使用 EXPORT 导出数据
本主题介绍如何将 StarRocks 集群中指定表或分区的数据以 CSV 数据文件格式导出到外部存储系统,该存储系统可以是分布式文件系统 HDFS 或云存储系统(如 AWS S3)。
注意
只有具有 StarRocks 表的 EXPORT 权限的用户才能将数据导出到 StarRocks 表之外。 如果您没有 EXPORT 权限,请按照 GRANT 中提供的说明,将 EXPORT 权限授予用于连接到 StarRocks 集群的用户。
背景信息
在 v2.4 及更早版本中,当 StarRocks 使用 EXPORT 语句导出数据时,它依赖 Broker 在 StarRocks 集群和外部存储系统之间建立连接。 因此,您需要在 EXPORT 语句中输入 WITH BROKER "<broker_name>" 以指定要使用的 Broker。 这被称为“基于 Broker 的卸载”。 Broker 是一项独立的无状态服务,与文件系统接口集成,可帮助 StarRocks 将数据导出到外部存储系统。
从 v2.5 开始,当 StarRocks 使用 EXPORT 语句导出数据时,不再依赖 Broker 在 StarRocks 集群和外部存储系统之间建立连接。 因此,您不再需要在 EXPORT 语句中指定 Broker,但仍需要保留 WITH BROKER 关键字。 这被称为“无 Broker 卸载”。
但是,当您的数据存储在 HDFS 中时,无 Broker 卸载可能无法工作,您可以求助于基于 Broker 的卸载。
- 如果将数据导出到多个 HDFS 集群,则需要为每个 HDFS 集群部署和配置独立的 Broker。
- 如果将数据导出到单个 HDFS 集群并且配置了多个 Kerberos 用户,则需要部署一个独立的 Broker。
支持的存储系统
- 分布式文件系统 HDFS
- 云存储系统,例如 AWS S3
注意事项
-
我们建议您一次导出的数据不要超过几十 GB。 如果一次导出大量数据,导出可能会失败,并且重试导出的成本会增加。
-
如果源 StarRocks 表包含大量数据,我们建议您每次仅从该表的几个分区导出数据,直到导出该表中的所有数据。
-
如果在导出作业运行时 StarRocks 集群中的 FE 重新启动或选出新的 leader FE,则导出作业将失败。 在这种情况下,您必须重新提交导出作业。
-
如果在导出作业完成后 StarRocks 集群中的 FE 重新启动或选出新的 leader FE,则 SHOW EXPORT 语句返回的某些作业信息可能会丢失。
-
StarRocks 仅导出基本表的数据。 StarRocks 不导出在基本表上创建的物化视图的数据。
-
导出作业需要数据扫描,这会占用 I/O 资源,从而增加查询延迟。
工作流程
提交导出作业后,StarRocks 会识别导出作业中涉及的所有 Tablet。 然后,StarRocks 将涉及的 Tablet 分组并生成查询计划。 查询计划用于从涉及的 Tablet 中读取数据,并将数据写入目标存储系统的指定路径。
下图显示了通用工作流程。
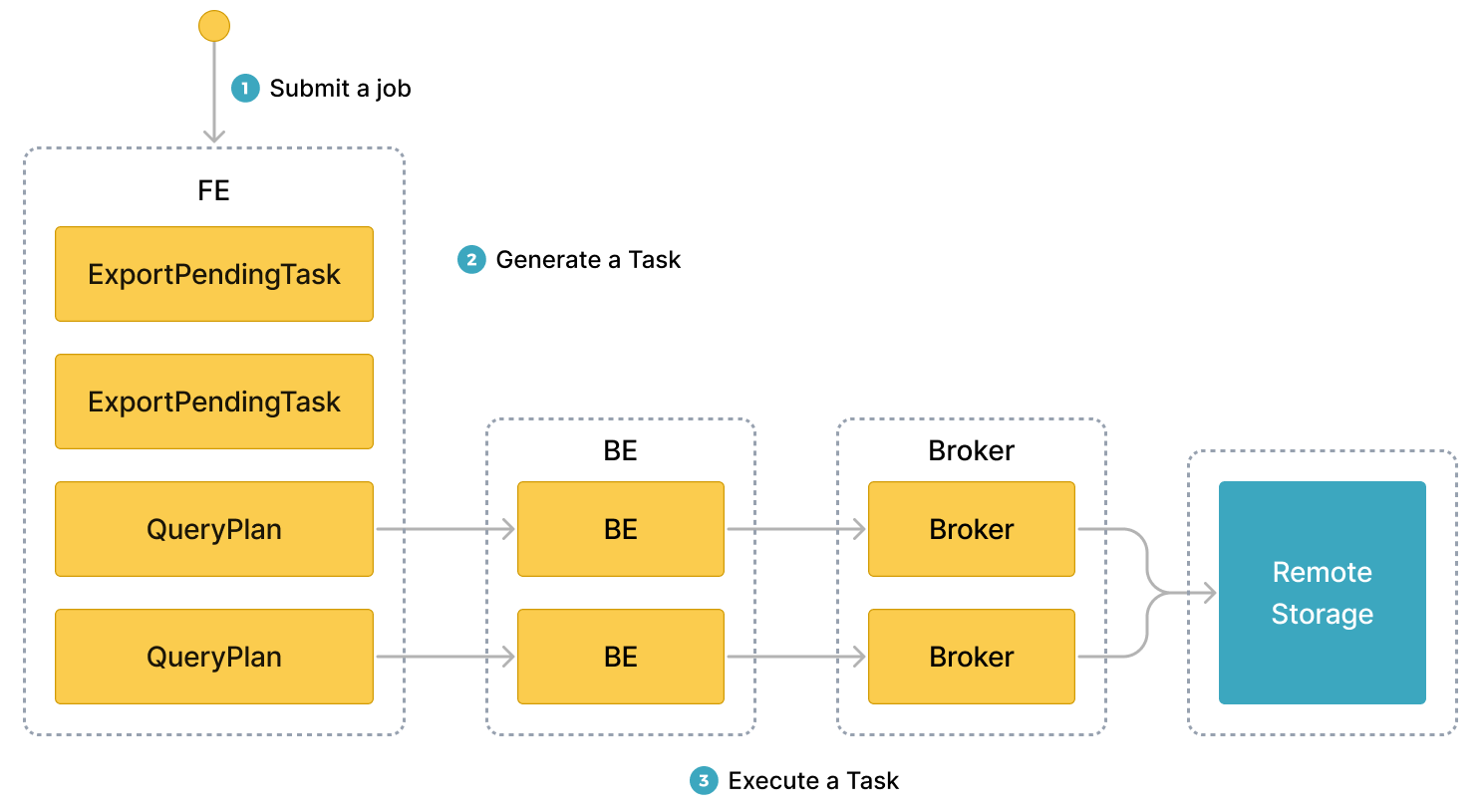
通用工作流程包括以下三个步骤
-
用户将导出作业提交到 leader FE。
-
leader FE 向 StarRocks 集群中的所有 BE 或 CN 发出
snapshot指令,以便 BE 或 CN 可以拍摄涉及的 Tablet 的快照,以确保要导出的数据的一致性。 leader FE 还会生成多个导出任务。 每个导出任务都是一个查询计划,每个查询计划都用于处理一部分涉及的 Tablet。 -
leader FE 将导出任务分发给 BE 或 CN。
原理
当 StarRocks 执行查询计划时,它首先在目标存储系统的指定路径中创建一个名为 __starrocks_export_tmp_xxx 的临时文件夹。 在临时文件夹的名称中,xxx 表示导出作业的 ID。 临时文件夹的示例名称为 __starrocks_export_tmp_921d8f80-7c9d-11eb-9342-acde48001122。 在 StarRocks 成功执行查询计划后,它会在临时文件夹中生成一个临时文件,并将导出的数据写入生成的临时文件。
导出所有数据后,StarRocks 使用 RENAME 语句将生成的临时文件保存到指定的路径。
相关参数
本节介绍您可以在 StarRocks 集群的 FE 中配置的一些与导出相关的参数。
-
export_checker_interval_second:调度导出作业的间隔。 默认间隔为 5 秒。 为 FE 重新配置此参数后,您需要重新启动 FE 才能使新的参数设置生效。 -
export_running_job_num_limit:允许运行的导出作业的最大数量。 如果运行的导出作业的数量超过此限制,则过多的导出作业会在运行snapshot后进入等待状态。 默认最大数量为 5。 您可以在导出作业运行时重新配置此参数。 -
export_task_default_timeout_second:导出作业的超时时间。 默认超时时间为 2 小时。 您可以在导出作业运行时重新配置此参数。 -
export_max_bytes_per_be_per_task:每个 BE 或 CN 的每个导出任务可以导出的最大压缩数据量。 此参数提供了一个策略,StarRocks 可以根据该策略将导出作业拆分为可以并发运行的导出任务。 默认最大数量为 256 MB。 -
export_task_pool_size:线程池可以并发运行的最大导出任务数。 默认最大数量为 5。
基本操作
提交导出作业
假设您的 StarRocks 数据库 db1 包含一个名为 tbl1 的表。 要将 tbl1 的分区 p1 和 p2 中的列 col1 和 col3 的数据导出到 HDFS 集群的 export 路径,请运行以下命令
EXPORT TABLE db1.tbl1
PARTITION (p1,p2)
(col1, col3)
TO "hdfs://HDFS_IP:HDFS_Port/export/lineorder_"
PROPERTIES
(
"column_separator"=",",
"load_mem_limit"="2147483648",
"timeout" = "3600"
)
WITH BROKER
(
"username" = "user",
"password" = "passwd"
);
有关详细的语法和参数说明以及将数据导出到 AWS S3 的命令示例,请参见 EXPORT。
获取导出作业的查询 ID
提交导出作业后,可以使用 SELECT LAST_QUERY_ID() 语句查询导出作业的查询 ID。 使用查询 ID,您可以查看或取消导出作业。
有关详细的语法和参数说明,请参见 last_query_id。
查看导出作业的状态
提交导出作业后,可以使用 SHOW EXPORT 语句查看导出作业的状态。 示例
SHOW EXPORT WHERE queryid = "edee47f0-abe1-11ec-b9d1-00163e1e238f";
注意
在上面的示例中,
queryid是导出作业的查询 ID。
返回类似于以下输出的信息
JobId: 14008
State: FINISHED
Progress: 100%
TaskInfo: {"partitions":["*"],"mem limit":2147483648,"column separator":",","line delimiter":"\n","tablet num":1,"broker":"hdfs","coord num":1,"db":"default_cluster:db1","tbl":"tbl3",columns:["col1", "col3"]}
Path: oss://bj-test/export/
CreateTime: 2019-06-25 17:08:24
StartTime: 2019-06-25 17:08:28
FinishTime: 2019-06-25 17:08:34
Timeout: 3600
ErrorMsg: N/A
有关详细的语法和参数说明,请参见 SHOW EXPORT。
取消导出作业
您可以使用 CANCEL EXPORT 语句取消您提交的导出作业。 示例
CANCEL EXPORT WHERE queryid = "921d8f80-7c9d-11eb-9342-acde48001122";
注意
在上面的示例中,
queryid是导出作业的查询 ID。
有关详细的语法和参数说明,请参见 CANCEL EXPORT。
最佳实践
查询计划拆分
导出作业拆分的查询计划数取决于导出作业中涉及的 Tablet 数以及每个查询计划可以处理的最大数据量。 导出作业将作为查询计划重试。 如果查询计划处理的数据量超过允许的最大量,则查询计划会遇到远程存储抖动等错误。 结果,重试查询计划的成本增加。 每个 BE 或 CN 的每个查询计划可以处理的最大数据量由 export_max_bytes_per_be_per_task 参数指定,默认为 256 MB。 在查询计划中,每个 BE 或 CN 至少分配一个 Tablet,并且可以导出不超过 export_max_bytes_per_be_per_task 参数指定的限制的数据量。
导出作业的多个查询计划并发执行。 您可以使用 FE 参数 export_task_pool_size 指定线程池允许并发运行的最大导出任务数。 此参数默认为 5。
在正常情况下,导出作业的每个查询计划仅由两部分组成:扫描和导出。 执行查询计划所需的计算逻辑不会消耗太多内存。 因此,2 GB 的默认内存限制可以满足您的大多数业务需求。 但是,在某些情况下,例如当查询计划需要在 BE 或 CN 上扫描许多 Tablet 或 Tablet 有许多版本时,2 GB 的内存容量可能不足。 在这些情况下,您需要使用 load_mem_limit 参数指定更高的内存容量限制,例如 4 GB 或 8 GB。