创建分区物化视图
本主题介绍如何创建分区物化视图以适应不同的用例。
概述
StarRocks 的异步物化视图支持多种分区策略和函数,使您能够实现以下效果
-
增量构建
创建分区物化视图时,您可以将创建任务设置为分批刷新分区,以避免过多的资源消耗。
-
增量刷新
您可以设置刷新任务,使其仅在检测到基表的某些分区中的数据更改时才更新物化视图的相应分区。分区级刷新可以显著防止用于刷新整个物化视图的资源浪费。
-
部分物化
您可以为物化视图分区设置 TTL,从而允许数据的部分物化。
-
透明查询重写
查询可以仅基于那些已更新的物化视图分区进行透明重写。被认为过时的分区将不会参与查询计划,并且查询将在基本表上执行,以保证数据的一致性。
局限性
只能在分区基表(通常是事实表)上创建分区物化视图。只有通过映射基表和物化视图之间的分区关系,才能构建它们之间的协同作用。
目前,StarRocks 支持从以下数据源的表构建分区物化视图
- 默认目录中的 StarRocks OLAP 表
- 支持的分区策略:范围分区
- 分区键支持的数据类型:INT、DATE、DATETIME 和 STRING
- 支持的表类型:主键、Duplicate Key、Aggregate Key 和 Unique Key
- 共享存储和共享数据集群均支持
- Hive Catalog、Hudi Catalog、Iceberg Catalog 和 Paimon Catalog 中的表
- 支持的分区级别:主级别
- 分区键支持的数据类型:INT、DATE、DATETIME 和 STRING
- 您不能基于非分区的基表(事实表)创建分区物化视图。
- 对于 StarRocks OLAP 表
- 目前,不支持列表分区和表达式分区。
- 基表的两个相邻分区必须具有连续的范围。
- 对于外部目录中的多级分区基表,只能使用主级别分区路径创建分区物化视图。例如,对于以
yyyyMMdd/hour格式分区的表,您只能构建按yyyyMMdd分区的物化视图。 - 从 v3.2.3 开始,StarRocks 支持基于具有 Partition Transforms 的 Iceberg 表创建分区物化视图,并且物化视图按转换后的列进行分区。有关更多信息,请参见 [使用物化视图加速数据湖查询 - 选择合适的data_lake_query_acceleration_with_materialized_views.mdterialized_views.md#choose-a-suitable-refresh-strategy)。
用例
假设有以下基表
CREATE TABLE IF NOT EXISTS par_tbl1 (
datekey DATE, -- DATE type date column used as the Partitioning Key.
k1 STRING,
v1 INT,
v2 INT
)
ENGINE=olap
PARTITION BY RANGE (datekey) (
START ("2021-01-01") END ("2021-01-04") EVERY (INTERVAL 1 DAY)
)
DISTRIBUTED BY HASH(k1);
CREATE TABLE IF NOT EXISTS par_tbl2 (
datekey STRING, -- STRING type date column used as the Partitioning Key.
k1 STRING,
v1 INT,
v2 INT
)
ENGINE=olap
PARTITION BY RANGE (str2date(datekey, '%Y-%m-%d')) (
START ("2021-01-01") END ("2021-01-04") EVERY (INTERVAL 1 DAY)
)
DISTRIBUTED BY HASH(k1);
CREATE TABLE IF NOT EXISTS par_tbl3 (
datekey_new DATE, -- Equivalent column with par_tbl1.datekey.
k1 STRING,
v1 INT,
v2 INT
)
ENGINE=olap
PARTITION BY RANGE (datekey_new) (
START ("2021-01-01") END ("2021-01-04") EVERY (INTERVAL 1 DAY)
)
DISTRIBUTED BY HASH(k1);
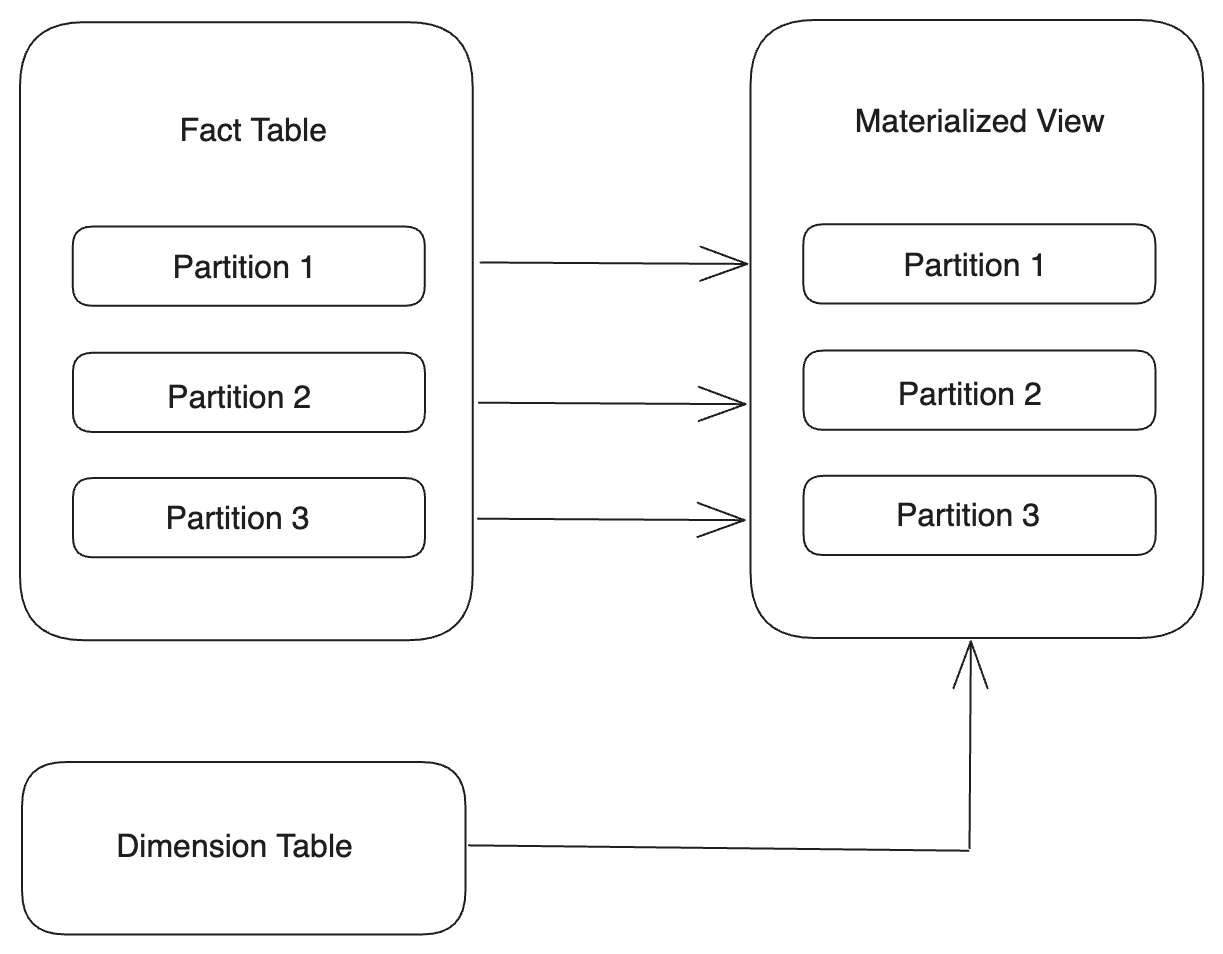
一对一匹配分区
您可以通过使用相同的分区键来创建一个物化视图,其分区与基表的分区一一对应。
-
如果基表的分区键是 DATE 或 DATETIME 类型,则可以直接为物化视图指定相同的分区键。
PARTITION BY <base_table_partitioning_column>示例
CREATE MATERIALIZED VIEW par_mv1
REFRESH ASYNC
PARTITION BY datekey
AS
SELECT
k1,
sum(v1) AS SUM,
datekey
FROM par_tbl1
GROUP BY datekey, k1; -
如果基表的分区键是 STRING 类型,则可以使用 str2date 函数将日期字符串转换为 DATE 或 DATETIME 类型。
PARTITION BY str2date(<base_table_partitioning_column>, <format>)示例
CREATE MATERIALIZED VIEW par_mv2
REFRESH ASYNC
PARTITION BY str2date(datekey, '%Y-%m-%d')
AS
SELECT
k1,
sum(v1) AS SUM,
datekey
FROM par_tbl2
GROUP BY datekey, k1;
按时间粒度汇总分区
您可以通过在分区键上使用 date_trunc 函数来创建一个分区粒度大于基表的分区粒度的物化视图。当检测到基表分区中的数据更改时,StarRocks 会刷新物化视图中的相应汇总分区。
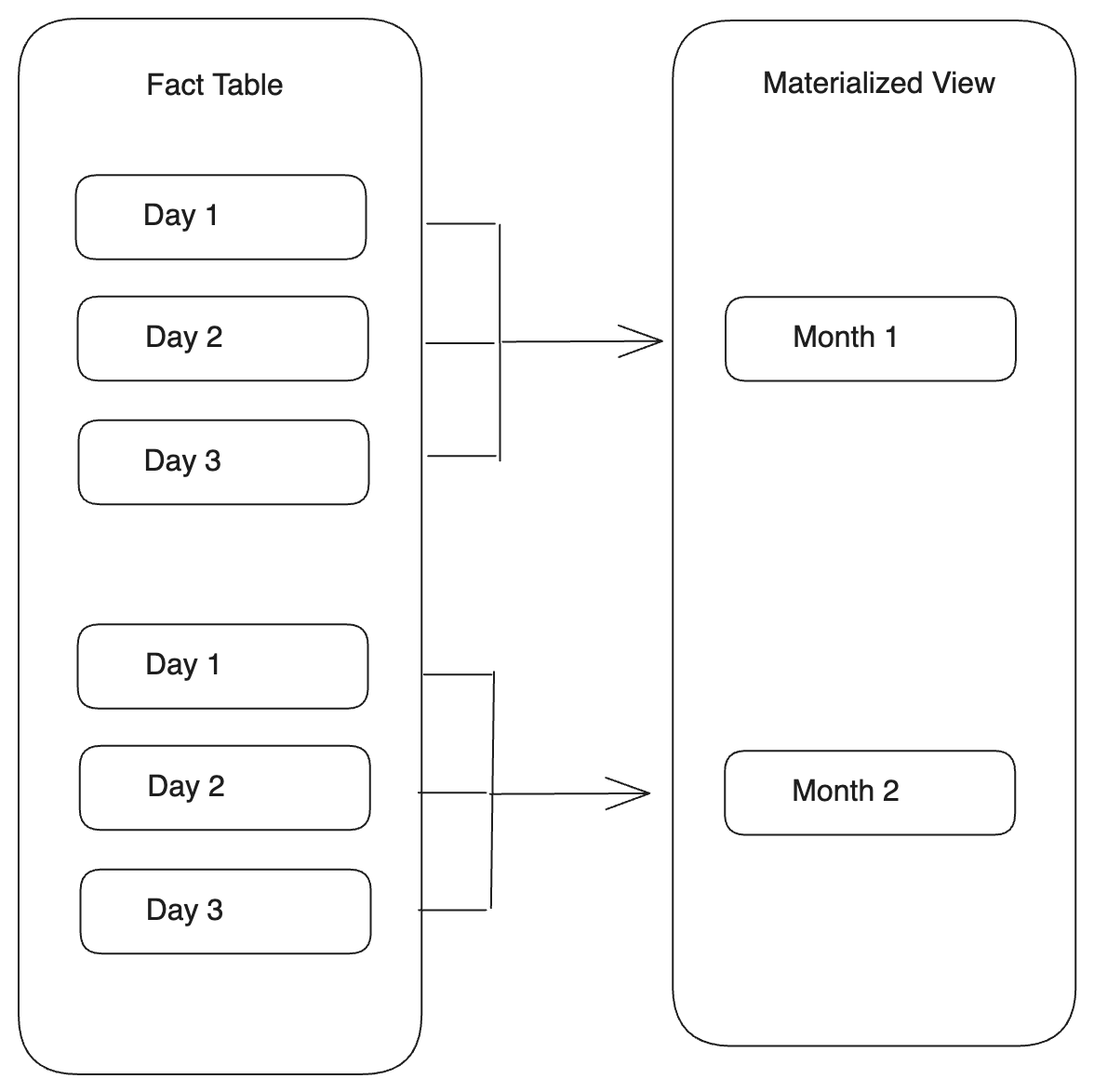
-
如果基表的分区键是 DATE 或 DATETIME 类型,则可以直接在基表的分区键上使用 date_trunc 函数。
PARTITION BY date_trunc(<format>, <base_table_partitioning_column>)示例
CREATE MATERIALIZED VIEW par_mv3
REFRESH ASYNC
PARTITION BY date_trunc('month', datekey)
AS
SELECT
k1,
sum(v1) AS SUM,
datekey
FROM par_tbl1
GROUP BY datekey, k1; -
如果基表的分区键是 STRING 类型,则必须在 SELECT 列表中将基表的分区键转换为 DATE 或 DATETIME 类型,为其设置别名,并在 date_trunc 函数中使用它来指定物化视图的分区键。
PARTITION BY
date_trunc(<format>, <mv_partitioning_column>)
AS
SELECT
str2date(<base_table_partitioning_column>, <format>) AS <mv_partitioning_column>示例
CREATE MATERIALIZED VIEW par_mv4
REFRESH ASYNC
PARTITION BY date_trunc('month', mv_datekey)
AS
SELECT
datekey,
k1,
sum(v1) AS SUM,
str2date(datekey, '%Y-%m-%d') AS mv_datekey
FROM par_tbl2
GROUP BY datekey, k1;
以自定义时间粒度对齐分区
上述分区汇总方法仅允许基于特定时间粒度对物化视图进行分区,并且不允许自定义分区时间范围。如果您的业务场景需要使用自定义时间粒度进行分区,您可以创建一个物化视图,并通过将 date_trunc 函数与 time_slice 函数结合使用来定义其分区的时间粒度,该函数可以将给定时间转换为基于指定时间粒度的时间间隔的开始或结束。
您需要在 SELECT 列表中通过在基表的分区键上使用 time_slice 函数来定义新的时间粒度(间隔),为其设置别名,并在 date_trunc 函数中使用它来指定物化视图的分区键。
PARTITION BY
date_trunc(<format>, <mv_partitioning_column>)
AS
SELECT
-- You can use time_slice.
time_slice(<base_table_partitioning_column>, <interval>) AS <mv_partitioning_column>
示例
CREATE MATERIALIZED VIEW par_mv5
REFRESH ASYNC
PARTITION BY date_trunc('day', mv_datekey)
AS
SELECT
k1,
sum(v1) AS SUM,
time_slice(datekey, INTERVAL 5 MINUTE) AS mv_datekey
FROM par_tbl1
GROUP BY datekey, k1;
与多个基表对齐分区
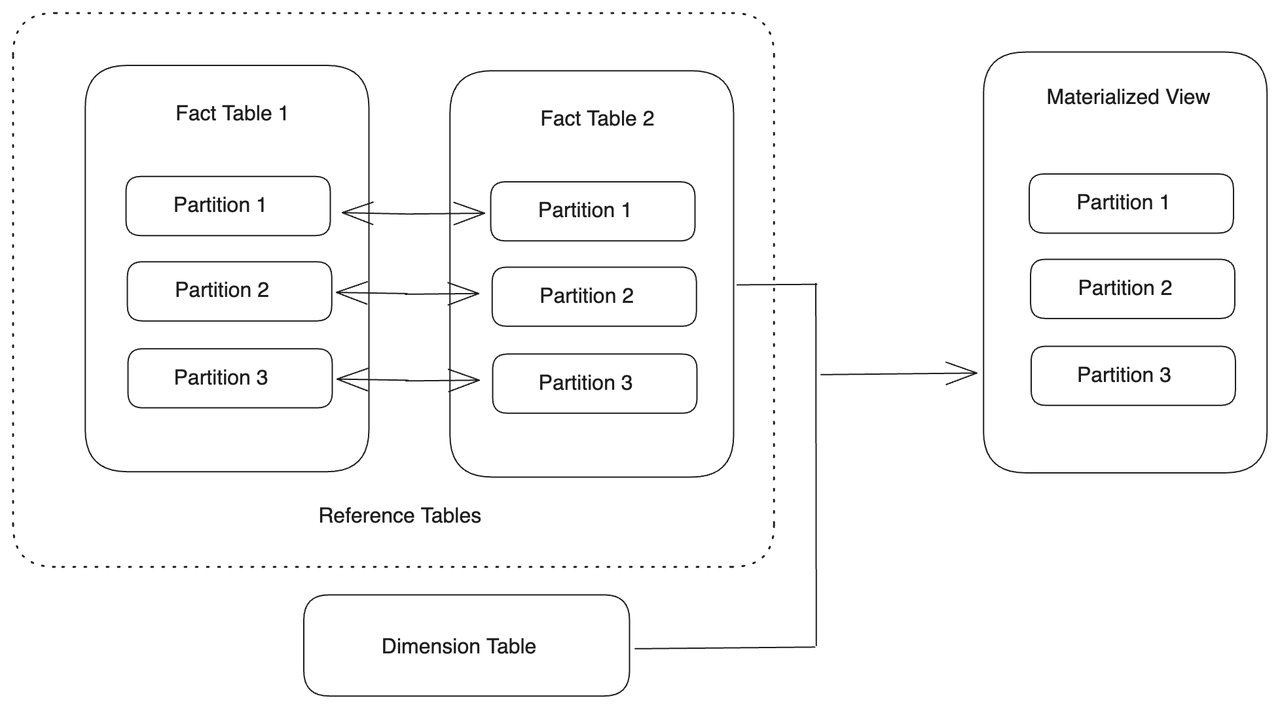
您可以创建一个物化视图,其分区与多个基表的分区对齐,只要基表的分区可以相互对齐,也就是说,基表使用相同类型的分区键。您可以使用 JOIN 连接基表,并将分区键设置为公共列。或者,您可以使用 UNION 连接它们。具有对齐分区的基表称为参考表。任何参考表中的数据更改都将触发物化视图相应分区的刷新任务。
从 v3.3 开始支持此功能。
-- Connect tables with JOIN.
CREATE MATERIALIZED VIEW par_mv6
REFRESH ASYNC
PARTITION BY datekey
AS SELECT
par_tbl1.datekey,
par_tbl1.k1 AS t1k1,
par_tbl3.k1 AS t2k1,
sum(par_tbl1.v1) AS SUM1,
sum(par_tbl3.v1) AS SUM2
FROM par_tbl1 JOIN par_tbl3 ON par_tbl1.datekey = par_tbl3.datekey_new
GROUP BY par_tbl1.datekey, t1k1, t2k1;
-- Connect tables with UNION.
CREATE MATERIALIZED VIEW par_mv7
REFRESH ASYNC
PARTITION BY datekey
AS SELECT
par_tbl1.datekey,
par_tbl1.k1 AS t1k1,
sum(par_tbl1.v1) AS SUM1
FROM par_tbl1
GROUP BY
par_tbl1.datekey,
par_tbl1.k1
UNION ALL
SELECT
par_tbl3.datekey_new,
par_tbl3.k1 AS t2k1,
sum(par_tbl3.v1) AS SUM2
FROM par_tbl3
GROUP BY
par_tbl3.datekey_new,
par_tbl3.k1;
对齐多个分区列
从 v3.5.0 开始,异步物化视图支持多列分区表达式。您可以为物化视图指定多个分区列,并将它们与基本表的分区列一一映射。这实现了 Lakehouse 集成并增强了现有 StarRocks 内部表功能的重用,从而提供了更好的 Lakehouse 解决方案
- 简化的用户体验:简化了将数据从 Data Lake 传输到 StarRocks 的过程。
- 加速的查询性能:在创建物化视图时重用本机表功能,例如 Colocate Group、Bitmap Index、Bloom Filter Index、Sort Key 和全局字典。直接引用基表的查询将受益于通过自动重写实现的透明查询加速。
多列分区表达式的注意事项
-
目前,物化视图中的多列分区只能与基本表的分区进行一对一或 N:1 关系映射,而不是 M:N关系。例如,如果基本表具有分区列
(col1, col2, ..., coln),则物化视图分区表达式只能是单个列分区,例如col1、col2或coln,或者与基本表的分区列进行一对一映射,即(col1, col2, ..., coln)。此限制旨在简化基本表和物化视图之间的分区映射逻辑,避免 M 引入的复杂性:N关系。 -
由于 Iceberg 分区表达式支持
transform函数,因此在将 Iceberg 分区表达式映射到 StarRocks 物化视图分区表达式时需要进行额外处理。映射关系如下Iceberg 转换 Iceberg 分区表达式 物化视图分区表达式 Identity <col><col>hour hour(<col>)date_trunc('hour', <col>)day day(<col>)date_trunc('day', <col>)month month(<col>)date_trunc('month', <col>)year year(<col>)date_trunc('year', <col>)bucket bucket(<col>, <n>)不支持 truncate truncate(<col>)不支持 -
对于非 Iceberg 分区列,如果未涉及分区表达式计算,则不需要额外的分区表达式处理。您可以直接映射它们。
以下示例基于 Iceberg Catalog (Spark) 中的基本表创建一个具有多列分区表达式的分区物化视图。
Spark 中基本表的定义
-- The partition expression of the base table contains multiple columns and a `days` transform.
CREATE TABLE lineitem_days (
l_orderkey BIGINT,
l_partkey INT,
l_suppkey INT,
l_linenumber INT,
l_quantity DECIMAL(15, 2),
l_extendedprice DECIMAL(15, 2),
l_discount DECIMAL(15, 2),
l_tax DECIMAL(15, 2),
l_returnflag VARCHAR(1),
l_linestatus VARCHAR(1),
l_shipdate TIMESTAMP,
l_commitdate TIMESTAMP,
l_receiptdate TIMESTAMP,
l_shipinstruct VARCHAR(25),
l_shipmode VARCHAR(10),
l_comment VARCHAR(44)
) USING ICEBERG
PARTITIONED BY (l_returnflag, l_linestatus, days(l_shipdate));
创建一个物化视图,其分区列与基本表的分区列一一映射
CREATE MATERIALIZED VIEW test_days
PARTITION BY (l_returnflag, l_linestatus, date_trunc('day', l_shipdate))
REFRESH DEFERRED MANUAL
AS
SELECT * FROM iceberg_catalog.test_db.lineitem_days;
实现增量刷新和透明重写
您可以创建一个按分区刷新的分区物化视图,以实现物化视图的增量更新以及部分数据物化查询的透明重写。
要实现这些目标,您在创建物化视图时必须考虑以下几个方面
-
刷新粒度
您可以使用属性
partition_refresh_number来指定每次刷新操作的粒度。partition_refresh_number控制刷新触发时刷新任务中要刷新的最大分区数。如果要刷新的分区数超过此值,StarRocks 将拆分刷新任务并分批完成。分区按时间顺序刷新,从最近的分区到最早的分区(不包括为将来动态创建的分区)。当值为-1时,刷新任务不会被拆分。从 v3.3 开始,默认值从-1更改为1,这意味着 StarRocks 逐个刷新分区。 -
物化范围
物化数据的范围由属性
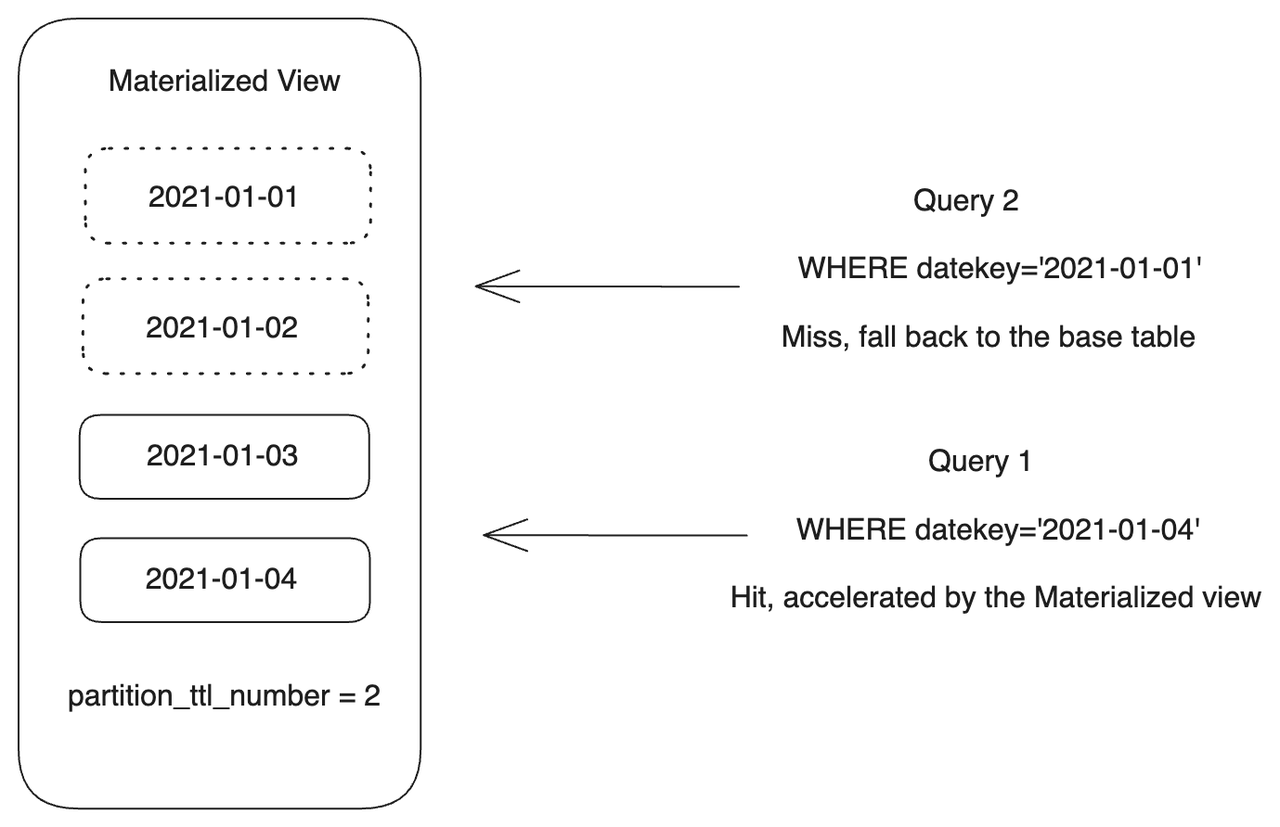
partition_ttl_number(对于 v3.1.5 之前的版本)或partition_ttl(建议用于 v3.1.5 及更高版本)控制。partition_ttl_number指定要保留的最新分区的数量,partition_ttl指定要保留的物化视图数据的时间范围。在每次刷新期间,StarRocks 按时间顺序排列分区,并且仅保留满足 TTL 要求的分区。 -
刷新策略
- 具有自动刷新策略 (
REFRESH ASYNC) 的物化视图每次基本表数据更改时都会自动刷新。 - 具有定期刷新策略 (
REFRESH ASYNC [START (<start_time>)] EVERY (INTERVAL <interval>)) 的物化视图会按照定义的时间间隔定期刷新。
注意具有自动刷新策略和定期刷新策略的物化视图会在刷新任务触发后自动刷新。StarRocks 记录并比较基本表每个分区的数据版本。数据版本的更改表示分区中的数据更改。一旦 StarRocks 检测到基本表分区中的数据更改,它就会刷新物化视图的相应分区。如果在基本表分区上未检测到数据更改,则跳过相应物化视图分区的刷新。
- 具有手动刷新策略 (
REFRESH MANUAL) 的物化视图只能通过手动执行 REFRESH MATERIALIZED VIEW 语句来刷新。您可以指定要刷新的分区的时间范围,以避免刷新整个物化视图。如果您在语句中指定FORCE,则无论基本表中的数据是否更改,StarRocks 都会强制刷新相应的物化视图或分区。通过在语句中添加WITH SYNC MODE,您可以同步调用刷新任务,并且 StarRocks 仅在任务成功或失败时返回任务结果。
- 具有自动刷新策略 (
以下示例创建一个分区物化视图 par_mv8。如果 StarRocks 检测到基本表的分区中的数据更改,它将刷新物化视图中的相应分区。刷新任务被分成批次,每个批次仅刷新一个分区 ("partition_refresh_number" = "1")。仅保留两个最新的分区 ("partition_ttl_number" = "2"),其他分区在刷新期间被删除。
CREATE MATERIALIZED VIEW par_mv8
REFRESH ASYNC
PARTITION BY datekey
PROPERTIES(
"partition_ttl_number" = "2",
"partition_refresh_number" = "1"
)
AS
SELECT
k1,
sum(v1) AS SUM,
datekey
FROM par_tbl1
GROUP BY datekey, k1;
您可以使用 REFRESH MATERIALIZED VIEW 语句来刷新此物化视图。以下示例同步调用强制刷新 par_mv8 的某个时间范围内的某些分区。
REFRESH MATERIALIZED VIEW par_mv8
PARTITION START ("2021-01-03") END ("2021-01-04")
FORCE WITH SYNC MODE;
输出
+--------------------------------------+
| QUERY_ID |
+--------------------------------------+
| 1d1c24b8-bf4b-11ee-a3cf-00163e0e23c9 |
+--------------------------------------+
1 row in set (1.12 sec)
使用 TTL 功能,par_mv8 中仅保留某些分区。因此,您已经实现了部分数据的物化,这在大多数查询都是针对最近数据的场景中非常重要。TTL 功能允许您使用物化视图透明地加速对新数据(例如,在一周或一个月内)的查询,同时显着节省存储成本。不属于此时间范围的查询将被路由到基本表。
在以下示例中,查询 1 将被物化视图加速,因为它命中 par_mv8 中保留的分区,而查询 2 将被路由到基本表,因为它不属于保留分区的时间范围。
-- Query 1
SELECT
k1,
sum(v1) AS SUM,
datekey
FROM par_tbl1
WHERE datekey='2021-01-04'
GROUP BY datekey, k1;
-- Query 2
SELECT
k1,
sum(v1) AS SUM,
datekey
FROM par_tbl1
WHERE datekey='2021-01-01'
GROUP BY datekey, k1;