表概述
表是数据存储的单元。 了解 StarRocks 中的表结构以及如何设计高效的表结构有助于优化数据组织并提高查询效率。 此外,与传统数据库相比,StarRocks 可以以列式方式存储复杂的半结构化数据(例如 JSON、ARRAY),从而提高查询性能。
本主题从基本和通用角度介绍 StarRocks 中的表结构。
从 v3.3.1 开始,StarRocks 支持在 Default Catalog 中创建临时表。
开始了解基本表结构
与其他关系数据库一样,表在逻辑上由行和列组成
- 行:每行包含一条记录。 每行包含一组相关的数据值。
- 列:列定义每条记录的属性。 每列包含特定属性的数据。 例如,员工表可能包含姓名、员工 ID、部门和工资等列,其中每列存储相应的数据。 每列中的数据属于相同的数据类型。 表中的所有行都具有相同数量的列。
在 StarRocks 中创建表很简单。 您只需要在 CREATE TABLE 语句中定义列及其数据类型即可创建表。 例子
CREATE DATABASE example_db;
USE example_db;
CREATE TABLE user_access (
uid int,
name varchar(64),
age int,
phone varchar(16),
last_access datetime,
credits double
)
ORDER BY (uid, name);
上面的 CREATE TABLE 示例创建了一个 Duplicate Key 表。 此类型的表中没有向列添加约束,因此表中可能存在重复的数据行。 Duplicate Key 表的前两列被指定为排序字段以形成排序键。 数据在根据排序键排序后存储,这可以加速查询期间的索引。
自 v3.3.0 起,Duplicate Key 表支持使用 ORDER BY 指定排序键。 如果同时使用 ORDER BY 和 DUPLICATE KEY,则 DUPLICATE KEY 不生效。
如果暂存环境中的 StarRocks 集群仅包含一个 BE,则可以在 PROPERTIES 子句中将副本数设置为 1,例如 PROPERTIES( "replication_num" = "1" )。 默认副本数为 3,这也是生产 StarRocks 集群推荐的数目。 如果要使用默认数量,则无需配置 replication_num 参数。
执行 DESCRIBE 以查看表模式。
MySQL [test]> DESCRIBE user_access;
+-------------+-------------+------+-------+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------------+-------------+------+-------+---------+-------+
| uid | int | YES | true | NULL | |
| name | varchar(64) | YES | true | NULL | |
| age | int | YES | false | NULL | |
| phone | varchar(16) | YES | false | NULL | |
| last_access | datetime | YES | false | NULL | |
| credits | double | YES | false | NULL | |
+-------------+-------------+------+-------+---------+-------+
6 rows in set (0.00 sec)
执行 SHOW CREATE TABLE 以查看 CREATE TABLE 语句。
MySQL [example_db]> SHOW CREATE TABLE user_access\G
*************************** 1. row ***************************
Table: user_access
Create Table: CREATE TABLE `user_access` (
`uid` int(11) NULL COMMENT "",
`name` varchar(64) NULL COMMENT "",
`age` int(11) NULL COMMENT "",
`phone` varchar(16) NULL COMMENT "",
`last_access` datetime NULL COMMENT "",
`credits` double NULL COMMENT ""
) ENGINE=OLAP
DUPLICATE KEY(`uid`, `name`)
DISTRIBUTED BY RANDOM
ORDER BY(`uid`, `name`)
PROPERTIES (
"bucket_size" = "4294967296",
"compression" = "LZ4",
"fast_schema_evolution" = "true",
"replicated_storage" = "true",
"replication_num" = "3"
);
1 row in set (0.01 sec)
了解全面的表结构
深入了解 StarRocks 表结构有助于您设计高效的数据管理结构,以满足您的业务需求。
表类型
StarRocks 提供了四种类型的表,即 Duplicate Key 表、Primary Key 表、Aggregate 表和 Unique Key 表,用于存储各种业务场景的数据,例如原始数据、频繁更新的实时数据和聚合数据。
- Duplicate Key 表简单易用。 此类型的表中没有向列添加约束,因此表中可能存在重复的数据行。 Duplicate Key 表适用于存储原始数据,例如日志,这些数据不需要任何约束或预聚合。
- Primary Key 表功能强大。 唯一和非空约束都添加到主键列。 Primary Key 表支持实时频繁更新和部分列更新,同时确保高查询性能,因此适用于实时查询场景。
- Aggregate 表适用于存储预聚合数据,有助于减少扫描和计算的数据量,并提高聚合查询的效率。
- Unique 表也适用于存储频繁更新的实时数据。 然而,这种类型的表正在被更强大的 Primary Key 表所取代。
数据分布
StarRocks 使用分区+分桶两层数据分布策略,将数据均匀地分布在 BE 之间。 设计良好的数据分布策略可以有效地减少扫描的数据量,并最大限度地提高 StarRocks 的并发处理能力,从而提高查询性能。
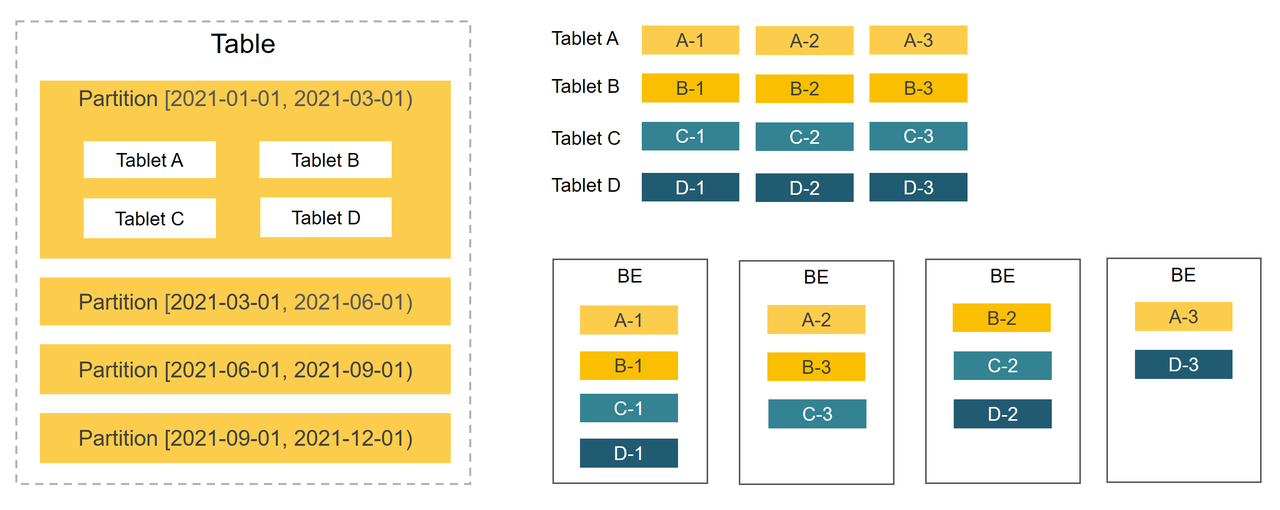
分区
第一层是分区:表中的数据可以根据分区字段划分为更小的数据管理单元,分区字段通常是保存日期和时间的列。 在查询期间,分区裁剪可以减少需要扫描的数据量,从而有效地优化查询性能。
StarRocks 提供了一种易于使用的分区方法,即表达式分区,并且还提供更灵活的方法,如范围分区和列表分区。
分桶
第二层是分桶:分区中的数据通过分桶进一步划分为更小的数据管理单元。 每个桶的副本均匀地分布在 BE 之间,以确保高数据可用性。
StarRocks 提供了两种分桶方法
- 哈希分桶:数据根据分桶键的哈希值分布到桶中。 您可以选择查询中常用的作为条件字段的列作为分桶列,这有助于提高查询效率。
- 随机分桶:数据随机分布到桶中。 这种分桶方法更简单易用。
数据类型
除了 NUMERIC、DATE 和 STRING 等基本数据类型外,StarRocks 还支持复杂的半结构化数据类型,包括 ARRAY、JSON、MAP 和 STRUCT。
索引
索引是一种特殊的数据结构,用作表中数据的指针。 当查询中的条件字段是索引字段时,StarRocks 可以快速定位满足条件的数据。
StarRocks 提供内置索引:前缀索引、Ordinal 索引和 ZoneMap 索引。 StarRocks 还允许用户创建索引,即 Bitmap 索引和 Bloom Filter 索引,以进一步提高查询效率。
约束
约束有助于确保数据完整性、一致性和准确性。 Primary Key 表中的主键列必须具有唯一且 NOT NULL 值。 Aggregate 表中的聚合键列和 Unique Key 表中的唯一键列必须具有唯一值。
临时表
在处理数据时,您可能需要保存中间结果以供将来重用。 在早期版本中,StarRocks 仅支持使用 CTE(公用表表达式)来定义单个查询中的临时结果。 然而,CTE 仅仅是逻辑结构,不物理存储结果,并且不能跨不同的查询使用,这带来了一定的限制。 如果您选择创建表来保存中间结果,则需要管理这些表的生命周期,这可能会很昂贵。
为了解决这个问题,StarRocks 在 v3.3.1 中引入了临时表。 临时表允许您在表中临时存储数据(例如来自 ETL 流程的中间结果),其生命周期与会话绑定并由 StarRocks 管理。 当会话结束时,临时表会自动清除。 临时表仅在当前会话中可见,不同的会话可以创建同名的临时表。
用法
您可以使用以下 SQL 语句中的 TEMPORARY 关键字来创建和删除临时表
与其他类型的原生表类似,临时表必须在 Default Catalog 下的数据库下创建。 但是,由于临时表是基于会话的,因此它们不受唯一命名约束的约束。 您可以在不同的会话中创建同名的临时表,甚至可以创建与非临时原生表同名的临时表。
如果数据库中存在同名的临时表和非临时表,则临时表优先。 在会话中,对同名表的所有查询和操作只会影响临时表。
局限性
虽然临时表的用法与原生表的用法相似,但也存在一些约束和差异
- 临时表必须在 Default Catalog 中创建。
- 不支持设置 Colocate Group。 如果在表创建期间显式指定了
colocate_with属性,则将被忽略。 - 在创建表时,必须将
ENGINE指定为olap。 - 不支持 ALTER TABLE 语句。
- 不支持基于临时表创建视图和物化视图。
- 不支持 EXPORT 语句。
- 不支持 SELECT INTO OUTFILE 语句。
- 不支持使用 SUBMIT TASK 提交异步任务来创建临时表。
更多功能
除了上述功能外,您还可以根据您的业务需求采用更多功能来设计更强大的表结构。 例如,使用 Bitmap 和 HLL 列来加速去重计数,指定 Generated Columns 或自增列来加速某些查询,配置灵活的自动存储冷热分层方法来降低维护成本,以及配置 Colocate Join 来加速多表 JOIN 查询。 有关更多详细信息,请参阅 CREATE TABLE。