数据库特性
StarRocks 提供了一系列丰富的功能,可在大规模数据上提供闪电般的实时分析体验。
MPP 框架
StarRocks 采用大规模并行处理 (MPP) 框架。一个查询请求被拆分为多个物理计算单元,可以在多台机器上并行执行。每台机器都有专用的 CPU 和内存资源。MPP 框架充分利用所有 CPU 核心和机器的资源。随着集群的横向扩展,单个查询的性能可以不断提高。
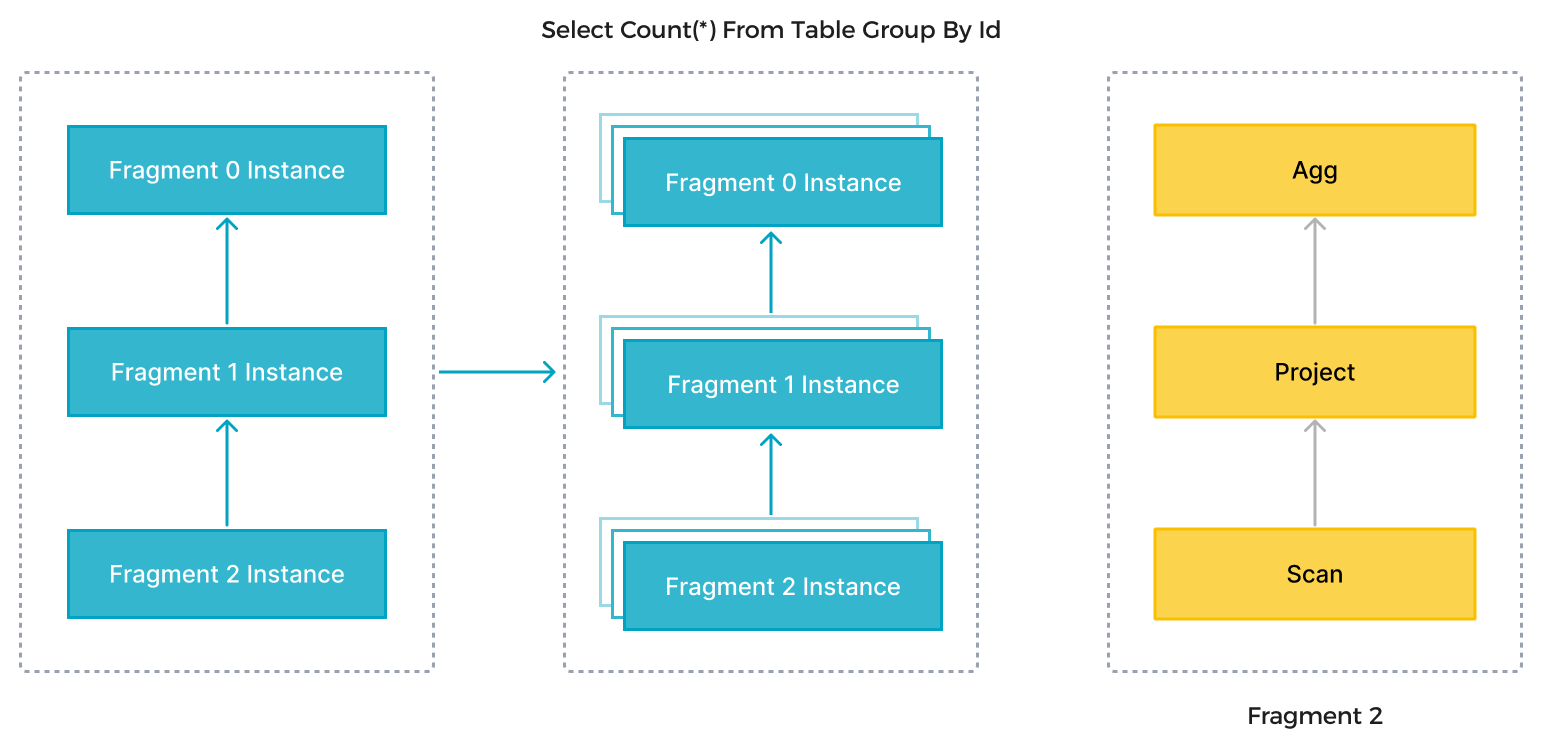
在上图中,StarRocks 根据语句的语义将 SQL 语句解析为多个逻辑执行单元(查询片段)。然后,根据计算的复杂性,每个片段由一个或多个物理执行单元(片段实例)来实现。物理执行单元是 StarRocks 中最小的调度单元。它们将被调度到后端 (BE) 执行。一个逻辑执行单元可以包含一个或多个运算符,例如 Scan、Project 和 Agg 运算符,如图右侧所示。每个物理执行单元仅处理部分数据,结果将被合并以生成最终数据。逻辑执行单元的并行执行充分利用了所有 CPU 核心和物理机器的资源,并提高了查询速度。
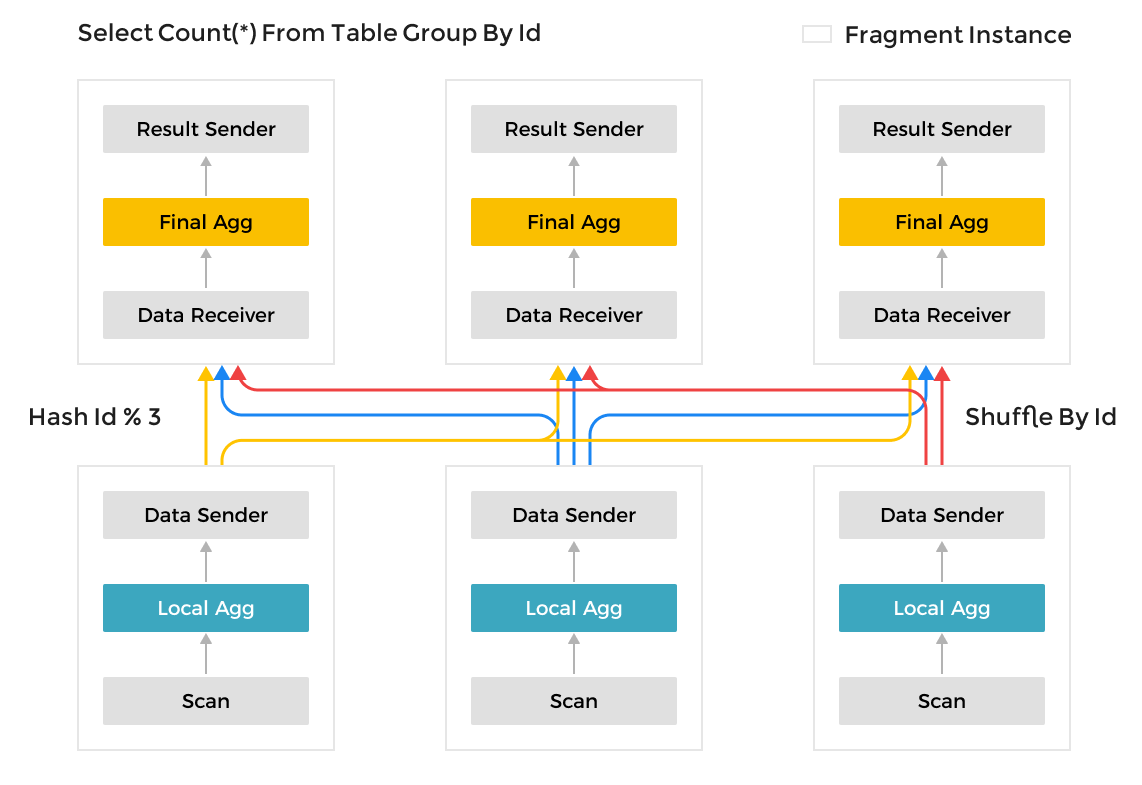
与许多其他数据分析系统使用的 Scatter-Gather 框架不同,MPP 框架可以利用更多资源来处理查询请求。在 Scatter-Gather 框架中,只有 Gather 节点可以执行最终的合并操作。在 MPP 框架中,数据会被混洗到多个节点以进行合并操作。对于复杂的查询,例如对高基数字段的 Group By 和大型表连接,StarRocks 的 MPP 框架比 Scatter-Gather 框架具有明显的性能优势。
全量向量化执行引擎
全量向量化执行引擎可以更有效地利用 CPU 处理能力,因为该引擎以列式方式组织和处理数据。具体来说,StarRocks 以列式方式存储数据、在内存中组织数据并计算 SQL 运算符。列式组织可以充分利用 CPU 缓存。列式计算减少了虚函数调用和分支判断的数量,从而产生更充足的 CPU 指令流。
向量化执行引擎还充分利用了 SIMD 指令。该引擎可以用更少的指令完成更多的数据操作。针对标准数据集的测试表明,该引擎可将运算符的整体性能提高 3 到 10 倍。
除了运算符向量化之外,StarRocks 还为查询引擎实现了其他优化。例如,StarRocks 使用 Operation on Encoded Data 技术来直接对编码字符串执行运算符,而无需解码。这显着降低了 SQL 的复杂性,并将查询速度提高了 2 倍以上。
存储计算分离
存储计算分离架构是从 3.0 版本引入的。在此架构中,计算和存储解耦,以实现资源隔离、计算节点的弹性伸缩和高性能查询。存储计算分离使 StarRocks 具有更好的灵活性、更高的性能和数据可用性以及更低的成本。
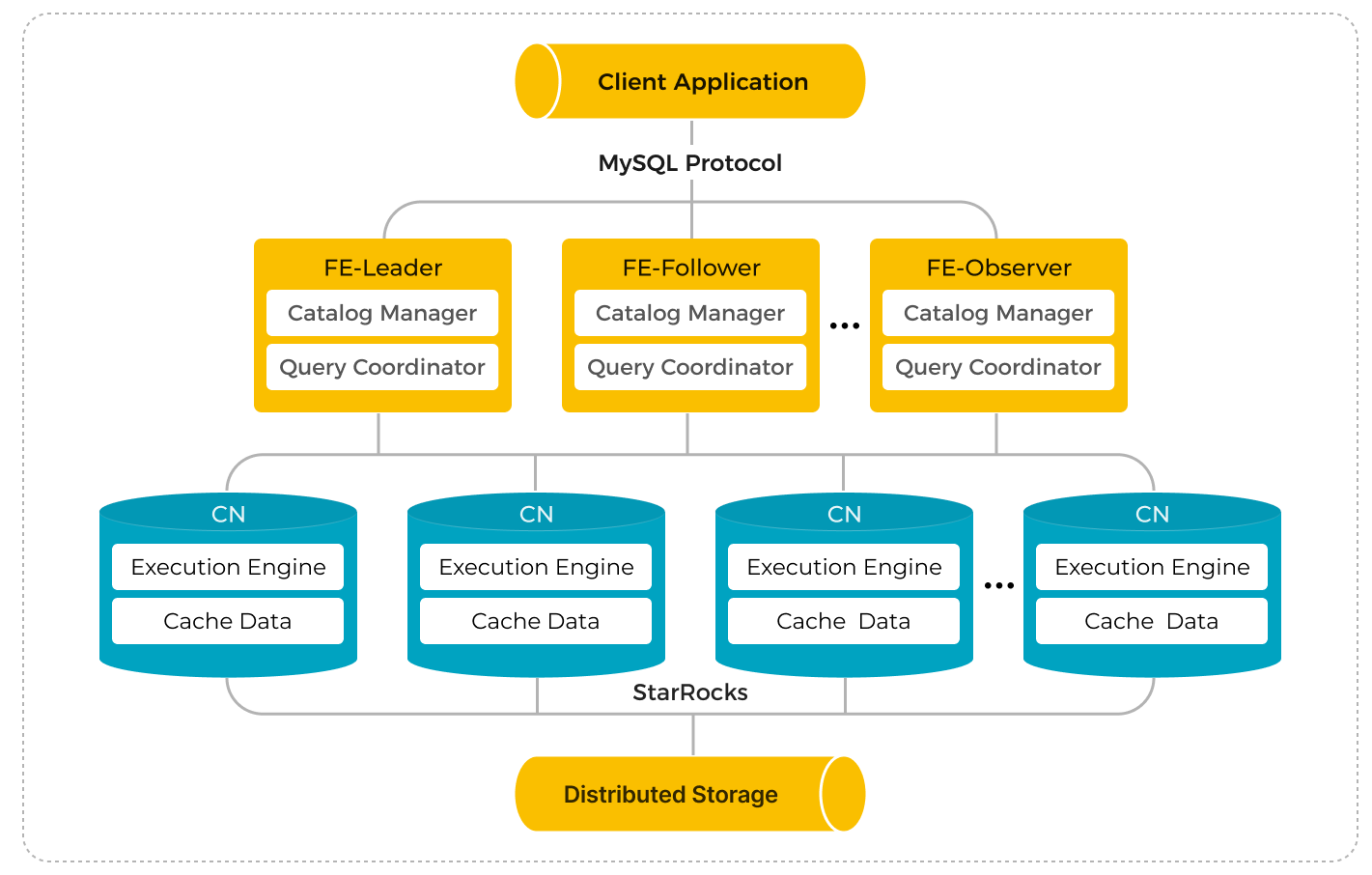
在存储计算分离模式下,计算和存储是解耦的,可以独立扩展,这消除了存储计算耦合模式中长期存在的成本,在这种模式下,用户每次想要添加计算节点都必须扩展存储。此外,计算可以在几秒钟内动态扩展,从而提高资源利用率,尤其是在存在明显的流量高峰和低谷时。
存储层利用对象存储的近乎无限的容量和高可靠性来实现海量数据存储和数据持久性。StarRocks 可以与各种对象存储系统一起使用,例如 AWS S3、Google Cloud Storage、Azure Blob Storage、HDFS 和其他与 S3 兼容的存储(如 MinIO)。
用户可以选择在公有云、私有云或本地数据中心中部署 StarRocks。StarRocks 支持基于 Kubernetes 的部署,并提供一个 Operator 用于自动部署存储计算解耦集群。
存储计算分离模式下的 StarRocks 提供与存储计算耦合模式相同的功能。数据写入和热数据查询性能也相同。用户可以像在存储计算耦合模式下一样执行数据更新、数据湖分析和物化视图加速。
基于成本的优化器
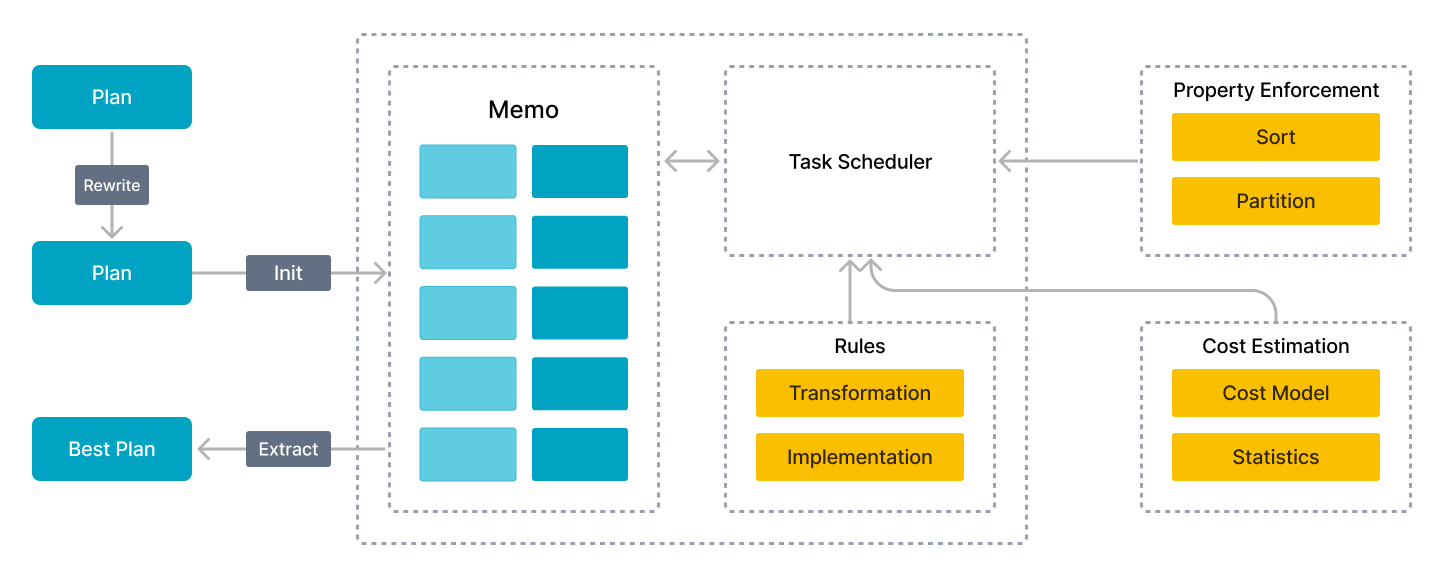
多表连接查询的性能很难优化。仅靠执行引擎无法提供卓越的性能,因为在多表连接查询场景中,执行计划的复杂性可能会相差几个数量级。关联的表越多,执行计划就越多,这使得选择最佳计划成为 NP 难题。只有足够优秀的查询优化器才能选择相对最佳的查询计划,以实现高效的多表分析。
StarRocks 从头开始设计了一个全新的 CBO。此 CBO 采用类似 cascades 的框架,并针对向量化执行引擎进行了深度定制,并进行了许多优化和创新。这些优化包括公共表表达式 (CTE) 的重用、子查询的重写、Lateral Join、Join Reorder、分布式 Join 执行的策略选择以及低基数优化。CBO 支持总共 99 个 TPC-DS SQL 语句。
CBO 使 StarRocks 能够提供比竞争对手更好的多表连接查询性能,尤其是在复杂的多表连接查询中。
实时可更新列式存储引擎
StarRocks 是一种列式存储引擎,允许连续存储相同类型的数据。在列式存储中,数据可以以更有效的方式进行编码,从而提高压缩率并降低存储成本。列式存储还减少了总数据读取 I/O,从而提高了查询性能。此外,在大多数 OLAP 场景中,仅查询特定列。列式存储使用户能够仅查询部分列,从而显着减少磁盘 I/O。
StarRocks 可以在几秒钟内加载数据以进行近实时分析。StarRocks 的存储引擎保证每个数据摄取操作的原子性、一致性、隔离性和持久性 (ACID)。对于数据加载事务,整个事务要么成功,要么失败。并发事务互不影响,提供事务级隔离。
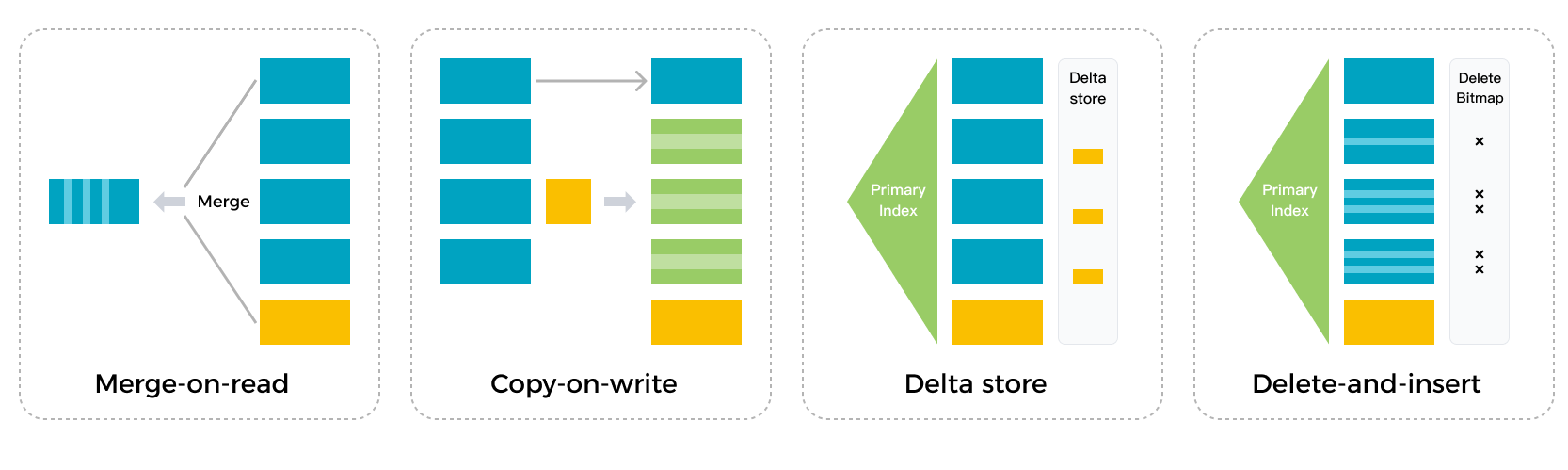
StarRocks 的存储引擎使用 Delete-and-insert 模式,可以实现高效的 Partial Update 和 Upsert 操作。存储引擎可以使用主键索引快速过滤数据,无需在数据读取时进行 Sort 和 Merge 操作。该引擎还可以充分利用辅助索引。即使在大量数据更新的情况下,它也能提供快速且可预测的查询性能。
智能物化视图
StarRocks 使用智能物化视图来加速查询和数据仓库分层。与其他类似产品的物化视图需要手动与基表同步数据不同,StarRocks 的物化视图会根据基表中的数据更改自动更新数据,而无需额外的维护操作。此外,物化视图的选择也是自动的。如果 StarRocks 识别出合适的物化视图 (MV) 来提高查询性能,它将自动重写查询以利用 MV。这种智能过程显着提高了查询效率,而无需手动干预。
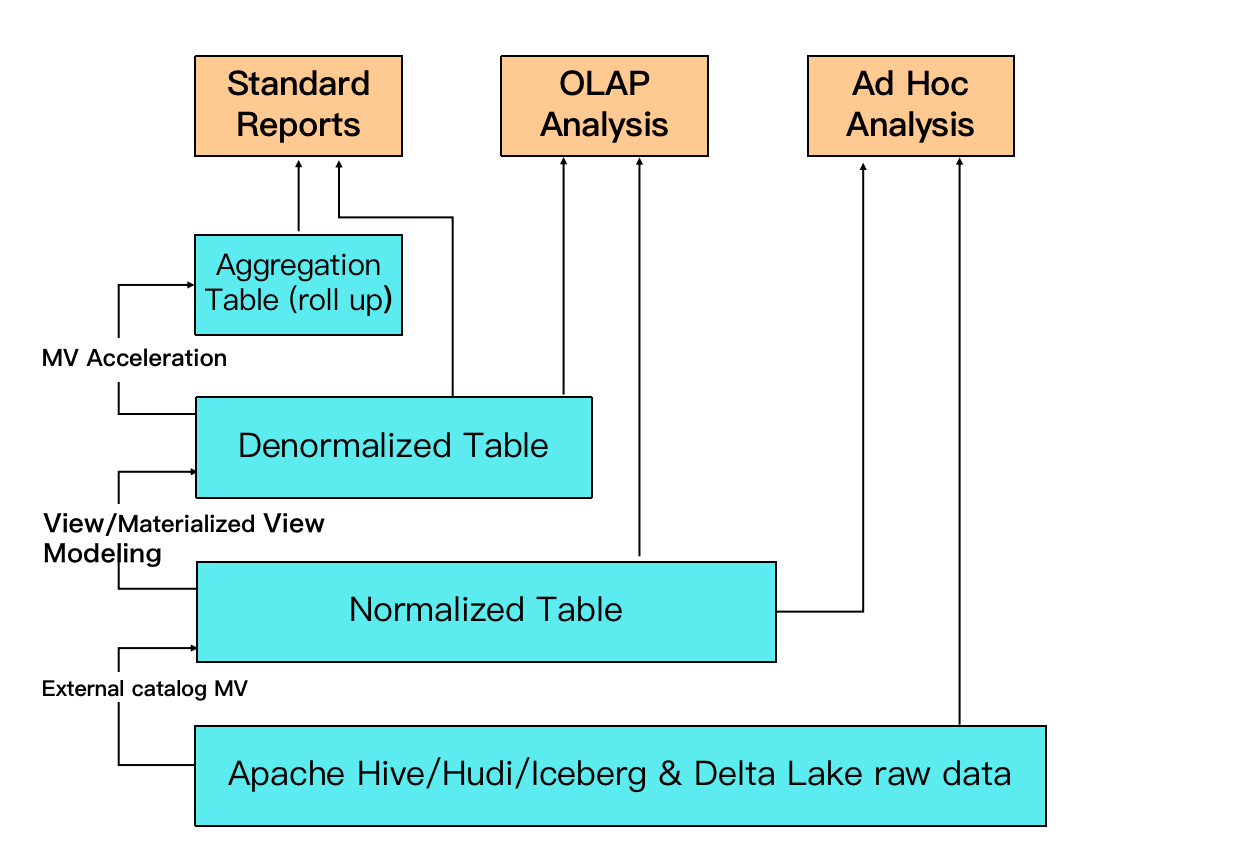
StarRocks 的 MV 可以替代传统的 ETL 数据建模过程:现在可以选择在 StarRocks 中使用 MV 转换数据,而不是在上游应用程序中转换数据,从而简化了数据处理管道。
例如,在该图中,可以使用数据湖中的原始数据基于外部 MV 创建规范化表。可以通过异步物化视图从规范化表创建非规范化表。可以从规范化表创建另一个 MV,以支持高并发查询和更好的查询性能。
数据湖分析
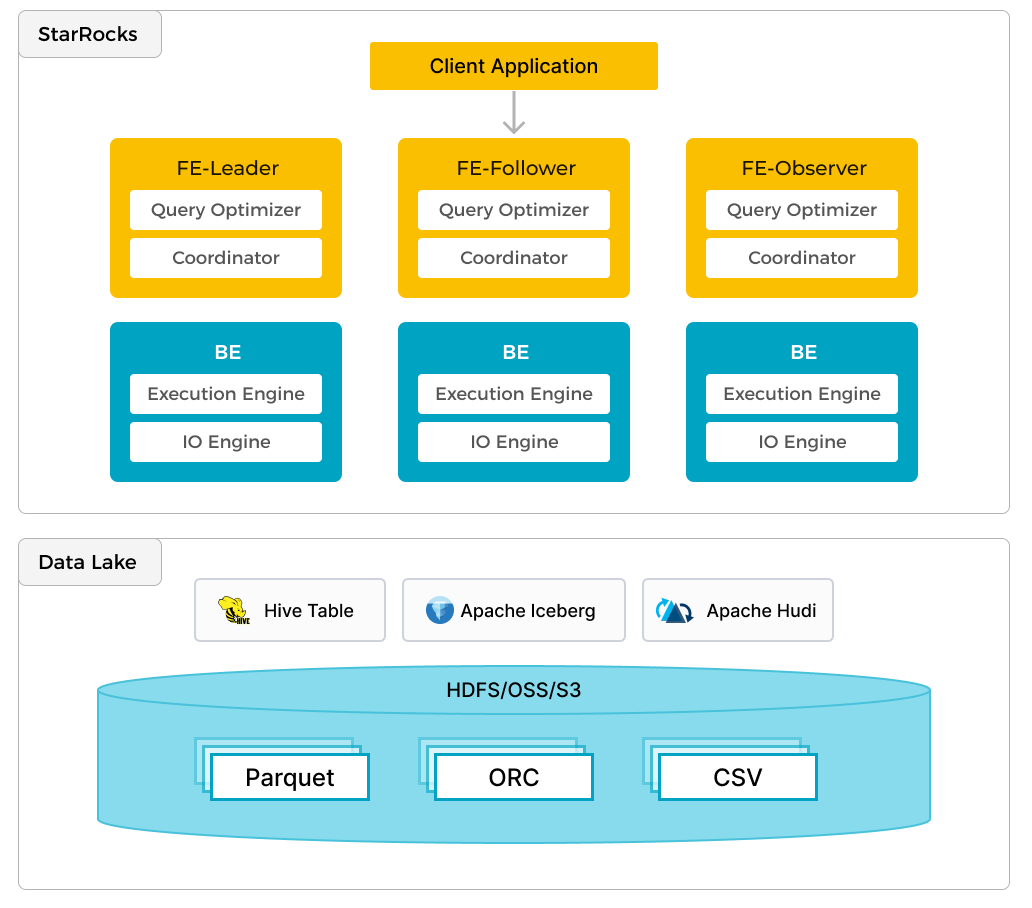
除了高效地分析本地数据外,StarRocks 还可以用作计算引擎来分析存储在 数据湖 中的数据,例如 Apache Hive、Apache Iceberg、Apache Hudi 和 Delta Lake。StarRocks 的主要功能之一是其外部 Catalog,它充当与外部维护的元存储的链接。此功能为用户提供了无缝查询外部数据源的能力,无需数据迁移。因此,用户可以分析来自不同系统的数据,例如 HDFS 和 Amazon S3,以及各种文件格式,例如 Parquet、ORC 和 CSV 等。
上图显示了一个数据湖分析场景,其中 StarRocks 负责数据计算和分析,数据湖负责数据存储、组织和维护。数据湖允许用户以开放存储格式存储数据,并使用灵活的模式为各种 BI、AI、临时和报告用例生成“单一事实来源”报告。StarRocks 充分利用其向量化引擎和 CBO 的优势,显着提高了数据湖分析的性能。