Apache Hudi Lakehouse
概述
- 使用 Docker Compose 部署对象存储、Apache Spark、Hudi 和 StarRocks
- 将小型数据集加载到 Hudi 中并使用 Apache Spark
- 配置 StarRocks 以使用外部 Catalog 访问 Hive Metastore
- 使用 StarRocks 查询数据所在位置的数据
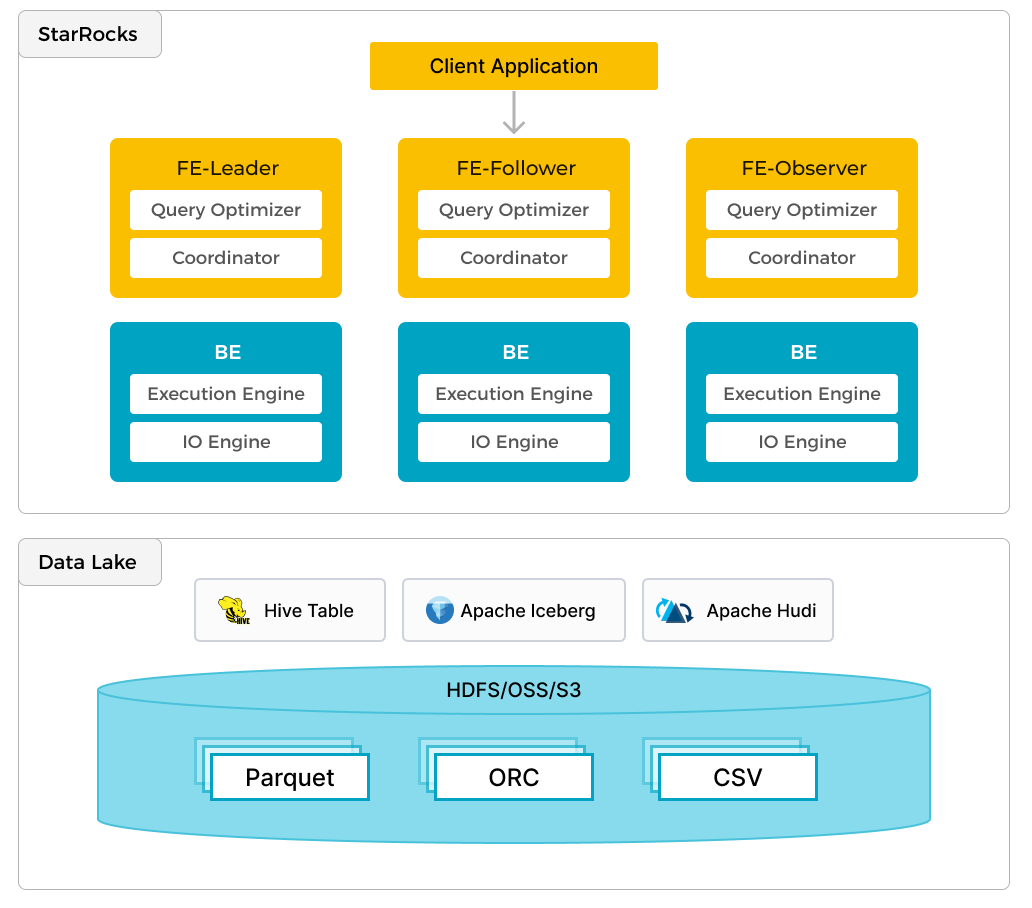
除了对本地数据进行高效分析外,StarRocks 还可以作为计算引擎来分析存储在数据湖(如 Apache Hudi、Apache Iceberg 和 Delta Lake)中的数据。 StarRocks 的一个关键特性是其外部 Catalog,它充当与外部维护的元存储的链接。此功能为用户提供了无缝查询外部数据源的能力,无需数据迁移。 因此,用户可以分析来自不同系统(如 HDFS 和 Amazon S3)的数据,以及各种文件格式(如 Parquet、ORC 和 CSV 等)。
上图显示了一个数据湖分析场景,其中 StarRocks 负责数据计算和分析,数据湖负责数据存储、组织和维护。 数据湖允许用户以开放存储格式存储数据,并使用灵活的模式生成各种 BI、AI、Ad-hoc 和报告用例的“单一可信来源”报告。 StarRocks 充分利用其向量化引擎和 CBO 的优势,显着提高了数据湖分析的性能。
前提条件
StarRocks demo 仓库
将 StarRocks demo 仓库 克隆到您的本地计算机。
本指南中的所有步骤都将从您克隆 demo GitHub 仓库的目录中的 demo/documentation-samples/hudi/ 目录运行。
Docker
- Docker 设置:对于 Mac,请按照 在 Mac 上安装 Docker Desktop 中定义的步骤操作。 对于运行 Spark-SQL 查询,请确保为 Docker 分配至少 5 GB 内存和 4 个 CPU(请参阅 Docker → Preferences → Advanced)。 否则,Spark-SQL 查询可能会因内存问题而被终止。
- 分配给 Docker 的 20 GB 可用磁盘空间
SQL 客户端
您可以使用 Docker 环境中提供的 SQL 客户端,也可以使用系统上的 SQL 客户端。 许多 MySQL 兼容客户端都可以使用。
配置
将目录更改为 demo/documentation-samples/hudi 并查看文件。 这不是关于 Hudi 的教程,因此不会描述每个配置文件; 但对于读者来说,了解在哪里查找如何配置事物非常重要。 在 hudi/ 目录中,您将找到 docker-compose.yml 文件,该文件用于启动和配置 Docker 中的服务。 以下是这些服务的列表和简要描述
Docker 服务
| 服务 | 职责 |
|---|---|
starrocks-fe | 元数据管理、客户端连接、查询计划和调度 |
starrocks-be | 运行查询计划 |
metastore_db | 用于存储 Hive 元数据的 Postgres DB |
hive_metastore | 提供 Apache Hive Metastore |
minio 和 mc | MinIO 对象存储和 MinIO 命令行客户端 |
spark-hudi | 分布式计算和事务数据湖平台 |
配置文件
在 hudi/conf/ 目录中,您将找到已挂载到 spark-hudi 容器中的配置文件。
core-site.xml
此文件包含对象存储相关的设置。 有关此文档末尾的更多信息,请参阅此文件和其他项目的链接。
spark-defaults.conf
Hive、MinIO 和 Spark SQL 的设置。
hudi-defaults.conf
用于消除 spark-shell 中警告的默认文件。
hadoop-metrics2-hbase.properties
用于消除 spark-shell 中警告的空文件。
hadoop-metrics2-s3a-file-system.properties
用于消除 spark-shell 中警告的空文件。
启动 Demo 集群
此演示系统由 StarRocks、Hudi、MinIO 和 Spark 服务组成。 运行 Docker Compose 以启动集群
docker compose up --detach --wait --wait-timeout 60
[+] Running 8/8
✔ Network hudi Created 0.0s
✔ Container hudi-starrocks-fe-1 Healthy 0.1s
✔ Container hudi-minio-1 Healthy 0.1s
✔ Container hudi-metastore_db-1 Healthy 0.1s
✔ Container hudi-starrocks-be-1 Healthy 0.0s
✔ Container hudi-mc-1 Healthy 0.0s
✔ Container hudi-hive-metastore-1 Healthy 0.0s
✔ Container hudi-spark-hudi-1 Healthy 0.1s
运行多个容器后,如果您将其通过管道传输到 jq,则 docker compose ps 输出更容易读取
docker compose ps --format json | \
jq '{Service: .Service, State: .State, Status: .Status}'
{
"Service": "hive-metastore",
"State": "running",
"Status": "Up About a minute (healthy)"
}
{
"Service": "mc",
"State": "running",
"Status": "Up About a minute"
}
{
"Service": "metastore_db",
"State": "running",
"Status": "Up About a minute"
}
{
"Service": "minio",
"State": "running",
"Status": "Up About a minute"
}
{
"Service": "spark-hudi",
"State": "running",
"Status": "Up 33 seconds (healthy)"
}
{
"Service": "starrocks-be",
"State": "running",
"Status": "Up About a minute (healthy)"
}
{
"Service": "starrocks-fe",
"State": "running",
"Status": "Up About a minute (healthy)"
}
配置 MinIO
当您运行 Spark 命令时,您将把正在创建的表的基本路径设置为 s3a URI
val basePath = "s3a://huditest/hudi_coders"
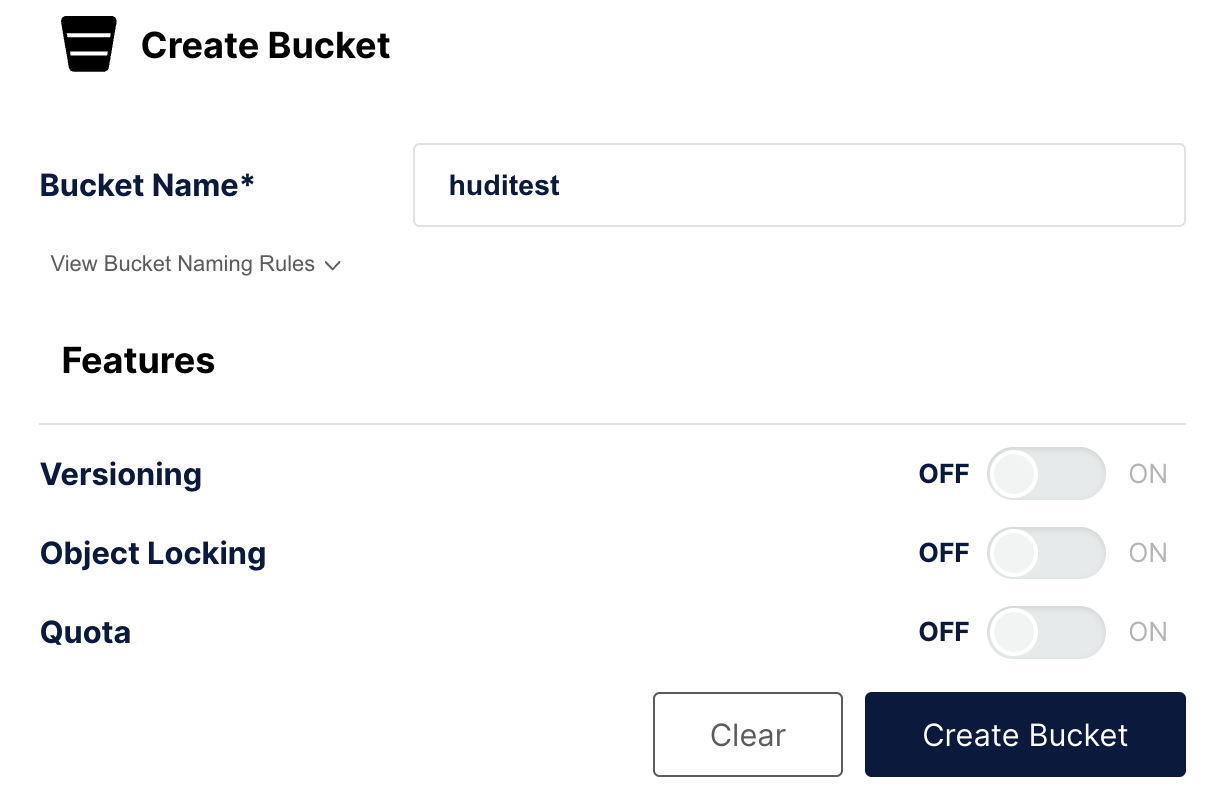
在此步骤中,您将在 MinIO 中创建存储桶 huditest。 MinIO 控制台在端口 9000 上运行。
验证 MinIO 的身份
在浏览器中打开 https://:9000/ 并进行身份验证。 用户名和密码在 docker-compose.yml 中指定; 它们是 admin 和 password。
创建一个存储桶
在左侧导航中,选择 存储桶,然后选择 创建存储桶 +。 将存储桶命名为 huditest 并选择 创建存储桶
创建并填充一个表,然后将其同步到 Hive
从包含 docker-compose.yml 文件的目录运行此命令和任何其他 docker compose 命令。
在 spark-hudi 服务中打开 spark-shell
docker compose exec spark-hudi spark-shell
当 spark-shell 启动时,会有关于非法反射访问的警告。 您可以忽略这些警告。
在 scala> 提示符下运行以下命令以
- 配置此 Spark 会话以加载、处理和写入数据
- 创建一个数据帧并将其写入 Hudi 表
- 同步到 Hive Metastore
import org.apache.spark.sql.functions._
import org.apache.spark.sql.types._
import org.apache.spark.sql.Row
import org.apache.spark.sql.SaveMode._
import org.apache.hudi.DataSourceReadOptions._
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
import scala.collection.JavaConversions._
val schema = StructType( Array(
StructField("language", StringType, true),
StructField("users", StringType, true),
StructField("id", StringType, true)
))
val rowData= Seq(Row("Java", "20000", "a"),
Row("Python", "100000", "b"),
Row("Scala", "3000", "c"))
val df = spark.createDataFrame(rowData,schema)
val databaseName = "hudi_sample"
val tableName = "hudi_coders_hive"
val basePath = "s3a://huditest/hudi_coders"
df.write.format("hudi").
option(org.apache.hudi.config.HoodieWriteConfig.TABLE_NAME, tableName).
option(RECORDKEY_FIELD_OPT_KEY, "id").
option(PARTITIONPATH_FIELD_OPT_KEY, "language").
option(PRECOMBINE_FIELD_OPT_KEY, "users").
option("hoodie.datasource.write.hive_style_partitioning", "true").
option("hoodie.datasource.hive_sync.enable", "true").
option("hoodie.datasource.hive_sync.mode", "hms").
option("hoodie.datasource.hive_sync.database", databaseName).
option("hoodie.datasource.hive_sync.table", tableName).
option("hoodie.datasource.hive_sync.partition_fields", "language").
option("hoodie.datasource.hive_sync.partition_extractor_class", "org.apache.hudi.hive.MultiPartKeysValueExtractor").
option("hoodie.datasource.hive_sync.metastore.uris", "thrift://hive-metastore:9083").
mode(Overwrite).
save(basePath)
System.exit(0)
您将看到一个警告
WARN
org.apache.hudi.metadata.HoodieBackedTableMetadata -
Metadata table was not found at path
s3a://huditest/hudi_coders/.hoodie/metadata
可以忽略此警告,该文件将在 spark-shell 会话期间自动创建。
也会有一个警告
78184 [main] WARN org.apache.hadoop.fs.s3a.S3ABlockOutputStream -
Application invoked the Syncable API against stream writing to
hudi_coders/.hoodie/metadata/files/.files-0000_00000000000000.log.1_0-0-0.
This is unsupported
此警告通知您在使用对象存储时不支持同步为写入打开的日志文件。 该文件仅在关闭时同步。 请参阅 Stack Overflow。
如果以上 spark-shell 会话中的最后一个命令未退出容器,请按 Enter 键,它将退出。
配置 StarRocks
连接到 StarRocks
使用 starrocks-fe 服务提供的 MySQL 客户端连接到 StarRocks,或使用您喜欢的 SQL 客户端并将其配置为使用 localhost:9030 上的 MySQL 协议进行连接。
docker compose exec starrocks-fe \
mysql -P 9030 -h 127.0.0.1 -u root --prompt="StarRocks > "
创建 StarRocks 和 Hudi 之间的链接
本指南末尾有一个链接,其中包含有关外部 Catalog 的更多信息。 此步骤中创建的外部 Catalog 充当与在 Docker 中运行的 Hive Metastore (HMS) 的链接。
CREATE EXTERNAL CATALOG hudi_catalog_hms
PROPERTIES
(
"type" = "hudi",
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "thrift://hive-metastore:9083",
"aws.s3.use_instance_profile" = "false",
"aws.s3.access_key" = "admin",
"aws.s3.secret_key" = "password",
"aws.s3.enable_ssl" = "false",
"aws.s3.enable_path_style_access" = "true",
"aws.s3.endpoint" = "http://minio:9000"
);
Query OK, 0 rows affected (0.59 sec)
使用新的 Catalog
SET CATALOG hudi_catalog_hms;
Query OK, 0 rows affected (0.01 sec)
导航到使用 Spark 插入的数据
SHOW DATABASES;
+--------------------+
| Database |
+--------------------+
| default |
| hudi_sample |
| information_schema |
+--------------------+
2 rows in set (0.40 sec)
USE hudi_sample;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
SHOW TABLES;
+-----------------------+
| Tables_in_hudi_sample |
+-----------------------+
| hudi_coders_hive |
+-----------------------+
1 row in set (0.07 sec)
使用 StarRocks 查询 Hudi 中的数据
运行此查询两次,第一次可能需要大约五秒钟才能完成,因为数据尚未缓存在 StarRocks 中。 第二个查询会非常快。
SELECT * from hudi_coders_hive\G
StarRocks 文档中的一些 SQL 查询以 \G 而不是分号结尾。 \G 使 mysql CLI 垂直呈现查询结果。
许多 SQL 客户端不解释垂直格式输出,因此如果您不使用 mysql CLI,则应将 \G 替换为 ;。
*************************** 1. row ***************************
_hoodie_commit_time: 20240208165522561
_hoodie_commit_seqno: 20240208165522561_0_0
_hoodie_record_key: c
_hoodie_partition_path: language=Scala
_hoodie_file_name: bb29249a-b69d-4c32-843b-b7142d8dc51c-0_0-27-1221_20240208165522561.parquet
language: Scala
users: 3000
id: c
*************************** 2. row ***************************
_hoodie_commit_time: 20240208165522561
_hoodie_commit_seqno: 20240208165522561_2_0
_hoodie_record_key: a
_hoodie_partition_path: language=Java
_hoodie_file_name: 12fc14aa-7dc4-454c-b710-1ad0556c9386-0_2-27-1223_20240208165522561.parquet
language: Java
users: 20000
id: a
*************************** 3. row ***************************
_hoodie_commit_time: 20240208165522561
_hoodie_commit_seqno: 20240208165522561_1_0
_hoodie_record_key: b
_hoodie_partition_path: language=Python
_hoodie_file_name: 51977039-d71e-4dd6-90d4-0c93656dafcf-0_1-27-1222_20240208165522561.parquet
language: Python
users: 100000
id: b
3 rows in set (0.15 sec)
摘要
本教程向您介绍了 StarRocks 外部 Catalog 的使用,向您展示了可以使用 Hudi 外部 Catalog 在数据所在位置查询数据。 许多其他集成可使用 Iceberg、Delta Lake 和 JDBC Catalog。
在本教程中,您
- 在 Docker 中部署了 StarRocks 和 Hudi/Spark/MinIO 环境
- 将小型数据集加载到 Hudi 中并使用 Apache Spark
- 配置了一个 StarRocks 外部 Catalog 以提供对 Hudi Catalog 的访问
- 在 StarRocks 中使用 SQL 查询数据,而无需从数据湖复制数据
更多信息
Apache Hudi 快速入门(包括 Spark)