使用共享数据存储的 Kafka 例行导入到 StarRocks
关于 Routine Load
Routine Load 是一种使用 Apache Kafka(或者在本实验中,使用 Redpanda)将数据持续流式传输到 StarRocks 的方法。数据流式传输到 Kafka topic 中,然后 Routine Load 作业从 topic 中消费数据并加载到 StarRocks 中。本实验的末尾将提供有关 Routine Load 的更多详细信息。
关于共享数据
在存储和计算分离的系统中,数据存储在低成本、可靠的远程存储系统中,例如 Amazon S3、Google Cloud Storage、Azure Blob Storage 和其他 S3 兼容存储(如 MinIO)。热数据缓存在本地,当命中缓存时,查询性能与存储和计算耦合的架构相当。计算节点 (CN) 可以根据需要在几秒钟内添加或删除。这种架构降低了存储成本,确保了更好的资源隔离,并提供了弹性和可扩展性。
本教程涵盖
- 使用 Docker Compose 运行 StarRocks、Redpanda 和 MinIO
- 使用 MinIO 作为 StarRocks 的存储层
- 配置 StarRocks 以使用共享数据
- 添加 Routine Load 作业以从 Redpanda 消费数据
所使用的数据是合成数据。
本文档包含大量信息,开头以逐步内容呈现,技术细节在结尾。这样做是为了按以下顺序服务于这些目的:
- 配置 Routine Load。
- 允许读者在共享数据部署中加载数据并分析该数据。
- 提供共享数据部署的配置详细信息。
前提条件
Docker
- Docker
- 分配给 Docker 的 4 GB RAM
- 分配给 Docker 的 10 GB 可用磁盘空间
SQL 客户端
您可以使用 Docker 环境中提供的 SQL 客户端,或者使用系统上的 SQL 客户端。许多与 MySQL 兼容的客户端都可以工作,本指南涵盖了 DBeaver 和 MySQL Workbench 的配置。
curl
curl 用于下载 Compose 文件和生成数据的脚本。通过在操作系统提示符下运行 curl 或 curl.exe 来检查是否已安装。如果未安装 curl,请在此处获取 curl。
Python
需要 Python 3 和 Apache Kafka 的 Python 客户端 kafka-python。
术语
FE
前端节点负责元数据管理、客户端连接管理、查询规划和查询调度。每个 FE 在其内存中存储和维护元数据的完整副本,这保证了 FE 之间的无差别服务。
CN
计算节点负责在共享数据部署中执行查询计划。
BE
后端节点负责在共享存储部署中负责数据存储和执行查询计划。
本指南不使用 BE,此处包含此信息是为了让您了解 BE 和 CN 之间的区别。
启动 StarRocks
要使用共享数据通过对象存储运行 StarRocks,您需要
- 前端引擎 (FE)
- 计算节点 (CN)
- 对象存储
本指南使用 MinIO,它是一个 S3 兼容的对象存储提供商。MinIO 在 GNU Affero General Public License 下提供。
下载实验文件
docker-compose.yml
mkdir routineload
cd routineload
curl -O https://raw.githubusercontent.com/StarRocks/demo/master/documentation-samples/routine-load-shared-data/docker-compose.yml
gen.py
gen.py 是一个脚本,它使用 Apache Kafka 的 Python 客户端将数据发布(生成)到 Kafka topic。该脚本已使用 Redpanda 容器的地址和端口编写。
curl -O https://raw.githubusercontent.com/StarRocks/demo/master/documentation-samples/routine-load-shared-data/gen.py
启动 StarRocks、MinIO 和 Redpanda
docker compose up --detach --wait --wait-timeout 120
检查服务的进度。容器需要 30 秒或更长时间才能变为健康状态。routineload-minio_mc-1 容器不会显示健康指标,并且在完成使用 StarRocks 将使用的访问密钥配置 MinIO 后退出。等待 routineload-minio_mc-1 以代码 0 退出,其余服务变为 Healthy。
运行 docker compose ps 直到服务健康
docker compose ps
WARN[0000] /Users/droscign/routineload/docker-compose.yml: `version` is obsolete
[+] Running 6/7
✔ Network routineload_default Crea... 0.0s
✔ Container minio Healthy 5.6s
✔ Container redpanda Healthy 3.6s
✔ Container redpanda-console Healt... 1.1s
⠧ Container routineload-minio_mc-1 Waiting 23.1s
✔ Container starrocks-fe Healthy 11.1s
✔ Container starrocks-cn Healthy 23.0s
container routineload-minio_mc-1 exited (0)
检查 MinIO 凭据
为了将 MinIO 用于 StarRocks 的对象存储,StarRocks 需要 MinIO 访问密钥。访问密钥是在 Docker 服务启动期间生成的。为了帮助您更好地了解 StarRocks 连接到 MinIO 的方式,您应该验证该密钥是否存在。
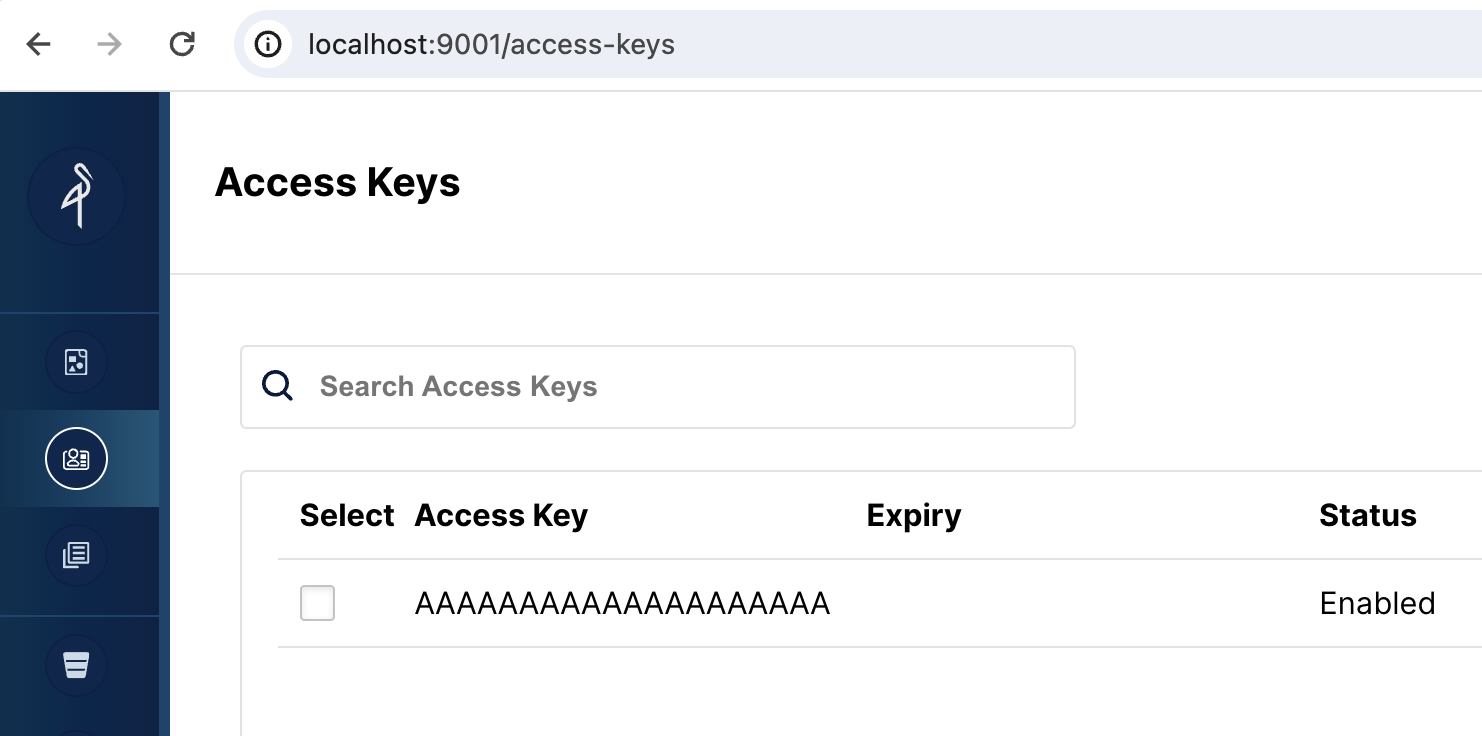
打开 MinIO Web UI
浏览到 https://:9001/access-keys 用户名和密码在 Docker Compose 文件中指定,分别为 miniouser 和 miniopassword。您应该看到有一个访问密钥。密钥是 AAAAAAAAAAAAAAAAAAAA,您无法在 MinIO 控制台中看到密钥,但它在 Docker Compose 文件中,它是 BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB
SQL 客户端
这三个客户端已经过本教程的测试,您只需要一个
- mysql CLI:您可以从 Docker 环境或您的机器运行它。
- DBeaver 可作为社区版和 Pro 版提供。
- MySQL Workbench
配置客户端
- mysql CLI
- DBeaver
- MySQL Workbench
使用 mysql CLI 的最简单方法是从 StarRocks 容器 starrocks-fe 运行它
docker compose exec starrocks-fe \
mysql -P 9030 -h 127.0.0.1 -u root --prompt="StarRocks > "
所有 docker compose 命令都必须从包含 docker-compose.yml 文件的目录中运行。
如果您想安装 mysql CLI,请展开下面的 mysql client install
mysql 客户端安装
- macOS:如果您使用 Homebrew 并且不需要 MySQL Server,请运行
brew install mysql以安装 CLI。 - Linux:检查您的存储库系统以获取
mysql客户端。例如,yum install mariadb。 - Microsoft Windows:安装 MySQL Community Server 并运行提供的客户端,或从 WSL 运行
mysql。
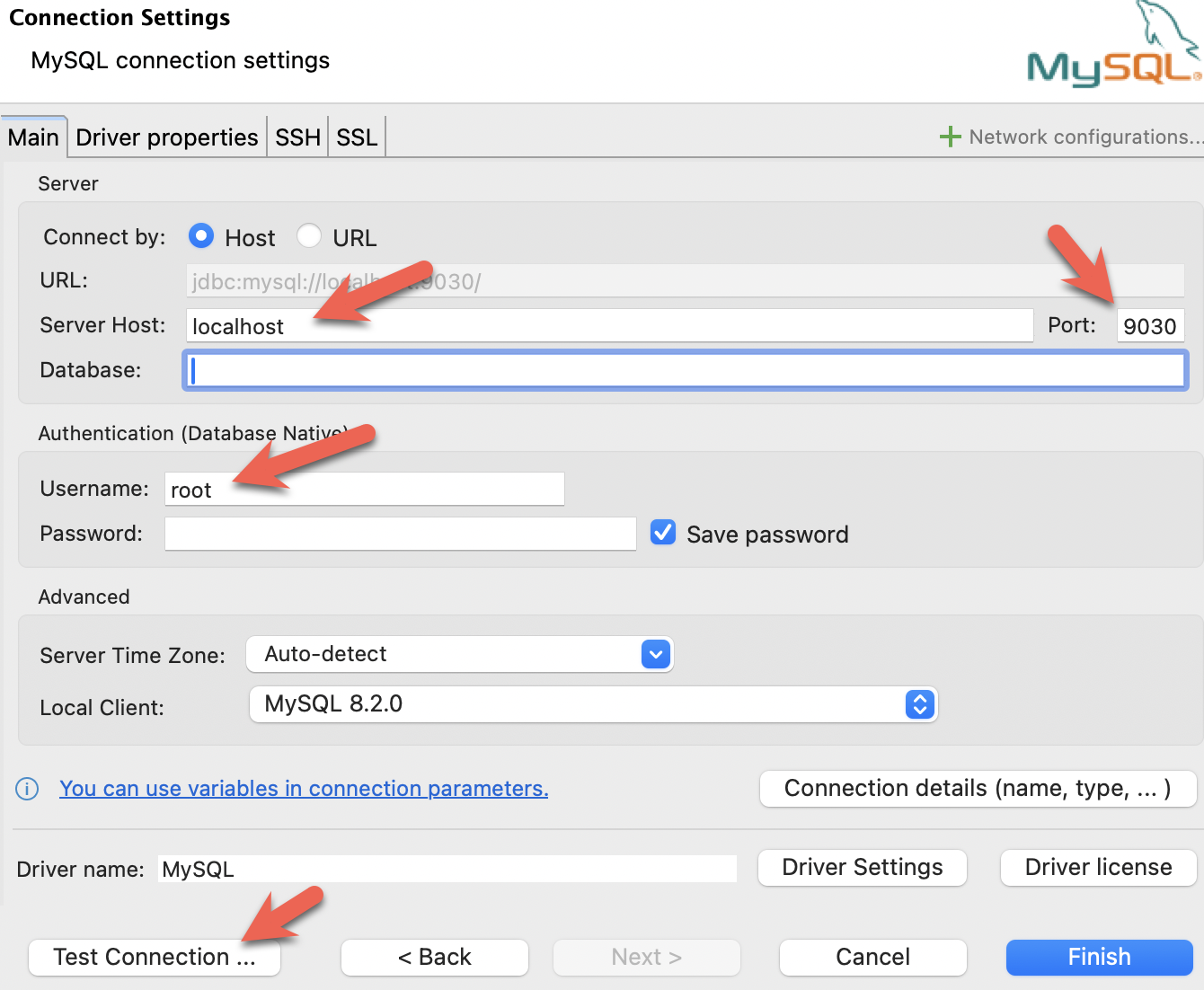
- 安装 DBeaver,并添加一个连接:

- 配置端口、IP 和用户名。测试连接,如果测试成功,请单击“完成”:
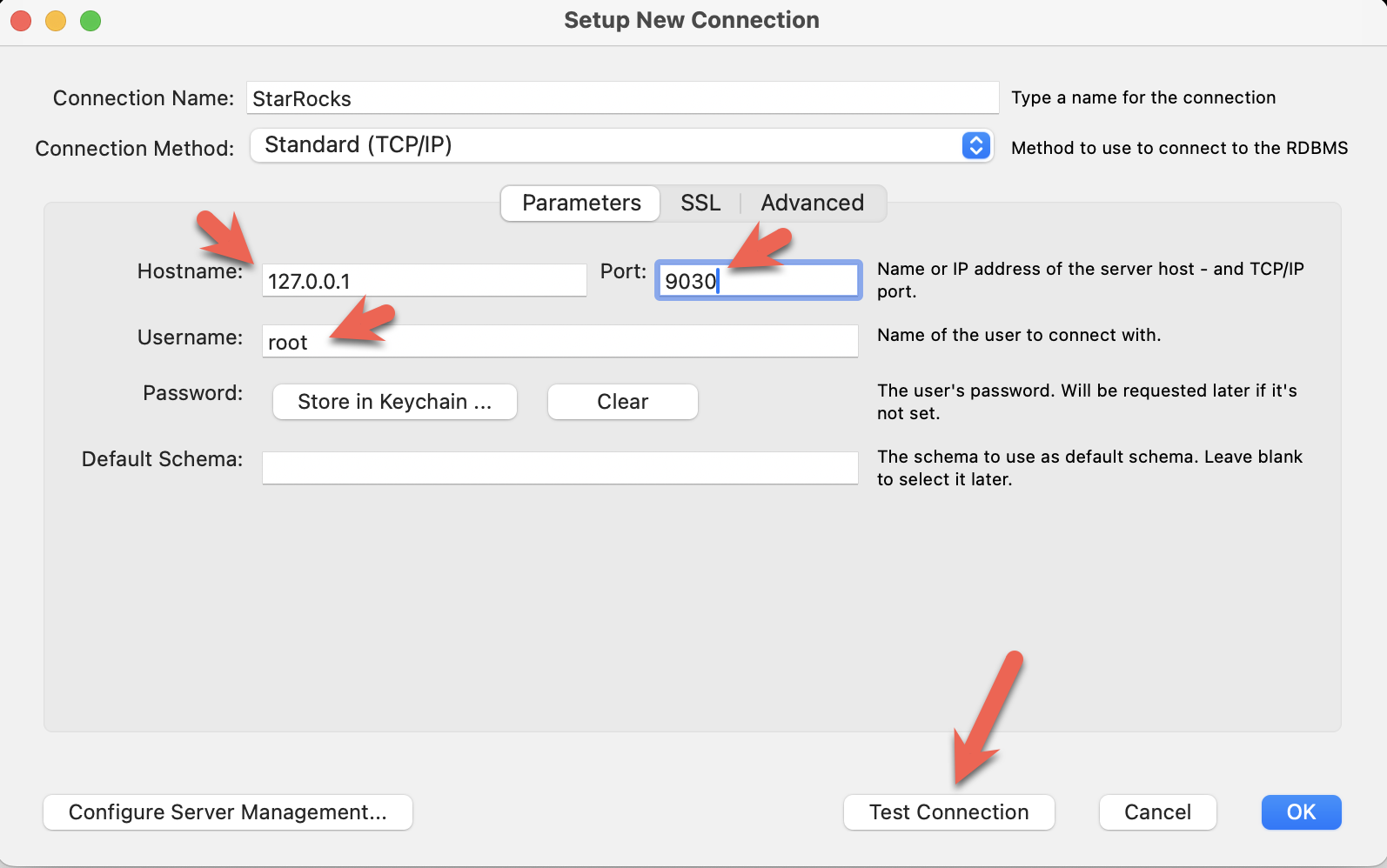
- 安装 MySQL Workbench,并添加连接。
- 配置端口、IP 和用户名,然后测试连接:
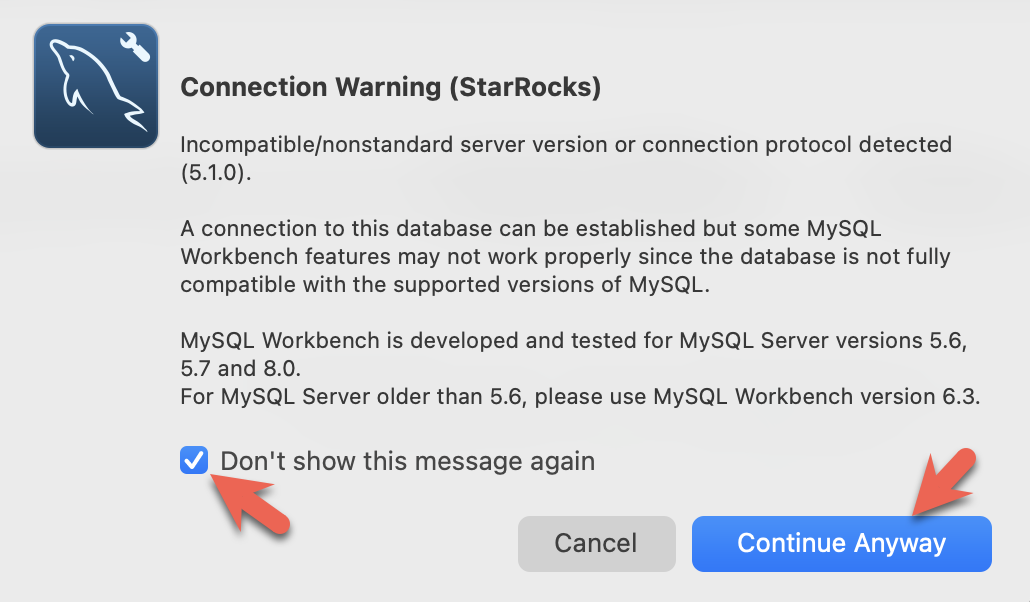
- 当 Workbench 检查特定的 MySQL 版本时,您会看到警告。您可以忽略这些警告,并在提示时配置 Workbench 以停止显示警告:
共享数据的 StarRocks 配置
此时,您已经运行了 StarRocks、Redpanda 和 MinIO。MinIO 访问密钥用于连接 StarRocks 和 MinIO。当 StarRocks 启动时,它与 MinIO 建立了连接,并在 MinIO 中创建了默认存储卷。
这是用于设置默认存储卷以使用 MinIO 的配置(这也在 Docker Compose 文件中)。该配置将在本指南的末尾详细描述,现在只需注意 aws_s3_access_key 设置为您在 MinIO 控制台中看到的字符串,并且 run_mode 设置为 shared_data。
# enable shared data, set storage type, set endpoint
run_mode = shared_data
cloud_native_storage_type = S3
aws_s3_endpoint = minio:9000
# set the path in MinIO
aws_s3_path = starrocks
# credentials for MinIO object read/write
aws_s3_access_key = AAAAAAAAAAAAAAAAAAAA
aws_s3_secret_key = BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB
aws_s3_use_instance_profile = false
aws_s3_use_aws_sdk_default_behavior = false
# Set this to false if you do not want default
# storage created in the object storage using
# the details provided above
enable_load_volume_from_conf = true
要查看完整的配置文件,您可以运行以下命令
docker compose exec starrocks-fe cat fe/conf/fe.conf
从包含 docker-compose.yml 文件的目录中运行所有 docker compose 命令。
使用 SQL 客户端连接到 StarRocks
从包含 docker-compose.yml 文件的目录中运行此命令。
如果您使用 mysql CLI 以外的客户端,请立即打开它。
docker compose exec starrocks-fe \
mysql -P9030 -h127.0.0.1 -uroot --prompt="StarRocks > "
检查存储卷
SHOW STORAGE VOLUMES;
+------------------------+
| Storage Volume |
+------------------------+
| builtin_storage_volume |
+------------------------+
1 row in set (0.00 sec)
DESC STORAGE VOLUME builtin_storage_volume\G
本文档中的一些 SQL 以及 StarRocks 文档中的许多其他文档,都使用 \G 而不是分号。\G 使 mysql CLI 垂直呈现查询结果。
许多 SQL 客户端不解释垂直格式输出,因此您应该将 \G 替换为 ;。
*************************** 1. row ***************************
Name: builtin_storage_volume
Type: S3
IsDefault: true
Location: s3://starrocks
Params: {"aws.s3.access_key":"******","aws.s3.secret_key":"******","aws.s3.endpoint":"minio:9000","aws.s3.region":"","aws.s3.use_instance_profile":"false","aws.s3.use_aws_sdk_default_behavior":"false"}
Enabled: true
Comment:
1 row in set (0.03 sec)
验证参数是否与配置匹配。
在数据写入存储桶之前,文件夹 builtin_storage_volume 在 MinIO 对象列表中不可见。
创建表
这些 SQL 命令在您的 SQL 客户端中运行。
CREATE DATABASE quickstart;
USE quickstart;
CREATE TABLE site_clicks (
`uid` bigint NOT NULL COMMENT "uid",
`site` string NOT NULL COMMENT "site url",
`vtime` bigint NOT NULL COMMENT "vtime"
)
DISTRIBUTED BY HASH(`uid`)
PROPERTIES("replication_num"="1");
打开 Redpanda 控制台
目前还没有 topic,topic 将在下一步中创建。
将数据发布到 Redpanda topic
从 routineload/ 文件夹中的命令 shell 运行此命令以生成数据
python gen.py 5
在您的系统中,您可能需要使用 python3 代替命令中的 python。
如果您缺少 kafka-python,请尝试
pip install kafka-python
或
pip3 install kafka-python
b'{ "uid": 6926, "site": "https://docs.starrocks.org.cn/", "vtime": 1718034793 } '
b'{ "uid": 3303, "site": "https://www.starrocks.io/product/community", "vtime": 1718034793 } '
b'{ "uid": 227, "site": "https://docs.starrocks.org.cn/", "vtime": 1718034243 } '
b'{ "uid": 7273, "site": "https://docs.starrocks.org.cn/", "vtime": 1718034794 } '
b'{ "uid": 4666, "site": "https://www.starrocks.io/", "vtime": 1718034794 } '
在 Redpanda 控制台中验证
在 Redpanda 控制台中导航到 https://:8080/topics,您将看到一个名为 test2 的 topic。选择该 topic,然后选择“消息”选项卡,您将看到与 gen.py 输出匹配的五条消息。
消费消息
在 StarRocks 中,您将创建一个 Routine Load 作业来
- 从 Redpanda topic
test2消费消息 - 将这些消息加载到表
site_clicks中
StarRocks 配置为使用 MinIO 进行存储,因此插入到 site_clicks 表中的数据将存储在 MinIO 中。
创建 Routine Load 作业
在 SQL 客户端中运行此命令以创建 Routine Load 作业,该命令将在本实验的末尾详细解释。
CREATE ROUTINE LOAD quickstart.clicks ON site_clicks
PROPERTIES
(
"format" = "JSON",
"jsonpaths" ="[\"$.uid\",\"$.site\",\"$.vtime\"]"
)
FROM KAFKA
(
"kafka_broker_list" = "redpanda:29092",
"kafka_topic" = "test2",
"kafka_partitions" = "0",
"kafka_offsets" = "OFFSET_BEGINNING"
);
验证 Routine Load 作业
SHOW ROUTINE LOAD\G
验证三个突出显示的行
- 状态应为
RUNNING - topic 应为
test2,broker 应为redpanda:2092 - 统计信息应显示 0 或 5 个加载的行,具体取决于您运行
SHOW ROUTINE LOAD命令的速度。如果有 0 个加载的行,请再次运行它。
*************************** 1. row ***************************
Id: 10078
Name: clicks
CreateTime: 2024-06-12 15:51:12
PauseTime: NULL
EndTime: NULL
DbName: quickstart
TableName: site_clicks
State: RUNNING
DataSourceType: KAFKA
CurrentTaskNum: 1
JobProperties: {"partitions":"*","partial_update":"false","columnToColumnExpr":"*","maxBatchIntervalS":"10","partial_update_mode":"null","whereExpr":"*","dataFormat":"json","timezone":"Etc/UTC","format":"json","log_rejected_record_num":"0","taskTimeoutSecond":"60","json_root":"","maxFilterRatio":"1.0","strict_mode":"false","jsonpaths":"[\"$.uid\",\"$.site\",\"$.vtime\"]","taskConsumeSecond":"15","desireTaskConcurrentNum":"5","maxErrorNum":"0","strip_outer_array":"false","currentTaskConcurrentNum":"1","maxBatchRows":"200000"}
DataSourceProperties: {"topic":"test2","currentKafkaPartitions":"0","brokerList":"redpanda:29092"}
CustomProperties: {"group.id":"clicks_ea38a713-5a0f-4abe-9b11-ff4a241ccbbd"}
Statistic: {"receivedBytes":0,"errorRows":0,"committedTaskNum":0,"loadedRows":0,"loadRowsRate":0,"abortedTaskNum":0,"totalRows":0,"unselectedRows":0,"receivedBytesRate":0,"taskExecuteTimeMs":1}
Progress: {"0":"OFFSET_ZERO"}
TimestampProgress: {}
ReasonOfStateChanged:
ErrorLogUrls:
TrackingSQL:
OtherMsg:
LatestSourcePosition: {}
1 row in set (0.00 sec)
SHOW ROUTINE LOAD\G
*************************** 1. row ***************************
Id: 10076
Name: clicks
CreateTime: 2024-06-12 18:40:53
PauseTime: NULL
EndTime: NULL
DbName: quickstart
TableName: site_clicks
State: RUNNING
DataSourceType: KAFKA
CurrentTaskNum: 1
JobProperties: {"partitions":"*","partial_update":"false","columnToColumnExpr":"*","maxBatchIntervalS":"10","partial_update_mode":"null","whereExpr":"*","dataFormat":"json","timezone":"Etc/UTC","format":"json","log_rejected_record_num":"0","taskTimeoutSecond":"60","json_root":"","maxFilterRatio":"1.0","strict_mode":"false","jsonpaths":"[\"$.uid\",\"$.site\",\"$.vtime\"]","taskConsumeSecond":"15","desireTaskConcurrentNum":"5","maxErrorNum":"0","strip_outer_array":"false","currentTaskConcurrentNum":"1","maxBatchRows":"200000"}
DataSourceProperties: {"topic":"test2","currentKafkaPartitions":"0","brokerList":"redpanda:29092"}
CustomProperties: {"group.id":"clicks_a9426fee-45bb-403a-a1a3-b3bc6c7aa685"}
Statistic: {"receivedBytes":372,"errorRows":0,"committedTaskNum":1,"loadedRows":5,"loadRowsRate":0,"abortedTaskNum":0,"totalRows":5,"unselectedRows":0,"receivedBytesRate":0,"taskExecuteTimeMs":519}
Progress: {"0":"4"}
TimestampProgress: {"0":"1718217035111"}
ReasonOfStateChanged:
ErrorLogUrls:
TrackingSQL:
OtherMsg:
LatestSourcePosition: {"0":"5"}
1 row in set (0.00 sec)
验证数据是否存储在 MinIO 中
打开 MinIO https://:9001/browser/ 并验证 starrocks 下是否存储了对象。
从 StarRocks 查询数据
USE quickstart;
SELECT * FROM site_clicks;
+------+--------------------------------------------+------------+
| uid | site | vtime |
+------+--------------------------------------------+------------+
| 4607 | https://www.starrocks.io/blog | 1718031441 |
| 1575 | https://www.starrocks.io/ | 1718031523 |
| 2398 | https://docs.starrocks.org.cn/ | 1718033630 |
| 3741 | https://www.starrocks.io/product/community | 1718030845 |
| 4792 | https://www.starrocks.io/ | 1718033413 |
+------+--------------------------------------------+------------+
5 rows in set (0.07 sec)
发布其他数据
再次运行 gen.py 将向 Redpanda 发布另外五个记录。
python gen.py 5
验证是否已添加数据
由于 Routine Load 作业按计划运行(默认情况下每 10 秒),因此数据将在几秒钟内加载。
SELECT * FROM site_clicks;
+------+--------------------------------------------+------------+
| uid | site | vtime |
+------+--------------------------------------------+------------+
| 6648 | https://www.starrocks.io/blog | 1718205970 |
| 7914 | https://www.starrocks.io/ | 1718206760 |
| 9854 | https://www.starrocks.io/blog | 1718205676 |
| 1186 | https://www.starrocks.io/ | 1718209083 |
| 3305 | https://docs.starrocks.org.cn/ | 1718209083 |
| 2288 | https://www.starrocks.io/blog | 1718206759 |
| 7879 | https://www.starrocks.io/product/community | 1718204280 |
| 2666 | https://www.starrocks.io/ | 1718208842 |
| 5801 | https://www.starrocks.io/ | 1718208783 |
| 8409 | https://www.starrocks.io/ | 1718206889 |
+------+--------------------------------------------+------------+
10 rows in set (0.02 sec)
配置详细信息
现在您已经体验了将 StarRocks 与共享数据一起使用,了解配置非常重要。
CN 配置
此处使用的 CN 配置是默认配置,因为 CN 设计用于共享数据使用。默认配置如下所示。您不需要进行任何更改。
sys_log_level = INFO
# ports for admin, web, heartbeat service
be_port = 9060
be_http_port = 8040
heartbeat_service_port = 9050
brpc_port = 8060
starlet_port = 9070
FE 配置
FE 配置与默认配置略有不同,因为必须配置 FE 以预期数据存储在对象存储中,而不是 BE 节点上的本地磁盘上。
docker-compose.yml 文件在 starrocks-fe 服务的 command 部分生成 FE 配置。
# enable shared data, set storage type, set endpoint
run_mode = shared_data
cloud_native_storage_type = S3
aws_s3_endpoint = minio:9000
# set the path in MinIO
aws_s3_path = starrocks
# credentials for MinIO object read/write
aws_s3_access_key = AAAAAAAAAAAAAAAAAAAA
aws_s3_secret_key = BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB
aws_s3_use_instance_profile = false
aws_s3_use_aws_sdk_default_behavior = false
# Set this to false if you do not want default
# storage created in the object storage using
# the details provided above
enable_load_volume_from_conf = true
此配置文件不包含 FE 的默认条目,仅显示共享数据配置。
非默认 FE 配置设置
许多配置参数都以 s3_ 为前缀。此前缀用于所有与 Amazon S3 兼容的存储类型(例如:S3、GCS 和 MinIO)。使用 Azure Blob Storage 时,前缀为 azure_。
run_mode=shared_data
这启用了共享数据使用。
cloud_native_storage_type=S3
这指定是使用 S3 兼容存储还是 Azure Blob Storage。对于 MinIO,这始终为 S3。
aws_s3_endpoint=minio:9000
MinIO 端点,包括端口号。
aws_s3_path=starrocks
存储桶名称。
aws_s3_access_key=AAAAAAAAAAAAAAAAAAAA
MinIO 访问密钥。
aws_s3_secret_key=BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB
MinIO 访问密钥密钥。
aws_s3_use_instance_profile=false
使用 MinIO 时,使用访问密钥,因此 MinIO 不使用实例配置文件。
aws_s3_use_aws_sdk_default_behavior=false
使用 MinIO 时,此参数始终设置为 false。
enable_load_volume_from_conf=true
如果此值为 true,则使用 MinIO 对象存储创建一个名为 builtin_storage_volume 的 StarRocks 存储卷,并将其设置为您创建的表的默认存储卷。
关于 Routine Load 命令的说明
StarRocks Routine Load 采用许多参数。此处仅描述本教程中使用的参数,其余参数将在更多信息部分中链接。
CREATE ROUTINE LOAD quickstart.clicks ON site_clicks
PROPERTIES
(
"format" = "JSON",
"jsonpaths" ="[\"$.uid\",\"$.site\",\"$.vtime\"]"
)
FROM KAFKA
(
"kafka_broker_list" = "redpanda:29092",
"kafka_topic" = "test2",
"kafka_partitions" = "0",
"kafka_offsets" = "OFFSET_BEGINNING"
);
参数
CREATE ROUTINE LOAD quickstart.clicks ON site_clicks
CREATE ROUTINE LOAD ON 的参数为
- database_name.job_name
- table_name
database_name 是可选的。在本实验中,它是 quickstart,并且已指定。
job_name 是必需的,并且为 clicks
table_name 是必需的,并且为 site_clicks
作业属性
属性 format
"format" = "JSON",
在这种情况下,数据采用 JSON 格式,因此该属性设置为 JSON。其他有效格式为:CSV、JSON 和 Avro。CSV 是默认值。
属性 jsonpaths
"jsonpaths" ="[\"$.uid\",\"$.site\",\"$.vtime\"]"
您要从 JSON 格式数据加载的字段的名称。此参数的值是有效的 JsonPath 表达式。有关更多信息,请参见本页末尾。
数据源属性
kafka_broker_list
"kafka_broker_list" = "redpanda:29092",
Kafka 的 broker 连接信息。格式为 <kafka_broker_name_or_ip>:<broker_ port>。多个 broker 用逗号分隔。
kafka_topic
"kafka_topic" = "test2",
要从中消费的 Kafka topic。
kafka_partitions 和 kafka_offsets
"kafka_partitions" = "0",
"kafka_offsets" = "OFFSET_BEGINNING"
这些属性一起呈现,因为每个 kafka_partitions 条目都需要一个 kafka_offset。
kafka_partitions 是要消费的一个或多个分区的列表。如果未设置此属性,则将消费所有分区。
kafka_offsets 是偏移量的列表,每个偏移量对应于 kafka_partitions 中列出的一个分区。在这种情况下,值为 OFFSET_BEGINNING,这将导致消费所有数据。默认设置为仅消费新数据。
摘要
在本教程中,您
- 在 Docker 中部署了 StarRocks、Reedpanda 和 MinIO
- 创建了 Routine Load 作业以从 Kafka topic 消费数据
- 学习了如何配置使用 MinIO 的 StarRocks 存储卷
更多信息
此实验使用的示例非常简单。Routine Load 还有更多的选项和功能。了解更多。