从 Microsoft Azure Storage 加载数据
StarRocks 提供了以下选项用于从 Azure 加载数据
- 使用 INSERT+
FILES()进行同步加载 - 使用 Broker Load 进行异步加载
这些选项各有优势,以下各节将详细介绍。
在大多数情况下,我们建议您使用 INSERT+FILES() 方法,该方法更易于使用。
但是,INSERT+FILES() 方法目前仅支持 Parquet、ORC 和 CSV 文件格式。 因此,如果您需要加载其他文件格式的数据(例如 JSON),或者在数据加载期间执行数据更改(例如 DELETE),您可以求助于 Broker Load。
准备工作
准备源数据
确保要加载到 StarRocks 中的源数据已正确存储在 Azure 存储帐户中的容器内。
在本主题中,假设您要加载存储在 Azure Data Lake Storage Gen2 (ADLS Gen2) 存储帐户 (starrocks) 中的容器 (starrocks-container) 的根目录中的 Parquet 格式的示例数据集 (user_behavior_ten_million_rows.parquet) 的数据。
检查权限
只有对这些 StarRocks 表具有 INSERT 权限的用户才能将数据加载到 StarRocks 表中。 如果您没有 INSERT 权限,请按照 GRANT 中提供的说明,将 INSERT 权限授予用于连接到 StarRocks 集群的用户。 语法为 GRANT INSERT ON TABLE <table_name> IN DATABASE <database_name> TO { ROLE <role_name> | USER <user_identity>}。
收集身份验证详细信息
本主题中的示例使用共享密钥身份验证方法。 为了确保您有权从 ADLS Gen2 读取数据,我们建议您阅读 Azure Data Lake Storage Gen2 > 共享密钥(存储帐户的访问密钥),以了解您需要配置的身份验证参数。
简而言之,如果您使用共享密钥身份验证,则需要收集以下信息
- 您的 ADLS Gen2 存储帐户的用户名
- 您的 ADLS Gen2 存储帐户的共享密钥
有关所有可用身份验证方法的信息,请参阅 验证到 Azure 云存储。
使用 INSERT+FILES()
此方法从 v3.2 开始可用,目前仅支持 Parquet、ORC 和 CSV(从 v3.3.0 开始支持)文件格式。
INSERT+FILES() 的优点
FILES() 可以读取存储在云存储中的文件,根据您指定的路径相关属性,推断文件中数据的表模式,然后将文件中的数据作为数据行返回。
使用 FILES(),您可以
- 使用 SELECT 直接从 Azure 查询数据。
- 使用 CREATE TABLE AS SELECT (CTAS) 创建和加载表。
- 使用 INSERT 将数据加载到现有表中。
典型示例
使用 SELECT 直接从 Azure 查询
使用 SELECT+FILES() 直接从 Azure 查询可以很好地预览数据集的内容,然后再创建表。 例如
- 在不存储数据的情况下预览数据集。
- 查询最小值和最大值,并确定要使用的数据类型。
- 检查
NULL值。
以下示例查询存储在存储帐户 starrocks 中的容器 starrocks-container 中的示例数据集 user_behavior_ten_million_rows.parquet
SELECT * FROM FILES
(
"path" = "abfss://starrocks-container@starrocks.dfs.core.windows.net/user_behavior_ten_million_rows.parquet",
"format" = "parquet",
"azure.adls2.storage_account" = "starrocks",
"azure.adls2.shared_key" = "xxxxxxxxxxxxxxxxxx"
)
LIMIT 3;
系统返回类似于以下的查询结果
+--------+---------+------------+--------------+---------------------+
| UserID | ItemID | CategoryID | BehaviorType | Timestamp |
+--------+---------+------------+--------------+---------------------+
| 543711 | 829192 | 2355072 | pv | 2017-11-27 08:22:37 |
| 543711 | 2056618 | 3645362 | pv | 2017-11-27 10:16:46 |
| 543711 | 1165492 | 3645362 | pv | 2017-11-27 10:17:00 |
+--------+---------+------------+--------------+---------------------+
注意
请注意,上面返回的列名由 Parquet 文件提供。
使用 CTAS 创建和加载表
这是前一个示例的延续。 前一个查询包含在 CREATE TABLE AS SELECT (CTAS) 中,以使用模式推断自动执行表创建。 这意味着 StarRocks 将推断表模式,创建您想要的表,然后将数据加载到表中。 使用 FILES() 表函数和 Parquet 文件时,无需创建表,因为 Parquet 格式包含列名。
注意
使用模式推断时,CREATE TABLE 的语法不允许设置副本数。 如果您使用的是 StarRocks 共享无架构群集,请在创建表之前设置副本数。 以下示例适用于具有三个副本的系统
ADMIN SET FRONTEND CONFIG ('default_replication_num' = "3");
创建一个数据库并切换到它
CREATE DATABASE IF NOT EXISTS mydatabase;
USE mydatabase;
使用 CTAS 创建一个表,并将示例数据集 user_behavior_ten_million_rows.parquet 的数据加载到表中,该数据集存储在存储帐户 starrocks 中的容器 starrocks-container 中
CREATE TABLE user_behavior_inferred AS
SELECT * FROM FILES
(
"path" = "abfss://starrocks-container@starrocks.dfs.core.windows.net/user_behavior_ten_million_rows.parquet",
"format" = "parquet",
"azure.adls2.storage_account" = "starrocks",
"azure.adls2.shared_key" = "xxxxxxxxxxxxxxxxxx"
);
创建表后,您可以使用 DESCRIBE 查看其架构
DESCRIBE user_behavior_inferred;
系统返回以下查询结果
+--------------+-----------+------+-------+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+--------------+-----------+------+-------+---------+-------+
| UserID | bigint | YES | true | NULL | |
| ItemID | bigint | YES | true | NULL | |
| CategoryID | bigint | YES | true | NULL | |
| BehaviorType | varbinary | YES | false | NULL | |
| Timestamp | varbinary | YES | false | NULL | |
+--------------+-----------+------+-------+---------+-------+
查询表以验证数据是否已加载到其中。 例子
SELECT * from user_behavior_inferred LIMIT 3;
返回以下查询结果,表明数据已成功加载
+--------+--------+------------+--------------+---------------------+
| UserID | ItemID | CategoryID | BehaviorType | Timestamp |
+--------+--------+------------+--------------+---------------------+
| 84 | 162325 | 2939262 | pv | 2017-12-02 05:41:41 |
| 84 | 232622 | 4148053 | pv | 2017-11-27 04:36:10 |
| 84 | 595303 | 903809 | pv | 2017-11-26 08:03:59 |
+--------+--------+------------+--------------+---------------------+
使用 INSERT 加载到现有表中
您可能想要自定义要插入的表,例如
- 列数据类型、可为空设置或默认值
- 键类型和列
- 数据分区和分桶
注意
创建最高效的表结构需要了解如何使用数据和列的内容。 本主题不涉及表设计。 有关表设计的信息,请参阅 表类型。
在本示例中,我们正在根据对表查询方式以及 Parquet 文件中数据的了解来创建表。 可以通过直接在 Azure 中查询文件来获得对 Parquet 文件中数据的了解。
- 由于 Azure 中数据集的查询表明
Timestamp列包含与 VARBINARY 数据类型匹配的数据,因此以下 DDL 中指定了列类型。 - 通过查询 Azure 中的数据,您可以发现数据集中没有
NULL值,因此 DDL 不会将任何列设置为可为空。 - 根据对预期查询类型的了解,排序键和分桶列设置为
UserID列。 您的用例可能与此数据不同,因此您可能会决定除了UserID之外或代替UserID使用ItemID作为排序键。
创建一个数据库并切换到它
CREATE DATABASE IF NOT EXISTS mydatabase;
USE mydatabase;
手动创建一个表(我们建议该表具有与您要从 Azure 加载的 Parquet 文件相同的架构)
CREATE TABLE user_behavior_declared
(
UserID int(11),
ItemID int(11),
CategoryID int(11),
BehaviorType varchar(65533),
Timestamp varbinary
)
ENGINE = OLAP
DUPLICATE KEY(UserID)
DISTRIBUTED BY HASH(UserID);
显示架构,以便您可以将其与 FILES() 表函数生成的推断架构进行比较
DESCRIBE user_behavior_declared;
+--------------+----------------+------+-------+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+--------------+----------------+------+-------+---------+-------+
| UserID | int | NO | true | NULL | |
| ItemID | int | NO | false | NULL | |
| CategoryID | int | NO | false | NULL | |
| BehaviorType | varchar(65533) | NO | false | NULL | |
| Timestamp | varbinary | NO | false | NULL | |
+--------------+----------------+------+-------+---------+-------+
5 rows in set (0.00 sec)
将您刚刚创建的架构与之前使用 FILES() 表函数推断的架构进行比较。 查看
- 数据类型
- 可为空
- 键字段
为了更好地控制目标表的架构并获得更好的查询性能,我们建议您在生产环境中手动指定表架构。
创建表后,您可以使用 INSERT INTO SELECT FROM FILES() 加载它
INSERT INTO user_behavior_declared
SELECT * FROM FILES
(
"path" = "abfss://starrocks-container@starrocks.dfs.core.windows.net/user_behavior_ten_million_rows.parquet",
"format" = "parquet",
"azure.adls2.storage_account" = "starrocks",
"azure.adls2.shared_key" = "xxxxxxxxxxxxxxxxxx"
);
加载完成后,您可以查询表以验证数据是否已加载到其中。 例子
SELECT * from user_behavior_declared LIMIT 3;
系统返回类似于以下的查询结果,表明数据已成功加载
+--------+---------+------------+--------------+---------------------+
| UserID | ItemID | CategoryID | BehaviorType | Timestamp |
+--------+---------+------------+--------------+---------------------+
| 142 | 2869980 | 2939262 | pv | 2017-11-25 03:43:22 |
| 142 | 2522236 | 1669167 | pv | 2017-11-25 15:14:12 |
| 142 | 3031639 | 3607361 | pv | 2017-11-25 15:19:25 |
+--------+---------+------------+--------------+---------------------+
检查加载进度
您可以从 StarRocks Information Schema 中的 loads 视图查询 INSERT 作业的进度。 从 v3.1 开始支持此功能。 例子
SELECT * FROM information_schema.loads ORDER BY JOB_ID DESC;
有关 loads 视图中提供的字段的信息,请参阅 loads。
如果您提交了多个加载作业,您可以按与作业关联的 LABEL 进行过滤。 例子
SELECT * FROM information_schema.loads WHERE LABEL = 'insert_f3fc2298-a553-11ee-92f4-00163e0842bd' \G
*************************** 1. row ***************************
JOB_ID: 10193
LABEL: insert_f3fc2298-a553-11ee-92f4-00163e0842bd
DATABASE_NAME: mydatabase
STATE: FINISHED
PROGRESS: ETL:100%; LOAD:100%
TYPE: INSERT
PRIORITY: NORMAL
SCAN_ROWS: 10000000
FILTERED_ROWS: 0
UNSELECTED_ROWS: 0
SINK_ROWS: 10000000
ETL_INFO:
TASK_INFO: resource:N/A; timeout(s):300; max_filter_ratio:0.0
CREATE_TIME: 2023-12-28 15:37:38
ETL_START_TIME: 2023-12-28 15:37:38
ETL_FINISH_TIME: 2023-12-28 15:37:38
LOAD_START_TIME: 2023-12-28 15:37:38
LOAD_FINISH_TIME: 2023-12-28 15:39:35
JOB_DETAILS: {"All backends":{"f3fc2298-a553-11ee-92f4-00163e0842bd":[10120]},"FileNumber":0,"FileSize":0,"InternalTableLoadBytes":581730322,"InternalTableLoadRows":10000000,"ScanBytes":581574034,"ScanRows":10000000,"TaskNumber":1,"Unfinished backends":{"f3fc2298-a553-11ee-92f4-00163e0842bd":[]}}
ERROR_MSG: NULL
TRACKING_URL: NULL
TRACKING_SQL: NULL
REJECTED_RECORD_PATH: NULL
注意
INSERT 是一个同步命令。 如果 INSERT 作业仍在运行,您需要打开另一个会话来检查其执行状态。
使用 Broker Load
异步 Broker Load 进程处理与 Azure 的连接、提取数据并将数据存储在 StarRocks 中。
此方法支持以下文件格式
- Parquet
- ORC
- CSV
- JSON(从 v3.2.3 开始支持)
Broker Load 的优点
- Broker Load 在后台运行,客户端无需保持连接即可继续作业。
- Broker Load 是长时间运行作业的首选,默认超时时间为 4 小时。
- 除了 Parquet 和 ORC 文件格式外,Broker Load 还支持 CSV 文件格式和 JSON 文件格式(JSON 文件格式从 v3.2.3 开始支持)。
数据流
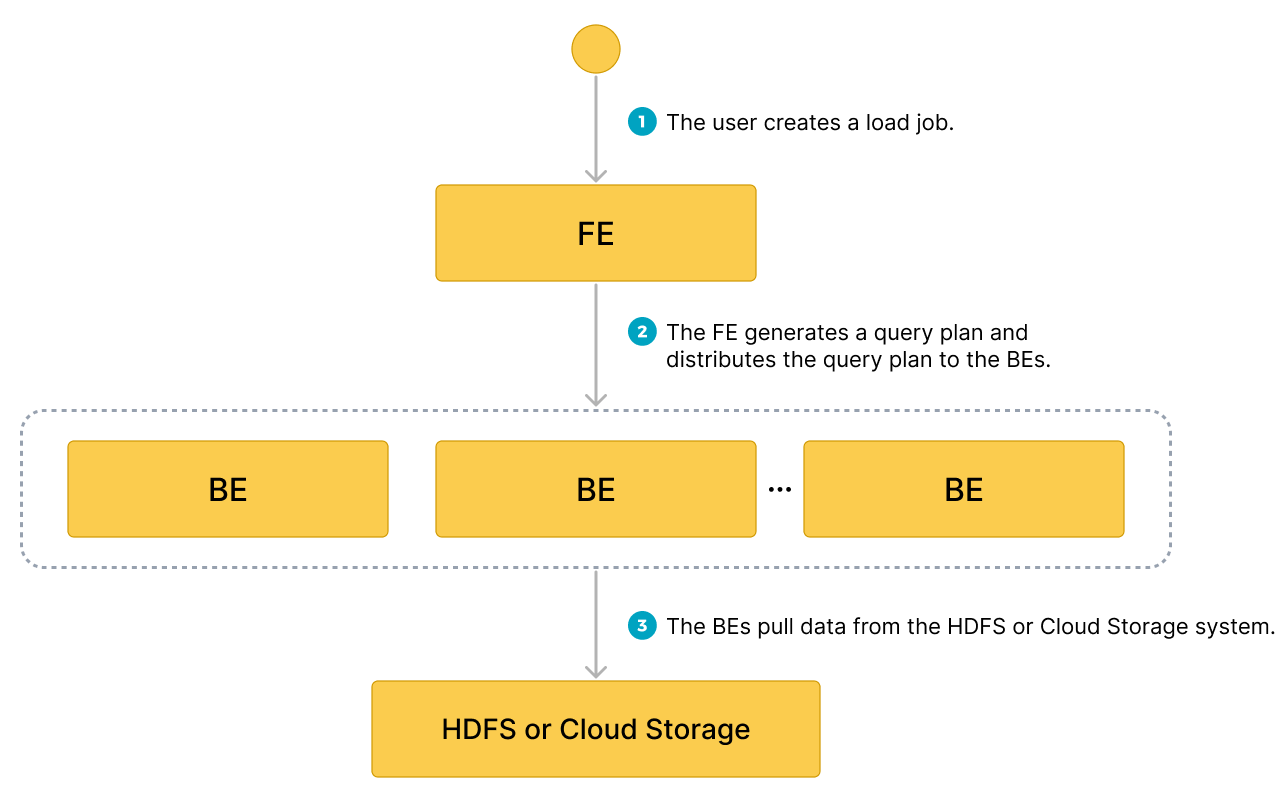
- 用户创建一个加载作业。
- 前端 (FE) 创建一个查询计划,并将该计划分发到后端节点 (BE) 或计算节点 (CN)。
- BE 或 CN 从源中提取数据并将数据加载到 StarRocks 中。
典型示例
创建一个表,启动一个加载进程,该进程从 Azure 提取示例数据集 user_behavior_ten_million_rows.parquet,并验证数据加载的进度和成功情况。
创建一个数据库和一个表
连接到您的 StarRocks 集群。 然后,创建一个数据库并切换到它
CREATE DATABASE IF NOT EXISTS mydatabase;
USE mydatabase;
手动创建一个表(我们建议该表具有与您要从 Azure 加载的 Parquet 文件相同的架构)
CREATE TABLE user_behavior
(
UserID int(11),
ItemID int(11),
CategoryID int(11),
BehaviorType varchar(65533),
Timestamp varbinary
)
ENGINE = OLAP
DUPLICATE KEY(UserID)
DISTRIBUTED BY HASH(UserID);
启动 Broker Load
运行以下命令以启动 Broker Load 作业,该作业将数据从示例数据集 user_behavior_ten_million_rows.parquet 加载到 user_behavior 表
LOAD LABEL user_behavior
(
DATA INFILE("abfss://starrocks-container@starrocks.dfs.core.windows.net/user_behavior_ten_million_rows.parquet")
INTO TABLE user_behavior
FORMAT AS "parquet"
)
WITH BROKER
(
"azure.adls2.storage_account" = "starrocks",
"azure.adls2.shared_key" = "xxxxxxxxxxxxxxxxxx"
)
PROPERTIES
(
"timeout" = "3600"
);
此作业有四个主要部分
LABEL:一个字符串,用于查询加载作业的状态。LOAD声明:源 URI、源数据格式和目标表名。BROKER:源的连接详细信息。PROPERTIES:超时值和任何其他要应用于加载作业的属性。
有关详细语法和参数说明,请参阅 BROKER LOAD。
检查加载进度
您可以从 StarRocks Information Schema 中的 loads 视图查询 Broker Load 作业的进度。 从 v3.1 开始支持此功能。
SELECT * FROM information_schema.loads \G
有关 loads 视图中提供的字段的信息,请参阅 loads。
如果您提交了多个加载作业,您可以按与作业关联的 LABEL 进行过滤
SELECT * FROM information_schema.loads WHERE LABEL = 'user_behavior' \G
*************************** 1. row ***************************
JOB_ID: 10250
LABEL: user_behavior
DATABASE_NAME: mydatabase
STATE: FINISHED
PROGRESS: ETL:100%; LOAD:100%
TYPE: BROKER
PRIORITY: NORMAL
SCAN_ROWS: 10000000
FILTERED_ROWS: 0
UNSELECTED_ROWS: 0
SINK_ROWS: 10000000
ETL_INFO:
TASK_INFO: resource:N/A; timeout(s):3600; max_filter_ratio:0.0
CREATE_TIME: 2023-12-28 16:15:19
ETL_START_TIME: 2023-12-28 16:15:25
ETL_FINISH_TIME: 2023-12-28 16:15:25
LOAD_START_TIME: 2023-12-28 16:15:25
LOAD_FINISH_TIME: 2023-12-28 16:16:31
JOB_DETAILS: {"All backends":{"6a8ef4c0-1009-48c9-8d18-c4061d2255bf":[10121]},"FileNumber":1,"FileSize":132251298,"InternalTableLoadBytes":311710786,"InternalTableLoadRows":10000000,"ScanBytes":132251298,"ScanRows":10000000,"TaskNumber":1,"Unfinished backends":{"6a8ef4c0-1009-48c9-8d18-c4061d2255bf":[]}}
ERROR_MSG: NULL
TRACKING_URL: NULL
TRACKING_SQL: NULL
REJECTED_RECORD_PATH: NULL
在确认加载作业已完成后,您可以检查目标表的子集,以查看数据是否已成功加载。 例子
SELECT * from user_behavior LIMIT 3;
系统返回类似于以下的查询结果,表明数据已成功加载
+--------+---------+------------+--------------+---------------------+
| UserID | ItemID | CategoryID | BehaviorType | Timestamp |
+--------+---------+------------+--------------+---------------------+
| 142 | 2869980 | 2939262 | pv | 2017-11-25 03:43:22 |
| 142 | 2522236 | 1669167 | pv | 2017-11-25 15:14:12 |
| 142 | 3031639 | 3607361 | pv | 2017-11-25 15:19:25 |
+--------+---------+------------+--------------+---------------------+