一方面,业务需求需要各种分析方法,例如实时仪表板、近实时 BI 查询、即席查询和计划报告。 不同的场景有不同的需求——有些需要灵活性,有些优先考虑性能,而另一些则强调成本效益。
显然,单一的解决方案无法充分满足如此多样化的需求。 StarRocks 可以通过结合使用视图和物化视图来有效地满足这些需求。 由于视图不维护物理数据,因此每次查询视图时,都会根据视图的定义解析和执行查询。 相比之下,物化视图保存了预先计算的结果,可以避免重复执行的开销。 视图适用于表达业务语义和简化 SQL 的复杂性,但它们不能降低查询执行的成本。 另一方面,物化视图通过预先计算来优化查询性能,并且适用于简化 ETL 管道。
以下是视图和物化视图之间差异的总结
| 视图 | 物化视图 | |
|---|---|---|
| 使用案例 | 业务建模、数据治理 | 数据建模、透明加速、数据湖集成 |
| 存储成本 | 无存储成本 | 存储预先计算的结果会产生存储成本 |
| 更新成本 | 无更新成本 | 基表数据更新时产生刷新成本 |
| 性能优势 | 无性能优势 | 重用预先计算的结果带来的查询加速 |
| 数据实时属性 | 因为对视图的查询是实时计算的,所以返回的是最新数据。 | 数据可能不是最新的,因为结果是预先计算的。 |
| 依赖关系 | 如果基表名称已更改,则视图将失效,因为它们按名称引用基表。 | 基表名称的更改不会影响物化视图的可用性,因为物化视图按 ID 引用基表。 |
| 创建语法 | CREATE VIEW | CREATE MATERIALIZED VIEW |
| 修改语法 | ALTER VIEW | ALTER MATERIALIZED VIEW |
您可以使用以下语句修改您的视图、物化视图和基表
-- Modify a table.
ALTER TABLE <table_name> ADD COLUMN <column_desc>;
-- Swap two tables.
ALTER TABLE <table1> SWAP WITH <table2>;
-- Modify the definition of a view.
ALTER VIEW <view_name> AS <query>;
-- Swap two materialized views
-- (by swapping the name of the two materialized views without affecting the data within).
ALTER MATERIALIZED VIEW <mv1> SWAP WITH <mv2>;
-- Re-activate a materialized view.
ALTER MATERIALIZED VIEW <mv_name> ACTIVE;
模式更改遵循以下原则
- 对表执行重命名和交换操作会将依赖的物化视图设置为非活动状态。 对于模式更改操作,仅当对物化视图引用的基表列执行模式更改操作时,才会将依赖的物化视图设置为非活动状态。
- 如果您更改视图的定义,则依赖的物化视图将设置为非活动状态。
- 如果物化视图被交换,则任何基于它构建的嵌套物化视图都会被设置为非活动状态。
- 非活动状态会向上级联,直到没有物化视图依赖关系为止。
- 非活动物化视图无法刷新或用于自动查询重写。
- 仍然可以直接查询非活动物化视图,但在再次激活之前无法保证数据一致性。
虽然无法保证非活动物化视图的数据一致性,但您可以使用以下方法恢复它们的功能
- 手动激活:您可以通过执行
ALTER MATERIALIZED VIEW <mv_name> ACTIVE手动修复非活动物化视图。 此语句将根据其原始 SQL 定义重新创建物化视图。 请注意,SQL 定义在底层模式更改之后必须仍然有效。 否则,操作将失败。 - 刷新前激活:StarRocks 会尝试在刷新非活动物化视图之前将其激活。
- 自动激活:StarRocks 将尝试自动激活非活动物化视图。 但是,无法保证此过程的及时性。 您可以通过执行
ADMIN SET FRONTEND CONFIG('enable_mv_automatic_active_check'='false')来禁用此功能。 此功能从 v3.1.4 和 v3.2.0 开始可用。
分区建模
除了分层建模之外,分区建模也是数据建模的一个重要方面。 数据建模通常涉及基于业务语义关联数据,并根据及时性要求设置数据的生存时间 (TTL)。 分区建模在此过程中起着重要作用。
分区建模是数据建模的一个重要方面,是对分层建模的补充。 它涉及基于业务语义关联数据,并根据及时性要求设置数据的生存时间 (TTL)。 数据分区在此过程中起着重要作用。
不同的数据关联方式会产生各种建模方法,例如星型模式和雪花模式。 这些模型有一个共同点——它们都使用事实表和维度表。 一些业务场景需要多个大型事实表,而另一些则处理复杂的维度表以及它们之间的关系。 StarRocks 的物化视图支持事实表的分区关联,这意味着事实表被分区,并且物化视图的连接结果以相同的方式分区。
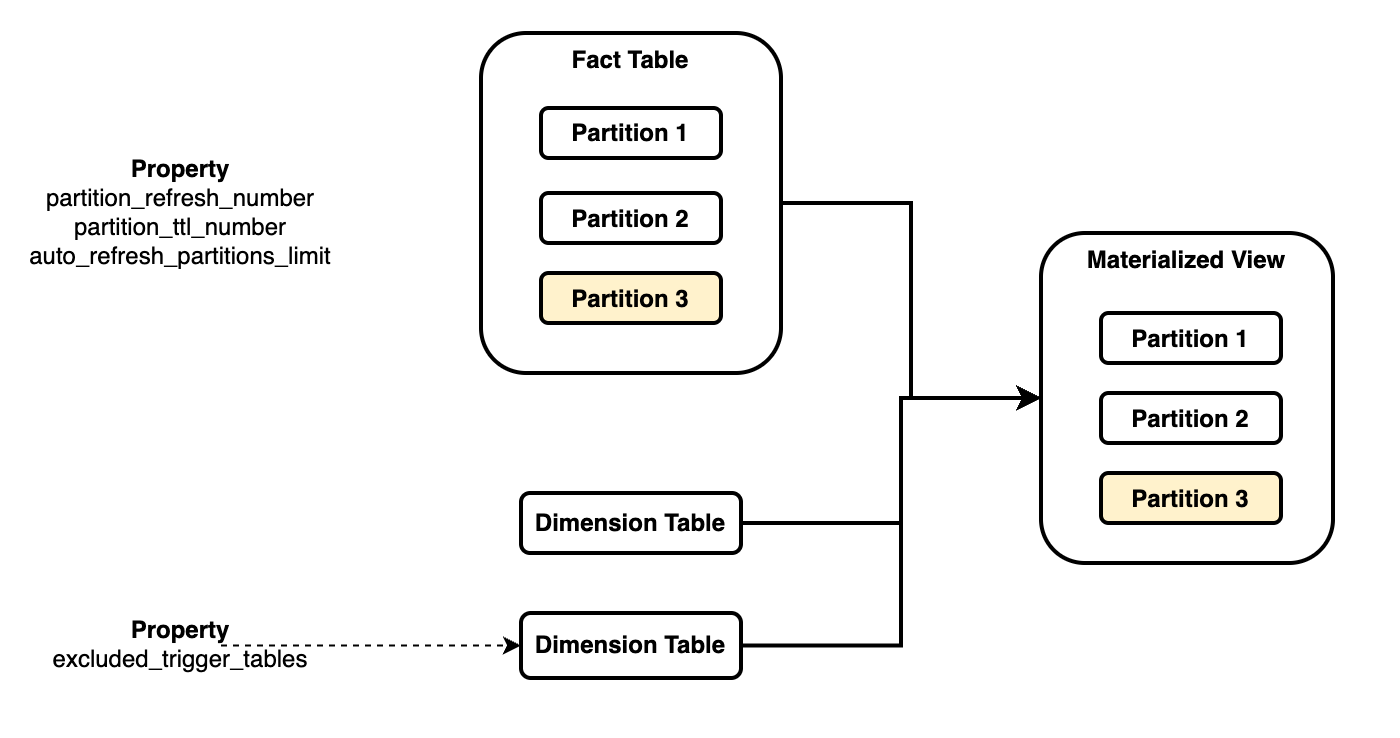
如上图所示,物化视图将事实表与多个维度表关联起来
- 您需要引用特定基表(通常是事实表)的分区键作为物化视图的分区键 (
PARTITION BY fact_tbl.col) 以关联它们的分区策略。 每个物化视图只能与一个基表关联。 - 当引用表中某个分区的数据发生更改时,将刷新物化视图中的相应分区,而不会影响其他分区。
- 当未引用表中的数据发生更改时,默认情况下会刷新整个物化视图。 但是,您可以选择忽略某些未引用基表中的数据更改,以便在这些表中的数据发生更改时不会刷新物化视图。
这种分区关联支持各种业务场景
- 事实表更新:您可以以细粒度级别(例如每天或每小时)对事实表进行分区。 更新事实表后,将自动刷新物化视图中的相应分区。
- 维度表更新:通常,维度表中的数据更新将导致刷新所有关联的结果,这可能会很昂贵。 您可以选择忽略某些维度表中的数据更新以避免刷新整个物化视图,或者您可以指定一个时间范围,以便仅刷新该时间范围内的分区。
- 外部表自动刷新:在 Apache Hive 或 Apache Iceberg 等外部数据源中,数据会在分区级别发生更改。 StarRocks 的物化视图可以订阅外部目录中分区级别的更改,并且仅刷新物化视图的相应分区。
- TTL:在为物化视图设置分区策略时,您可以设置要保留的最近分区数,从而仅保留最新的数据。 这在业务场景中很有用,因为分析师只会查询某个时间窗口中的最新数据,而他们不需要保留所有历史数据。
可以使用几个参数来控制刷新行为
partition_refresh_number:每次刷新操作要刷新的分区数。partition_ttl_number:要保留的最近分区数。excluded_trigger_tables:可以忽略其数据更改以避免触发自动刷新的表。auto_refresh_partitions_limit:每次自动刷新操作要刷新的分区数。excluded_refresh_tables:排除需要刷新的表,通常与excluded_trigger_tables一起使用。
有关更多信息,请参见 CREATE MATERIALIZED VIEW。
目前,分区物化视图具有以下限制
- 您只能基于分区表构建分区物化视图。
- 您只能使用 DATE 或 DATETIME 类型的列作为分区键。 不支持 STRING 数据类型。
- 您只能使用 date_trunc、time_slice 和 date_slice 函数执行分区汇总。
- 您只能指定单个列作为分区键。 不支持多个分区列。
摘要
利用 StarRocks 的异步物化视图进行数据建模的优势在于,可以通过声明式建模语言简化管道管理并提高数据建模的效率和灵活性。
除了数据建模之外,StarRocks 的异步物化视图还应用于涉及透明加速和数据湖集成的各种场景。 这有助于进一步探索数据价值并提高数据效率。