从 HDFS 加载数据
StarRocks 提供了以下从 HDFS 加载数据的选项
- 使用 INSERT+
FILES()进行同步加载 - 使用 Broker Load 进行异步加载
- 使用 Pipe 进行持续异步加载
这些选项各有优势,以下各节将详细介绍。
在大多数情况下,我们建议您使用 INSERT+FILES() 方法,该方法更易于使用。
但是,INSERT+FILES() 方法目前仅支持 Parquet、ORC 和 CSV 文件格式。 因此,如果您需要加载其他文件格式(如 JSON)的数据,或者在数据加载期间执行数据更改(如 DELETE),则可以求助于 Broker Load。
如果您需要加载大量数据文件,且总数据量很大(例如,超过 100 GB 甚至 1 TB),我们建议您使用 Pipe 方法。Pipe 可以根据文件数量或大小拆分文件,将加载作业分解为较小的顺序任务。 这种方法确保一个文件中的错误不会影响整个加载作业,并最大限度地减少因数据错误而需要重试的次数。
准备工作
准备源数据
请确保要加载到 StarRocks 中的源数据已正确存储在您的 HDFS 集群中。 本主题假设您要将 /user/amber/user_behavior_ten_million_rows.parquet 从 HDFS 加载到 StarRocks 中。
检查权限
只有对这些 StarRocks 表具有 INSERT 权限的用户才能将数据加载到 StarRocks 表中。 如果您没有 INSERT 权限,请按照 GRANT 中提供的说明,将 INSERT 权限授予用于连接到 StarRocks 集群的用户。 语法为 GRANT INSERT ON TABLE <table_name> IN DATABASE <database_name> TO { ROLE <role_name> | USER <user_identity>}。
收集身份验证详细信息
您可以使用简单的身份验证方法与 HDFS 集群建立连接。 要使用简单的身份验证,您需要收集可用于访问 HDFS 集群 NameNode 的帐户的用户名和密码。
使用 INSERT+FILES()
此方法从 v3.1 开始可用,目前仅支持 Parquet、ORC 和 CSV(从 v3.3.0 开始)文件格式。
INSERT+FILES() 的优点
FILES() 可以读取存储在云存储中的文件,基于您指定的路径相关属性,推断文件中数据的表结构,然后从文件中返回数据行。
使用 FILES(),您可以
- 使用 SELECT 直接从 HDFS 查询数据。
- 使用 CREATE TABLE AS SELECT (CTAS) 创建和加载表。
- 使用 INSERT 将数据加载到现有表中。
典型示例
使用 SELECT 直接从 HDFS 查询
使用 SELECT+FILES() 直接从 HDFS 查询可以在创建表之前很好地预览数据集的内容。 例如
- 在不存储数据的情况下预览数据集。
- 查询最小值和最大值,并确定要使用的数据类型。
- 检查
NULL值。
以下示例查询存储在 HDFS 集群中的数据文件 /user/amber/user_behavior_ten_million_rows.parquet
SELECT * FROM FILES
(
"path" = "hdfs://<hdfs_ip>:<hdfs_port>/user/amber/user_behavior_ten_million_rows.parquet",
"format" = "parquet",
"hadoop.security.authentication" = "simple",
"username" = "<hdfs_username>",
"password" = "<hdfs_password>"
)
LIMIT 3;
系统返回以下查询结果
+--------+---------+------------+--------------+---------------------+
| UserID | ItemID | CategoryID | BehaviorType | Timestamp |
+--------+---------+------------+--------------+---------------------+
| 543711 | 829192 | 2355072 | pv | 2017-11-27 08:22:37 |
| 543711 | 2056618 | 3645362 | pv | 2017-11-27 10:16:46 |
| 543711 | 1165492 | 3645362 | pv | 2017-11-27 10:17:00 |
+--------+---------+------------+--------------+---------------------+
注意
请注意,上面返回的列名由 Parquet 文件提供。
使用 CTAS 创建和加载表
这是前一个示例的延续。 前一个查询包含在 CREATE TABLE AS SELECT (CTAS) 中,以使用模式推断自动执行表创建。 这意味着 StarRocks 将推断表结构,创建您想要的表,然后将数据加载到表中。 当将 FILES() 表函数与 Parquet 文件一起使用时,由于 Parquet 格式包含列名,因此不需要创建列名和类型。
注意
使用模式推断时,CREATE TABLE 的语法不允许设置副本数,因此请在创建表之前设置它。 以下示例适用于具有三个副本的系统
ADMIN SET FRONTEND CONFIG ('default_replication_num' = "3");
创建一个数据库并切换到它
CREATE DATABASE IF NOT EXISTS mydatabase;
USE mydatabase;
使用 CTAS 创建表并将数据文件 /user/amber/user_behavior_ten_million_rows.parquet 的数据加载到表中
CREATE TABLE user_behavior_inferred AS
SELECT * FROM FILES
(
"path" = "hdfs://<hdfs_ip>:<hdfs_port>/user/amber/user_behavior_ten_million_rows.parquet",
"format" = "parquet",
"hadoop.security.authentication" = "simple",
"username" = "<hdfs_username>",
"password" = "<hdfs_password>"
);
创建表后,您可以使用 DESCRIBE 查看其架构
DESCRIBE user_behavior_inferred;
系统返回以下查询结果
+--------------+-----------+------+-------+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+--------------+-----------+------+-------+---------+-------+
| UserID | bigint | YES | true | NULL | |
| ItemID | bigint | YES | true | NULL | |
| CategoryID | bigint | YES | true | NULL | |
| BehaviorType | varbinary | YES | false | NULL | |
| Timestamp | varbinary | YES | false | NULL | |
+--------------+-----------+------+-------+---------+-------+
查询表以验证数据是否已加载到其中。 例子
SELECT * from user_behavior_inferred LIMIT 3;
返回以下查询结果,表明数据已成功加载
+--------+--------+------------+--------------+---------------------+
| UserID | ItemID | CategoryID | BehaviorType | Timestamp |
+--------+--------+------------+--------------+---------------------+
| 84 | 56257 | 1879194 | pv | 2017-11-26 05:56:23 |
| 84 | 108021 | 2982027 | pv | 2017-12-02 05:43:00 |
| 84 | 390657 | 1879194 | pv | 2017-11-28 11:20:30 |
+--------+--------+------------+--------------+---------------------+
使用 INSERT 加载到现有表中
您可能想要自定义要插入的表,例如
- 列数据类型、可为空设置或默认值
- 键类型和列
- 数据分区和分桶
注意
创建最有效的表结构需要了解如何使用数据以及列的内容。 本主题不涵盖表设计。 有关表设计的信息,请参见表类型。
在此示例中,我们正在基于对表查询方式以及 Parquet 文件中数据的了解来创建表。 可以通过直接在 HDFS 中查询文件来了解 Parquet 文件中的数据。
- 由于 HDFS 中数据集的查询表明
Timestamp列包含与 VARBINARY 数据类型匹配的数据,因此在以下 DDL 中指定了列类型。 - 通过查询 HDFS 中的数据,您可以发现数据集中没有
NULL值,因此 DDL 不会将任何列设置为可为空。 - 根据对预期查询类型的了解,排序键和分桶列设置为列
UserID。 您的用例可能与此数据不同,因此您可能会决定除了UserID之外或代替它使用ItemID作为排序键。
创建一个数据库并切换到它
CREATE DATABASE IF NOT EXISTS mydatabase;
USE mydatabase;
手动创建表(我们建议该表具有与要从 HDFS 加载的 Parquet 文件相同的结构)
CREATE TABLE user_behavior_declared
(
UserID int(11),
ItemID int(11),
CategoryID int(11),
BehaviorType varchar(65533),
Timestamp varbinary
)
ENGINE = OLAP
DUPLICATE KEY(UserID)
DISTRIBUTED BY HASH(UserID);
显示架构,以便您可以将其与 FILES() 表函数生成的推断架构进行比较
DESCRIBE user_behavior_declared;
+--------------+----------------+------+-------+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+--------------+----------------+------+-------+---------+-------+
| UserID | int | NO | true | NULL | |
| ItemID | int | NO | false | NULL | |
| CategoryID | int | NO | false | NULL | |
| BehaviorType | varchar(65533) | NO | false | NULL | |
| Timestamp | varbinary | NO | false | NULL | |
+--------------+----------------+------+-------+---------+-------+
5 rows in set (0.00 sec)
将您刚刚创建的架构与之前使用 FILES() 表函数推断的架构进行比较。 查看
- 数据类型
- 可为空
- 键字段
为了更好地控制目标表的架构并获得更好的查询性能,我们建议您在生产环境中手动指定表架构。
创建表后,您可以使用 INSERT INTO SELECT FROM FILES() 加载它
INSERT INTO user_behavior_declared
SELECT * FROM FILES
(
"path" = "hdfs://<hdfs_ip>:<hdfs_port>/user/amber/user_behavior_ten_million_rows.parquet",
"format" = "parquet",
"hadoop.security.authentication" = "simple",
"username" = "<hdfs_username>",
"password" = "<hdfs_password>"
);
加载完成后,您可以查询表以验证数据是否已加载到其中。 例子
SELECT * from user_behavior_declared LIMIT 3;
返回以下查询结果,表明数据已成功加载
+--------+---------+------------+--------------+---------------------+
| UserID | ItemID | CategoryID | BehaviorType | Timestamp |
+--------+---------+------------+--------------+---------------------+
| 107 | 1568743 | 4476428 | pv | 2017-11-25 14:29:53 |
| 107 | 470767 | 1020087 | pv | 2017-11-25 14:32:31 |
| 107 | 358238 | 1817004 | pv | 2017-11-25 14:43:23 |
+--------+---------+------------+--------------+---------------------+
检查加载进度
您可以从 StarRocks Information Schema 中的 loads 视图查询 INSERT 作业的进度。 从 v3.1 开始支持此功能。 例子
SELECT * FROM information_schema.loads ORDER BY JOB_ID DESC;
有关 loads 视图中提供的字段的信息,请参阅 loads。
如果您提交了多个加载作业,您可以按与作业关联的 LABEL 进行过滤。 例子
SELECT * FROM information_schema.loads WHERE LABEL = 'insert_0d86c3f9-851f-11ee-9c3e-00163e044958' \G
*************************** 1. row ***************************
JOB_ID: 10214
LABEL: insert_0d86c3f9-851f-11ee-9c3e-00163e044958
DATABASE_NAME: mydatabase
STATE: FINISHED
PROGRESS: ETL:100%; LOAD:100%
TYPE: INSERT
PRIORITY: NORMAL
SCAN_ROWS: 10000000
FILTERED_ROWS: 0
UNSELECTED_ROWS: 0
SINK_ROWS: 10000000
ETL_INFO:
TASK_INFO: resource:N/A; timeout(s):300; max_filter_ratio:0.0
CREATE_TIME: 2023-11-17 15:58:14
ETL_START_TIME: 2023-11-17 15:58:14
ETL_FINISH_TIME: 2023-11-17 15:58:14
LOAD_START_TIME: 2023-11-17 15:58:14
LOAD_FINISH_TIME: 2023-11-17 15:58:18
JOB_DETAILS: {"All backends":{"0d86c3f9-851f-11ee-9c3e-00163e044958":[10120]},"FileNumber":0,"FileSize":0,"InternalTableLoadBytes":311710786,"InternalTableLoadRows":10000000,"ScanBytes":581574034,"ScanRows":10000000,"TaskNumber":1,"Unfinished backends":{"0d86c3f9-851f-11ee-9c3e-00163e044958":[]}}
ERROR_MSG: NULL
TRACKING_URL: NULL
TRACKING_SQL: NULL
REJECTED_RECORD_PATH: NULL
注意
INSERT 是一个同步命令。 如果 INSERT 作业仍在运行,您需要打开另一个会话来检查其执行状态。
使用 Broker Load
异步 Broker Load 进程处理与 HDFS 的连接、提取数据并将数据存储在 StarRocks 中。
此方法支持以下文件格式
- Parquet
- ORC
- CSV
- JSON(从 v3.2.3 开始支持)
Broker Load 的优点
- Broker Load 在后台运行,客户端无需保持连接即可继续作业。
- Broker Load 首选用于长时间运行的作业,默认超时时间为 4 小时。
- 除了 Parquet 和 ORC 文件格式外,Broker Load 还支持 CSV 文件格式和 JSON 文件格式(JSON 文件格式从 v3.2.3 开始支持)。
数据流
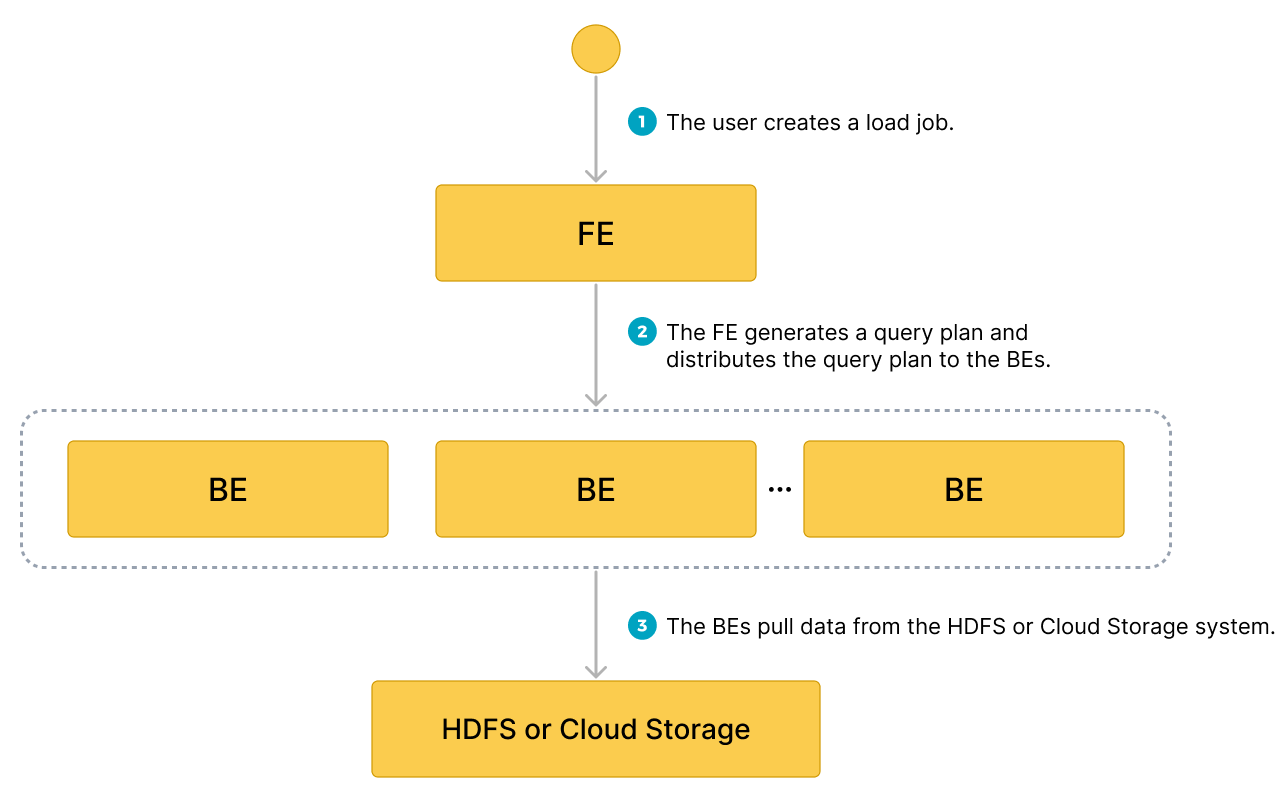
- 用户创建一个加载作业。
- 前端 (FE) 创建一个查询计划,并将该计划分发到后端节点 (BE) 或计算节点 (CN)。
- BE 或 CN 从源中提取数据并将数据加载到 StarRocks 中。
典型示例
创建表,启动一个加载进程,该进程从 HDFS 提取数据文件 /user/amber/user_behavior_ten_million_rows.parquet,并验证数据加载的进度和成功。
创建一个数据库和一个表
创建一个数据库并切换到它
CREATE DATABASE IF NOT EXISTS mydatabase;
USE mydatabase;
手动创建一个表(我们建议该表具有与您要从 HDFS 加载的 Parquet 文件相同的结构)
CREATE TABLE user_behavior
(
UserID int(11),
ItemID int(11),
CategoryID int(11),
BehaviorType varchar(65533),
Timestamp varbinary
)
ENGINE = OLAP
DUPLICATE KEY(UserID)
DISTRIBUTED BY HASH(UserID);
启动 Broker Load
运行以下命令启动一个 Broker Load 作业,该作业将数据从数据文件 /user/amber/user_behavior_ten_million_rows.parquet 加载到 user_behavior 表
LOAD LABEL user_behavior
(
DATA INFILE("hdfs://<hdfs_ip>:<hdfs_port>/user/amber/user_behavior_ten_million_rows.parquet")
INTO TABLE user_behavior
FORMAT AS "parquet"
)
WITH BROKER
(
"hadoop.security.authentication" = "simple",
"username" = "<hdfs_username>",
"password" = "<hdfs_password>"
)
PROPERTIES
(
"timeout" = "72000"
);
此作业有四个主要部分
LABEL:一个字符串,用于查询加载作业的状态。LOAD声明:源 URI、源数据格式和目标表名。BROKER:源的连接详细信息。PROPERTIES:超时值和任何其他要应用于加载作业的属性。
有关详细语法和参数说明,请参阅 BROKER LOAD。
检查加载进度
您可以从 information_schema.loads 视图查询 Broker Load 作业的进度。 从 v3.1 开始支持此功能。
SELECT * FROM information_schema.loads;
有关 loads 视图中提供的字段的信息,请参见 Information Schema)。
如果您提交了多个加载作业,您可以按与作业关联的 LABEL 进行过滤。 例子
SELECT * FROM information_schema.loads WHERE LABEL = 'user_behavior';
在下面的输出中,user_behavior 加载作业有两个条目
- 第一个记录显示状态为
CANCELLED。滚动到ERROR_MSG,您可以看到该作业由于listPath failed而失败。 - 第二个记录显示状态为
FINISHED,这意味着该作业已成功。
JOB_ID|LABEL |DATABASE_NAME|STATE |PROGRESS |TYPE |PRIORITY|SCAN_ROWS|FILTERED_ROWS|UNSELECTED_ROWS|SINK_ROWS|ETL_INFO|TASK_INFO |CREATE_TIME |ETL_START_TIME |ETL_FINISH_TIME |LOAD_START_TIME |LOAD_FINISH_TIME |JOB_DETAILS |ERROR_MSG |TRACKING_URL|TRACKING_SQL|REJECTED_RECORD_PATH|
------+-------------------------------------------+-------------+---------+-------------------+------+--------+---------+-------------+---------------+---------+--------+----------------------------------------------------+-------------------+-------------------+-------------------+-------------------+-------------------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+--------------------------------------+------------+------------+--------------------+
10121|user_behavior |mydatabase |CANCELLED|ETL:N/A; LOAD:N/A |BROKER|NORMAL | 0| 0| 0| 0| |resource:N/A; timeout(s):72000; max_filter_ratio:0.0|2023-08-10 14:59:30| | | |2023-08-10 14:59:34|{"All backends":{},"FileNumber":0,"FileSize":0,"InternalTableLoadBytes":0,"InternalTableLoadRows":0,"ScanBytes":0,"ScanRows":0,"TaskNumber":0,"Unfinished backends":{}} |type:ETL_RUN_FAIL; msg:listPath failed| | | |
10106|user_behavior |mydatabase |FINISHED |ETL:100%; LOAD:100%|BROKER|NORMAL | 86953525| 0| 0| 86953525| |resource:N/A; timeout(s):72000; max_filter_ratio:0.0|2023-08-10 14:50:15|2023-08-10 14:50:19|2023-08-10 14:50:19|2023-08-10 14:50:19|2023-08-10 14:55:10|{"All backends":{"a5fe5e1d-d7d0-4826-ba99-c7348f9a5f2f":[10004]},"FileNumber":1,"FileSize":1225637388,"InternalTableLoadBytes":2710603082,"InternalTableLoadRows":86953525,"ScanBytes":1225637388,"ScanRows":86953525,"TaskNumber":1,"Unfinished backends":{"a5| | | | |
在确认加载作业已完成后,您可以检查目标表的子集,以查看数据是否已成功加载。 例子
SELECT * from user_behavior LIMIT 3;
返回以下查询结果,表明数据已成功加载
+--------+---------+------------+--------------+---------------------+
| UserID | ItemID | CategoryID | BehaviorType | Timestamp |
+--------+---------+------------+--------------+---------------------+
| 142 | 2869980 | 2939262 | pv | 2017-11-25 03:43:22 |
| 142 | 2522236 | 1669167 | pv | 2017-11-25 15:14:12 |
| 142 | 3031639 | 3607361 | pv | 2017-11-25 15:19:25 |
+--------+---------+------------+--------------+---------------------+
使用 Pipe
从 v3.2 开始,StarRocks 提供了 Pipe 加载方法,该方法目前仅支持 Parquet 和 ORC 文件格式。
Pipe 的优势
Pipe 非常适合连续数据加载和大规模数据加载
-
微批量的大规模数据加载有助于降低因数据错误而导致的重试成本。
借助 Pipe,StarRocks 可以高效地加载大量数据文件,且总数据量很大。 Pipe 自动根据文件数量或大小拆分文件,将加载作业分解为较小的顺序任务。 这种方法确保一个文件中的错误不会影响整个加载作业。 Pipe 记录每个文件的加载状态,使您可以轻松识别和修复包含错误的文件。 通过最大限度地减少因数据错误而需要重试的次数,此方法有助于降低成本。
-
连续数据加载有助于减少人力。
Pipe 可帮助您将新的或更新的数据文件写入特定位置,并不断地将这些文件中的新数据加载到 StarRocks 中。 使用
"AUTO_INGEST" = "TRUE"指定创建 Pipe 作业后,它将不断监视存储在指定路径中的数据文件的更改,并自动将新的或更新的数据从数据文件加载到目标 StarRocks 表中。
此外,Pipe 还执行文件唯一性检查,以帮助防止重复数据加载。在加载过程中,Pipe 根据文件名和摘要检查每个数据文件的唯一性。 如果具有特定文件名和摘要的文件已由 Pipe 作业处理,则 Pipe 作业将跳过所有后续具有相同文件名和摘要的文件。 请注意HDFS 使用 LastModifiedTime作为文件摘要。
每个数据文件的加载状态都会被记录并保存到 information_schema.pipe_files 视图中。在删除与该视图关联的 Pipe 作业后,有关在该作业中加载的文件的记录也将被删除。
数据流
Pipe 非常适合连续数据加载和大规模数据加载
-
微批量的大规模数据加载有助于降低因数据错误而导致的重试成本。
借助 Pipe,StarRocks 可以高效地加载大量数据文件,且总数据量很大。 Pipe 自动根据文件数量或大小拆分文件,将加载作业分解为较小的顺序任务。 这种方法确保一个文件中的错误不会影响整个加载作业。 Pipe 记录每个文件的加载状态,使您可以轻松识别和修复包含错误的文件。 通过最大限度地减少因数据错误而需要重试的次数,此方法有助于降低成本。
-
连续数据加载有助于减少人力。
Pipe 可帮助您将新的或更新的数据文件写入特定位置,并不断地将这些文件中的新数据加载到 StarRocks 中。 使用
"AUTO_INGEST" = "TRUE"指定创建 Pipe 作业后,它将不断监视存储在指定路径中的数据文件的更改,并自动将新的或更新的数据从数据文件加载到目标 StarRocks 表中。
此外,Pipe 还执行文件唯一性检查,以帮助防止重复数据加载。 在加载过程中,Pipe 根据文件名和摘要检查每个数据文件的唯一性。 如果具有特定文件名和摘要的文件已由 Pipe 作业处理,则 Pipe 作业将跳过所有后续具有相同文件名和摘要的文件。 请注意,HDFS 使用 LastModifiedTime 作为文件摘要。
每个数据文件的加载状态都会被记录并保存到 information_schema.pipe_files 视图中。在删除与该视图关联的 Pipe 作业后,有关在该作业中加载的文件的记录也将被删除。
数据流
Pipe 和 INSERT+FILES() 之间的差异
Pipe 作业根据每个数据文件的大小和行数拆分为一个或多个事务。 用户可以在加载过程中查询中间结果。 相比之下,INSERT+FILES() 作业作为单个事务处理,用户无法在加载过程中查看数据。
文件加载顺序
对于每个 Pipe 作业,StarRocks 维护一个文件队列,从中提取和加载数据文件作为微批处理。 Pipe 不保证数据文件以与上传顺序相同的顺序加载。 因此,较新的数据可能会在较旧的数据之前加载。
典型示例
创建一个数据库和一个表
创建一个数据库并切换到它
CREATE DATABASE IF NOT EXISTS mydatabase;
USE mydatabase;
手动创建表(我们建议该表具有与要从 HDFS 加载的 Parquet 文件相同的结构)
CREATE TABLE user_behavior_replica
(
UserID int(11),
ItemID int(11),
CategoryID int(11),
BehaviorType varchar(65533),
Timestamp varbinary
)
ENGINE = OLAP
DUPLICATE KEY(UserID)
DISTRIBUTED BY HASH(UserID);
启动一个 Pipe 作业
运行以下命令启动一个 Pipe 作业,该作业将数据从数据文件 /user/amber/user_behavior_ten_million_rows.parquet 加载到 user_behavior_replica 表
CREATE PIPE user_behavior_replica
PROPERTIES
(
"AUTO_INGEST" = "TRUE"
)
AS
INSERT INTO user_behavior_replica
SELECT * FROM FILES
(
"path" = "hdfs://<hdfs_ip>:<hdfs_port>/user/amber/user_behavior_ten_million_rows.parquet",
"format" = "parquet",
"hadoop.security.authentication" = "simple",
"username" = "<hdfs_username>",
"password" = "<hdfs_password>"
);
此作业有四个主要部分
pipe_name: Pipe 的名称。Pipe 名称在 Pipe 所属的数据库中必须是唯一的。INSERT_SQL: 用于将数据从指定的源数据文件加载到目标表的 INSERT INTO SELECT FROM FILES 语句。PROPERTIES:一组可选参数,用于指定如何执行 pipe。 这些参数包括AUTO_INGEST、POLL_INTERVAL、BATCH_SIZE和BATCH_FILES。 以"key" = "value"格式指定这些属性。
有关详细的语法和参数说明,请参阅 CREATE PIPE。
检查加载进度
-
使用 SHOW PIPES 查询 Pipe 作业的进度。
SHOW PIPES;如果您提交了多个加载作业,则可以按与该作业关联的
NAME进行筛选。 例子SHOW PIPES WHERE NAME = 'user_behavior_replica' \G
*************************** 1. row ***************************
DATABASE_NAME: mydatabase
PIPE_ID: 10252
PIPE_NAME: user_behavior_replica
STATE: RUNNING
TABLE_NAME: mydatabase.user_behavior_replica
LOAD_STATUS: {"loadedFiles":1,"loadedBytes":132251298,"loadingFiles":0,"lastLoadedTime":"2023-11-17 16:13:22"}
LAST_ERROR: NULL
CREATED_TIME: 2023-11-17 16:13:15
1 row in set (0.00 sec) -
从 StarRocks Information Schema 中的
pipes视图查询 Pipe 作业的进度。SELECT * FROM information_schema.pipes;如果您提交了多个加载作业,则可以按与该作业关联的
PIPE_NAME进行筛选。 例子SELECT * FROM information_schema.pipes WHERE pipe_name = 'user_behavior_replica' \G
*************************** 1. row ***************************
DATABASE_NAME: mydatabase
PIPE_ID: 10252
PIPE_NAME: user_behavior_replica
STATE: RUNNING
TABLE_NAME: mydatabase.user_behavior_replica
LOAD_STATUS: {"loadedFiles":1,"loadedBytes":132251298,"loadingFiles":0,"lastLoadedTime":"2023-11-17 16:13:22"}
LAST_ERROR:
CREATED_TIME: 2023-11-17 16:13:15
1 row in set (0.00 sec)
检查文件状态
您可以从 StarRocks 信息模式中的 pipe_files 视图查询已加载文件的加载状态。
SELECT * FROM information_schema.pipe_files;
如果您提交了多个加载作业,则可以按与该作业关联的 PIPE_NAME 进行筛选。 例子
SELECT * FROM information_schema.pipe_files WHERE pipe_name = 'user_behavior_replica' \G
*************************** 1. row ***************************
DATABASE_NAME: mydatabase
PIPE_ID: 10252
PIPE_NAME: user_behavior_replica
FILE_NAME: hdfs://172.26.195.67:9000/user/amber/user_behavior_ten_million_rows.parquet
FILE_VERSION: 1700035418838
FILE_SIZE: 132251298
LAST_MODIFIED: 2023-11-15 08:03:38
LOAD_STATE: FINISHED
STAGED_TIME: 2023-11-17 16:13:16
START_LOAD_TIME: 2023-11-17 16:13:17
FINISH_LOAD_TIME: 2023-11-17 16:13:22
ERROR_MSG:
1 row in set (0.02 sec)
管理 Pipes
您可以更改、暂停或恢复、删除或查询您创建的 pipes,并重试加载特定的数据文件。 有关更多信息,请参见 ALTER PIPE、SUSPEND or RESUME PIPE、DROP PIPE、SHOW PIPES 和 RETRY FILE。