从 MySQL 实时同步
StarRocks 支持多种方法将数据从 MySQL 实时同步到 StarRocks,从而实现大规模数据的低延迟实时分析。
本主题介绍如何通过 Apache Flink® 以实时(秒级)同步数据从 MySQL 到 StarRocks。
只有对 StarRocks 表具有 INSERT 权限的用户才能将数据加载到 StarRocks 表中。如果您没有 INSERT 权限,请按照 GRANT 中提供的说明授予用于连接 StarRocks 集群的用户的 INSERT 权限。语法为 GRANT INSERT ON TABLE <table_name> IN DATABASE <database_name> TO { ROLE <role_name> | USER <user_identity>}。
工作原理
Flink CDC 用于从 MySQL 同步到 Flink。本主题使用 Flink CDC,其版本低于 3.0,因此 SMT 用于同步表模式。但是,如果使用 Flink CDC 3.0,则不必使用 SMT 将表模式同步到 StarRocks。Flink CDC 3.0 甚至可以同步整个 MySQL 数据库、分片数据库和表的模式,还支持模式更改同步。有关详细用法,请参阅 Streaming ELT from MySQL to StarRocks。
下图说明了整个同步过程。
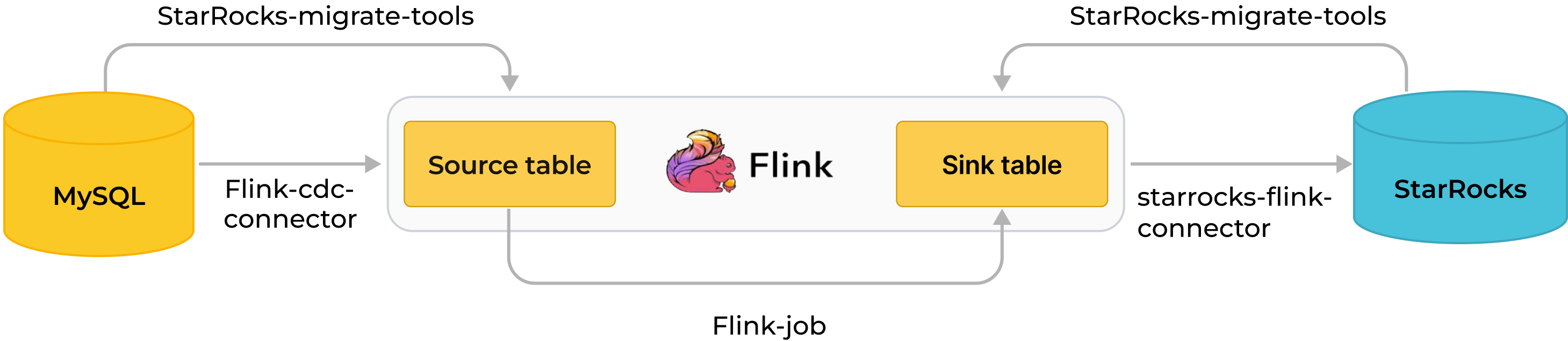
通过 Flink 将 MySQL 实时同步到 StarRocks 分为两个阶段实现:同步数据库和表模式以及同步数据。首先,SMT 将 MySQL 数据库和表模式转换为 StarRocks 的表创建语句。然后,Flink 集群运行 Flink 作业以将 MySQL 的完整和增量数据同步到 StarRocks。
同步过程保证了精确一次语义。
同步过程:
-
同步数据库和表模式。
SMT 读取要同步的 MySQL 数据库和表的模式,并生成 SQL 文件以在 StarRocks 中创建目标数据库和表。此操作基于 SMT 配置文件中的 MySQL 和 StarRocks 信息。
-
同步数据。
a. Flink SQL 客户端执行数据加载语句
INSERT INTO SELECT以将一个或多个 Flink 作业提交到 Flink 集群。b. Flink 集群运行 Flink 作业以获取数据。Flink CDC 连接器首先从源数据库读取完整的历史数据,然后无缝切换到增量读取,并将数据发送到 flink-connector-starrocks。
c. flink-connector-starrocks 在小批量中累积数据,并将每批数据同步到 StarRocks。
信息只有 MySQL 中的数据操作语言 (DML) 操作可以同步到 StarRocks。数据定义语言 (DDL) 操作无法同步。
使用场景
从 MySQL 实时同步具有广泛的用例,其中数据不断变化。以一个实际用例“商品销售实时排名”为例。
Flink 基于 MySQL 中原始订单表计算商品销售的实时排名,并将排名实时同步到 StarRocks 的主键表。用户可以将可视化工具连接到 StarRocks 以实时查看排名,从而获得按需运营见解。
准备工作
下载并安装同步工具
要从 MySQL 同步数据,您需要安装以下工具:SMT、Flink、Flink CDC 连接器和 flink-connector-starrocks。
-
下载并安装 Flink,并启动 Flink 集群。您也可以按照 Flink 官方文档中的说明执行此步骤。
a. 在运行 Flink 之前,请在您的操作系统中安装 Java 8 或 Java 11。您可以运行以下命令来检查已安装的 Java 版本。
# View the Java version.
java -version
# Java 8 is installed if the following output is returned.
java version "1.8.0_301"
Java(TM) SE Runtime Environment (build 1.8.0_301-b09)
Java HotSpot(TM) 64-Bit Server VM (build 25.301-b09, mixed mode)b. 下载 Flink 安装包并解压缩。我们建议您使用 Flink 1.14 或更高版本。允许的最低版本为 Flink 1.11。本主题使用 Flink 1.14.5。
# Download Flink.
wget https://archive.apache.org/dist/flink/flink-1.14.5/flink-1.14.5-bin-scala_2.11.tgz
# Decompress Flink.
tar -xzf flink-1.14.5-bin-scala_2.11.tgz
# Go to the Flink directory.
cd flink-1.14.5c. 启动 Flink 集群。
# Start the Flink cluster.
./bin/start-cluster.sh
# The Flink cluster is started if the following output is returned.
Starting cluster.
Starting standalonesession daemon on host.
Starting taskexecutor daemon on host. -
下载 Flink CDC 连接器。本主题使用 MySQL 作为数据源,因此下载了
flink-sql-connector-mysql-cdc-x.x.x.jar。连接器版本必须与 Flink 版本匹配。本主题使用 Flink 1.14.5,您可以下载flink-sql-connector-mysql-cdc-2.2.0.jar。wget https://repo1.maven.org/maven2/com/ververica/flink-sql-connector-mysql-cdc/2.1.1/flink-sql-connector-mysql-cdc-2.2.0.jar -
下载 flink-connector-starrocks。版本必须与 Flink 版本匹配。
flink-connector-starrocks 包
x.x.x_flink-y.yy _ z.zz.jar包含三个版本号x.x.x是 flink-connector-starrocks 的版本号。y.yy是支持的 Flink 版本。z.zz是 Flink 支持的 Scala 版本。如果 Flink 版本为 1.14.x 或更早版本,则必须下载具有 Scala 版本的包。
本主题使用 Flink 1.14.5 和 Scala 2.11。因此,您可以下载以下包:
1.2.3_flink-14_2.11.jar。 -
将 Flink CDC 连接器 (
flink-sql-connector-mysql-cdc-2.2.0.jar) 和 flink-connector-starrocks (1.2.3_flink-1.14_2.11.jar) 的 JAR 包移动到 Flink 的lib目录。注意
如果您的系统中已经运行了 Flink 集群,则必须停止 Flink 集群并重新启动它以加载和验证 JAR 包。
$ ./bin/stop-cluster.sh
$ ./bin/start-cluster.sh -
下载并解压缩 SMT 包并将其放置在
flink-1.14.5目录中。StarRocks 提供适用于 Linux x86 和 macos ARM64 的 SMT 包。您可以根据您的操作系统和 CPU 选择一个。# for Linux x86
wget https://releases.starrocks.io/resources/smt.tar.gz
# for macOS ARM64
wget https://releases.starrocks.io/resources/smt_darwin_arm64.tar.gz
启用 MySQL 二进制日志
要实时同步来自 MySQL 的数据,系统需要从 MySQL 二进制日志 (binlog) 读取数据,解析数据,然后将数据同步到 StarRocks。确保已启用 MySQL 二进制日志。
-
编辑 MySQL 配置文件
my.cnf(默认路径:/etc/my.cnf)以启用 MySQL 二进制日志。# Enable MySQL Binlog.
log_bin = ON
# Configure the save path for the Binlog.
log_bin =/var/lib/mysql/mysql-bin
# Configure server_id.
# If server_id is not configured for MySQL 5.7.3 or later, the MySQL service cannot be used.
server_id = 1
# Set the Binlog format to ROW.
binlog_format = ROW
# The base name of the Binlog file. An identifier is appended to identify each Binlog file.
log_bin_basename =/var/lib/mysql/mysql-bin
# The index file of Binlog files, which manages the directory of all Binlog files.
log_bin_index =/var/lib/mysql/mysql-bin.index -
运行以下命令之一以重新启动 MySQL,以使修改后的配置文件生效。
# Use service to restart MySQL.
service mysqld restart
# Use mysqld script to restart MySQL.
/etc/init.d/mysqld restart -
连接到 MySQL 并检查是否已启用 MySQL 二进制日志。
-- Connect to MySQL.
mysql -h xxx.xx.xxx.xx -P 3306 -u root -pxxxxxx
-- Check whether MySQL binary log is enabled.
mysql> SHOW VARIABLES LIKE 'log_bin';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| log_bin | ON |
+---------------+-------+
1 row in set (0.00 sec)
同步数据库和表模式
-
编辑 SMT 配置文件。转到 SMT
conf目录并编辑配置文件config_prod.conf,例如 MySQL 连接信息、要同步的数据库和表的匹配规则以及 flink-connector-starrocks 的配置信息。[db]
type = mysql
host = xxx.xx.xxx.xx
port = 3306
user = user1
password = xxxxxx
[other]
# Number of BEs in StarRocks
be_num = 3
# `decimal_v3` is supported since StarRocks-1.18.1.
use_decimal_v3 = true
# File to save the converted DDL SQL
output_dir = ./result
[table-rule.1]
# Pattern to match databases for setting properties
database = ^demo.*$
# Pattern to match tables for setting properties
table = ^.*$
############################################
### Flink sink configurations
### DO NOT set `connector`, `table-name`, `database-name`. They are auto-generated.
############################################
flink.starrocks.jdbc-url=jdbc:mysql://<fe_host>:<fe_query_port>
flink.starrocks.load-url= <fe_host>:<fe_http_port>
flink.starrocks.username=user2
flink.starrocks.password=xxxxxx
flink.starrocks.sink.properties.format=csv
flink.starrocks.sink.properties.column_separator=\x01
flink.starrocks.sink.properties.row_delimiter=\x02
flink.starrocks.sink.buffer-flush.interval-ms=15000-
[db]:用于访问源数据库的信息。type:源数据库的类型。在本主题中,源数据库为mysql。host:MySQL 服务器的 IP 地址。port:MySQL 数据库的端口号,默认为3306user:用于访问 MySQL 数据库的用户名password:用户名的密码
-
[table-rule]:数据库和表匹配规则以及相应的 flink-connector-starrocks 配置。Database,table:MySQL 中数据库和表的名称。支持正则表达式。flink.starrocks.*:flink-connector-starrocks 的配置信息。有关更多配置和信息,请参阅 flink-connector-starrocks。
如果您需要为不同的表使用不同的 flink-connector-starrocks 配置。例如,如果某些表经常更新,并且您需要加速数据加载,请参阅 为不同的表使用不同的 flink-connector-starrocks 配置。如果您需要将从 MySQL 分片获得的多个表加载到同一个 StarRocks 表中,请参阅 将 MySQL 分片后的多个表同步到一个 StarRocks 表中。
-
[other]:其他信息be_num:StarRocks 集群中的 BE 数量(此参数将用于在后续 StarRocks 表创建中设置合理的 Tablet 数量)。use_decimal_v3:是否启用 Decimal V3。启用 Decimal V3 后,当数据同步到 StarRocks 时,MySQL decimal 数据将转换为 Decimal V3 数据。output_dir:用于保存要生成的 SQL 文件的路径。SQL 文件将用于在 StarRocks 中创建数据库和表,并将 Flink 作业提交到 Flink 集群。默认路径为./result,我们建议您保留默认设置。
-
-
运行 SMT 以读取 MySQL 中的数据库和表模式,并根据配置文件在
./result目录中生成 SQL 文件。starrocks-create.all.sql文件用于在 StarRocks 中创建数据库和表,flink-create.all.sql文件用于将 Flink 作业提交到 Flink 集群。# Run the SMT.
./starrocks-migrate-tool
# Go to the result directory and check the files in this directory.
cd result
ls result
flink-create.1.sql smt.tar.gz starrocks-create.all.sql
flink-create.all.sql starrocks-create.1.sql -
运行以下命令以连接到 StarRocks 并执行
starrocks-create.all.sql文件以在 StarRocks 中创建数据库和表。我们建议您使用 SQL 文件中的默认表创建语句来创建 主键表。注意
您还可以根据您的业务需求修改表创建语句,并创建一个不使用主键表的表。但是,源 MySQL 数据库中的 DELETE 操作无法同步到非主键表。创建此类表时请谨慎。
mysql -h <fe_host> -P <fe_query_port> -u user2 -pxxxxxx < starrocks-create.all.sql如果数据需要在写入目标 StarRocks 表之前由 Flink 处理,则源表和目标表的表模式将不同。在这种情况下,您必须修改表创建语句。在本例中,目标表只需要
product_id和product_name列以及商品销售的实时排名。您可以使用以下表创建语句。CREATE DATABASE IF NOT EXISTS `demo`;
CREATE TABLE IF NOT EXISTS `demo`.`orders` (
`product_id` INT(11) NOT NULL COMMENT "",
`product_name` STRING NOT NULL COMMENT "",
`sales_cnt` BIGINT NOT NULL COMMENT ""
) ENGINE=olap
PRIMARY KEY(`product_id`)
DISTRIBUTED BY HASH(`product_id`)
PROPERTIES (
"replication_num" = "3"
);注意
自 v2.5.7 起,StarRocks 可以在您创建表或添加分区时自动设置 Bucket 数量 (BUCKETS)。您不再需要手动设置 Bucket 数量。有关详细信息,请参阅 设置 Bucket 数量。
同步数据
运行 Flink 集群并将 Flink 作业提交到 Flink 集群,以持续同步 MySQL 中的完整和增量数据到 StarRocks。
-
转到 Flink 目录并运行以下命令以在您的 Flink SQL 客户端上运行
flink-create.all.sql文件。./bin/sql-client.sh -f flink-create.all.sql此 SQL 文件定义了动态表
source table和sink table、查询语句INSERT INTO SELECT,并指定了连接器、源数据库和目标数据库。执行此文件后,会将 Flink 作业提交到 Flink 集群以启动数据同步。注意
- 确保已启动 Flink 集群。您可以通过运行
flink/bin/start-cluster.sh启动 Flink 集群。 - 如果您的 Flink 版本早于 1.13,您可能无法直接运行 SQL 文件
flink-create.all.sql。您需要在 SQL 客户端的命令行界面 (CLI) 中逐个执行此文件中的 SQL 语句。您还需要转义\字符。
'sink.properties.column_separator' = '\\x01'
'sink.properties.row_delimiter' = '\\x02'在同步期间处理数据:
如果您需要在同步期间处理数据,例如对数据执行 GROUP BY 或 JOIN,您可以修改
flink-create.all.sql文件。以下示例通过执行 COUNT (*) 和 GROUP BY 来计算商品销售的实时排名。$ ./bin/sql-client.sh -f flink-create.all.sql
No default environment is specified.
Searching for '/home/disk1/flink-1.13.6/conf/sql-client-defaults.yaml'...not found.
[INFO] Executing SQL from file.
Flink SQL> CREATE DATABASE IF NOT EXISTS `default_catalog`.`demo`;
[INFO] Execute statement succeed.
-- Create a dynamic table `source table` based on the order table in MySQL.
Flink SQL>
CREATE TABLE IF NOT EXISTS `default_catalog`.`demo`.`orders_src` (`order_id` BIGINT NOT NULL,
`product_id` INT NULL,
`order_date` TIMESTAMP NOT NULL,
`customer_name` STRING NOT NULL,
`product_name` STRING NOT NULL,
`price` DECIMAL(10, 5) NULL,
PRIMARY KEY(`order_id`)
NOT ENFORCED
) with ('connector' = 'mysql-cdc',
'hostname' = 'xxx.xx.xxx.xxx',
'port' = '3306',
'username' = 'root',
'password' = '',
'database-name' = 'demo',
'table-name' = 'orders'
);
[INFO] Execute statement succeed.
-- Create a dynamic table `sink table`.
Flink SQL>
CREATE TABLE IF NOT EXISTS `default_catalog`.`demo`.`orders_sink` (`product_id` INT NOT NULL,
`product_name` STRING NOT NULL,
`sales_cnt` BIGINT NOT NULL,
PRIMARY KEY(`product_id`)
NOT ENFORCED
) with ('sink.max-retries' = '10',
'jdbc-url' = 'jdbc:mysql://<fe_host>:<fe_query_port>',
'password' = '',
'sink.properties.strip_outer_array' = 'true',
'sink.properties.format' = 'json',
'load-url' = '<fe_host>:<fe_http_port>',
'username' = 'root',
'sink.buffer-flush.interval-ms' = '15000',
'connector' = 'starrocks',
'database-name' = 'demo',
'table-name' = 'orders'
);
[INFO] Execute statement succeed.
-- Implement real-time ranking of commodity sales, where `sink table` is dynamically updated to reflect data changes in `source table`.
Flink SQL>
INSERT INTO `default_catalog`.`demo`.`orders_sink` select product_id,product_name, count(*) as cnt from `default_catalog`.`demo`.`orders_src` group by product_id,product_name;
[INFO] Submitting SQL update statement to the cluster...
[INFO] SQL update statement has been successfully submitted to the cluster:
Job ID: 5ae005c4b3425d8bb13fe660260a35da如果您只需要同步部分数据,例如付款时间晚于 2021 年 12 月 21 日的数据,您可以使用
INSERT INTO SELECT中的WHERE子句来设置筛选条件,例如WHERE pay_dt > '2021-12-21'。不满足此条件的数据将不会同步到 StarRocks。如果返回以下结果,则 Flink 作业已提交以进行完整和增量同步。
[INFO] Submitting SQL update statement to the cluster...
[INFO] SQL update statement has been successfully submitted to the cluster:
Job ID: 5ae005c4b3425d8bb13fe660260a35da - 确保已启动 Flink 集群。您可以通过运行
-
您可以使用 Flink WebUI 或在您的 Flink SQL 客户端上运行
bin/flink list -running命令,以查看 Flink 集群中正在运行的 Flink 作业和作业 ID。-
Flink WebUI
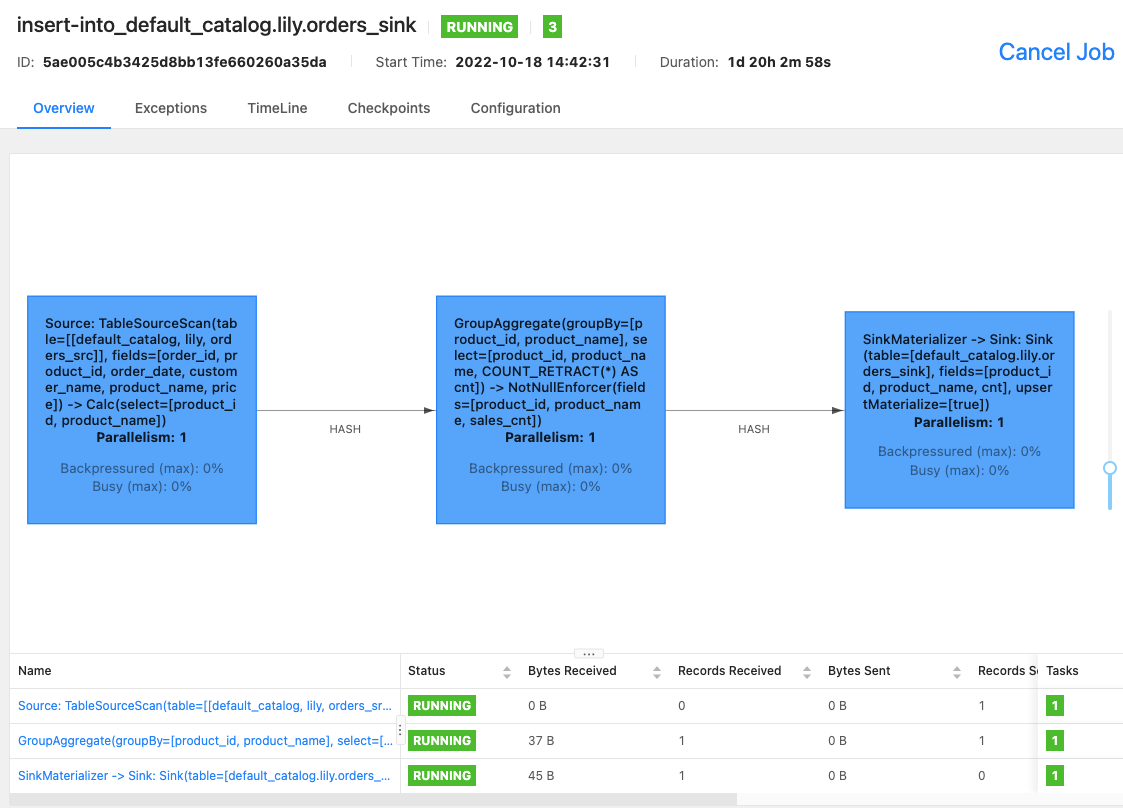
-
bin/flink list -running
$ bin/flink list -running
Waiting for response...
------------------ Running/Restarting Jobs -------------------
13.10.2022 15:03:54 : 040a846f8b58e82eb99c8663424294d5 : insert-into_default_catalog.lily.example_tbl1_sink (RUNNING)
--------------------------------------------------------------注意
如果作业异常,您可以使用 Flink WebUI 或通过查看 Flink 1.14.5 的
/log目录中的日志文件来执行故障排除。 -
常见问题
为不同的表使用不同的 flink-connector-starrocks 配置
如果数据源中的某些表经常更新,并且您想要加速 flink-connector-starrocks 的加载速度,您必须在 SMT 配置文件 config_prod.conf 中为每个表设置单独的 flink-connector-starrocks 配置。
[table-rule.1]
# Pattern to match databases for setting properties
database = ^order.*$
# Pattern to match tables for setting properties
table = ^.*$
############################################
### Flink sink configurations
### DO NOT set `connector`, `table-name`, `database-name`. They are auto-generated
############################################
flink.starrocks.jdbc-url=jdbc:mysql://<fe_host>:<fe_query_port>
flink.starrocks.load-url= <fe_host>:<fe_http_port>
flink.starrocks.username=user2
flink.starrocks.password=xxxxxx
flink.starrocks.sink.properties.format=csv
flink.starrocks.sink.properties.column_separator=\x01
flink.starrocks.sink.properties.row_delimiter=\x02
flink.starrocks.sink.buffer-flush.interval-ms=15000
[table-rule.2]
# Pattern to match databases for setting properties
database = ^order2.*$
# Pattern to match tables for setting properties
table = ^.*$
############################################
### Flink sink configurations
### DO NOT set `connector`, `table-name`, `database-name`. They are auto-generated
############################################
flink.starrocks.jdbc-url=jdbc:mysql://<fe_host>:<fe_query_port>
flink.starrocks.load-url= <fe_host>:<fe_http_port>
flink.starrocks.username=user2
flink.starrocks.password=xxxxxx
flink.starrocks.sink.properties.format=csv
flink.starrocks.sink.properties.column_separator=\x01
flink.starrocks.sink.properties.row_delimiter=\x02
flink.starrocks.sink.buffer-flush.interval-ms=10000
将 MySQL 分片后的多个表同步到一个 StarRocks 表中
执行分片后,一个 MySQL 表中的数据可能会拆分为多个表,甚至分布到多个数据库。所有表都具有相同的模式。在这种情况下,您可以设置 [table-rule] 将这些表同步到一个 StarRocks 表中。例如,MySQL 有两个数据库 edu_db_1 和 edu_db_2,每个数据库都有两个表 course_1 和 course_2,并且所有表的模式都相同。您可以使用以下 [table-rule] 配置将所有表同步到一个 StarRocks 表中。
注意
StarRocks 表的名称默认为
course__auto_shard。如果您需要使用不同的名称,您可以在 SQL 文件starrocks-create.all.sql和flink-create.all.sql中修改它
[table-rule.1]
# Pattern to match databases for setting properties
database = ^edu_db_[0-9]*$
# Pattern to match tables for setting properties
table = ^course_[0-9]*$
############################################
### Flink sink configurations
### DO NOT set `connector`, `table-name`, `database-name`. They are auto-generated
############################################
flink.starrocks.jdbc-url = jdbc: mysql://xxx.xxx.x.x:xxxx
flink.starrocks.load-url = xxx.xxx.x.x:xxxx
flink.starrocks.username = user2
flink.starrocks.password = xxxxxx
flink.starrocks.sink.properties.format=csv
flink.starrocks.sink.properties.column_separator =\x01
flink.starrocks.sink.properties.row_delimiter =\x02
flink.starrocks.sink.buffer-flush.interval-ms = 5000
以 JSON 格式导入数据
在前面的示例中,数据以 CSV 格式导入。如果您无法选择合适的分隔符,则需要替换 [table-rule] 中 flink.starrocks.* 的以下参数。
flink.starrocks.sink.properties.format=csv
flink.starrocks.sink.properties.column_separator =\x01
flink.starrocks.sink.properties.row_delimiter =\x02
传递以下参数后,数据以 JSON 格式导入。
flink.starrocks.sink.properties.format=json
flink.starrocks.sink.properties.strip_outer_array=true
注意
此方法会稍微降低加载速度。
将多个 INSERT INTO 语句作为一个 Flink 作业执行
您可以使用 flink-create.all.sql 文件中的 STATEMENT SET 语法将多个 INSERT INTO 语句作为一个 Flink 作业执行,这可以防止多个语句占用过多的 Flink 作业资源,并提高执行多个查询的效率。
注意
Flink 从 1.13 开始支持 STATEMENT SET 语法。
-
打开
result/flink-create.all.sql文件。 -
修改文件中的 SQL 语句。将所有 INSERT INTO 语句移动到文件末尾。将
EXECUTE STATEMENT SET BEGIN放在第一个 INSERT INTO 语句之前,将END;放在最后一个 INSERT INTO 语句之后。
注意
CREATE DATABASE 和 CREATE TABLE 的位置保持不变。
CREATE DATABASE IF NOT EXISTS db;
CREATE TABLE IF NOT EXISTS db.a1;
CREATE TABLE IF NOT EXISTS db.b1;
CREATE TABLE IF NOT EXISTS db.a2;
CREATE TABLE IF NOT EXISTS db.b2;
EXECUTE STATEMENT SET
BEGIN-- one or more INSERT INTO statements
INSERT INTO db.a1 SELECT * FROM db.b1;
INSERT INTO db.a2 SELECT * FROM db.b2;
END;