架构
StarRocks 的架构很简单。整个系统只包含两种类型的组件:前端和后端。前端节点称为 FE。后端节点有两种类型,BE 和 CN (计算节点)。当使用数据的本地存储时,部署 BE;当数据存储在对象存储或 HDFS 上时,部署 CN。 StarRocks 不依赖于任何外部组件,从而简化了部署和维护。节点可以水平扩展,而不会造成服务中断。此外,StarRocks 具有元数据和服务数据的副本机制,可提高数据可靠性并有效防止单点故障 (SPOF)。
StarRocks 兼容 MySQL 协议并支持标准 SQL。用户可以轻松地从 MySQL 客户端连接到 StarRocks,以获得即时且有价值的见解。
架构选择
StarRocks 支持 Shared-Nothing (每个 BE 都有其本地存储上的一部分数据) 和 Shared-Data (所有数据都在对象存储或 HDFS 上,并且每个 CN 仅在本地存储上具有缓存)。您可以根据需要决定数据的存储位置。
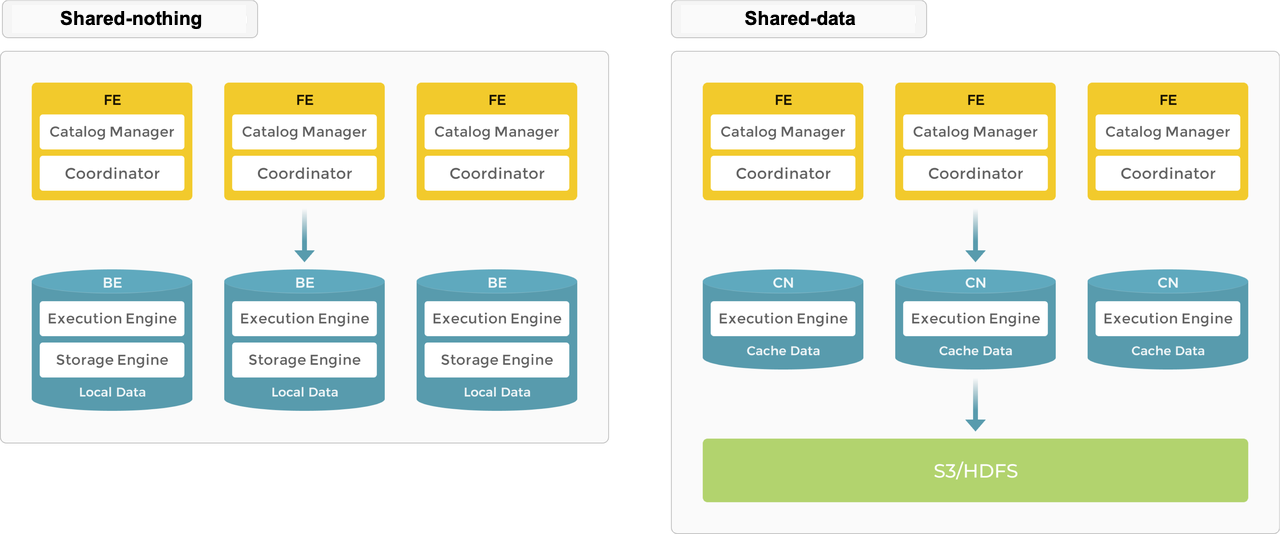
Shared-Nothing
本地存储为实时查询提供了更好的查询延迟。
作为一种典型的海量并行处理 (MPP) 数据库,StarRocks 支持 Shared-Nothing 架构。在此架构中,BE 负责数据存储和计算。直接访问 BE 模式下的本地数据允许本地计算,从而避免数据传输和数据复制,并提供超快的查询和分析性能。此架构支持多副本数据存储,增强了集群处理高并发查询的能力,并确保了数据可靠性。它非常适合追求最佳查询性能的场景。
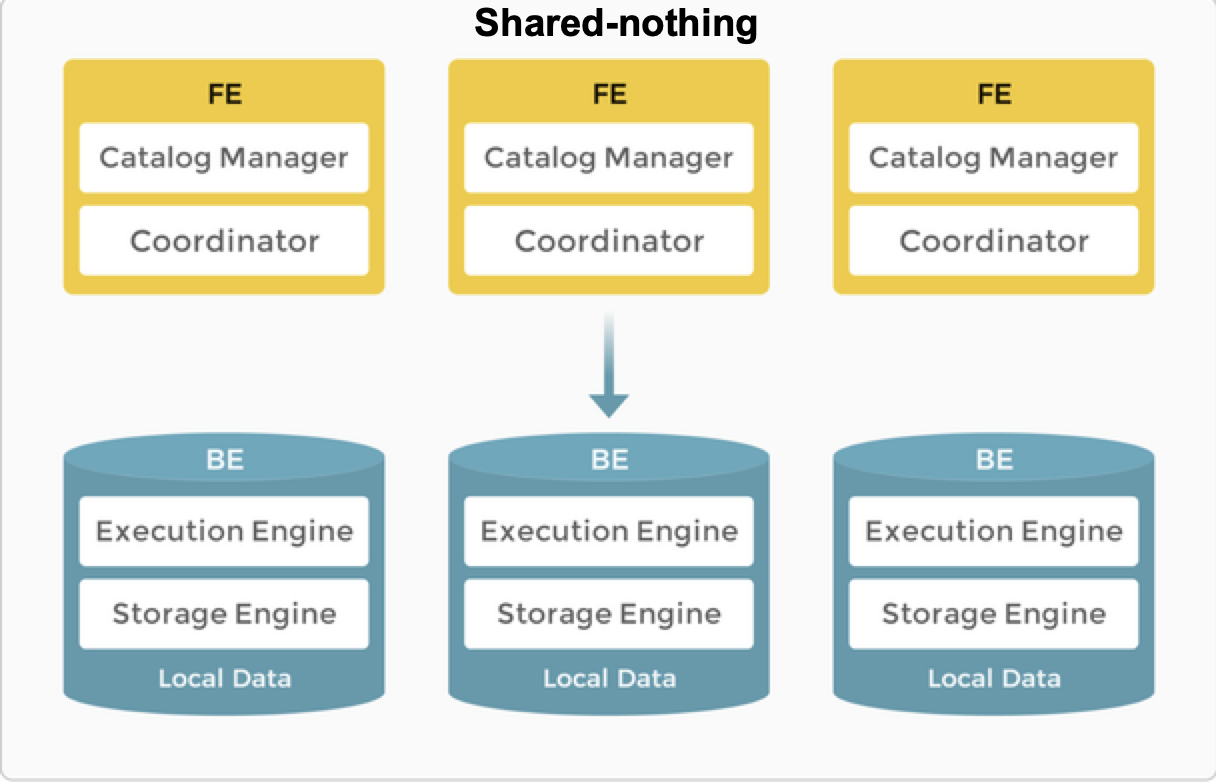
节点
在 Shared-Nothing 架构中,StarRocks 由两种类型的节点组成:FE 和 BE。
- FE 负责元数据管理和构建执行计划。
- BE 执行查询计划并存储数据。 BE 利用本地存储来加速查询,并使用多副本机制来确保高数据可用性。
FE
FE 负责元数据管理、客户端连接管理、查询规划和查询调度。每个 FE 使用 BDB JE (Berkeley DB Java Edition) 在其内存中存储和维护元数据的完整副本,从而确保所有 FE 上的服务一致。 FE 可以充当 leader、follower 和 observer。如果 leader 节点崩溃,follower 会根据 Raft 协议选举出一个 leader。
| FE 角色 | 元数据管理 | Leader 选举 |
|---|---|---|
| Leader | Leader FE 读取和写入元数据。 Follower 和 Observer FE 只能读取元数据。它们将元数据写入请求路由到 Leader FE。 Leader FE 更新元数据,然后使用 Raft 协议将元数据更改同步到 Follower 和 Observer FE。仅当元数据更改同步到超过一半的 Follower FE 时,数据写入才被视为成功。 | 从技术上讲,Leader FE 也是一个 Follower 节点,并且是从 Follower FE 中选出的。要执行 Leader 选举,集群中必须有超过一半的 Follower FE 处于活动状态。当 Leader FE 失败时,Follower FE 将开始另一轮 Leader 选举。 |
| Follower | Follower 只能读取元数据。它们从 Leader FE 同步和重播日志以更新元数据。 | Follower 参与 Leader 选举,这需要集群中超过一半的 Follower 处于活动状态。 |
| Observer | Observer 从 Leader FE 同步和重播日志以更新元数据。 | Observer 主要用于增加集群的查询并发性。 Observer 不参与 Leader 选举,因此不会增加集群的 Leader 选择压力。 |
BE
BE 负责数据存储和 SQL 执行。
-
数据存储:BE 具有等效的数据存储能力。 FE 根据预定义的规则将数据分发到 BE。 BE 转换摄取的数据,将数据写入所需的格式,并为数据生成索引。
-
SQL 执行:FE 根据查询的语义将每个 SQL 查询解析为逻辑执行计划,然后将逻辑计划转换为可以在 BE 上执行的物理执行计划。存储目标数据的 BE 执行查询。这消除了数据传输和复制的需要,从而实现了高查询性能。
Shared-Data
对象存储和 HDFS 提供了成本、可靠性和可扩展性优势。除了存储的可扩展性之外,可以添加和删除 CN 节点,而无需重新平衡数据,因为存储和计算是分开的。
在 Shared-Data 架构中,BE 被“计算节点 (CN)”取代,这些节点仅负责数据计算任务和缓存热数据。数据存储在低成本且可靠的远程存储系统中,例如 Amazon S3、GCP、Azure Blob Storage、MinIO 等。当缓存命中时,查询性能与 Shared-Nothing 架构相当。可以根据需要在几秒钟内添加或删除 CN 节点。此架构降低了存储成本,确保了更好的资源隔离以及高弹性和可扩展性。
Shared-Data 架构与其 Shared-Nothing 架构一样,保持着简单的架构。它仅包含两种类型的节点:FE 和 CN。唯一的区别是用户必须配置后端对象存储。
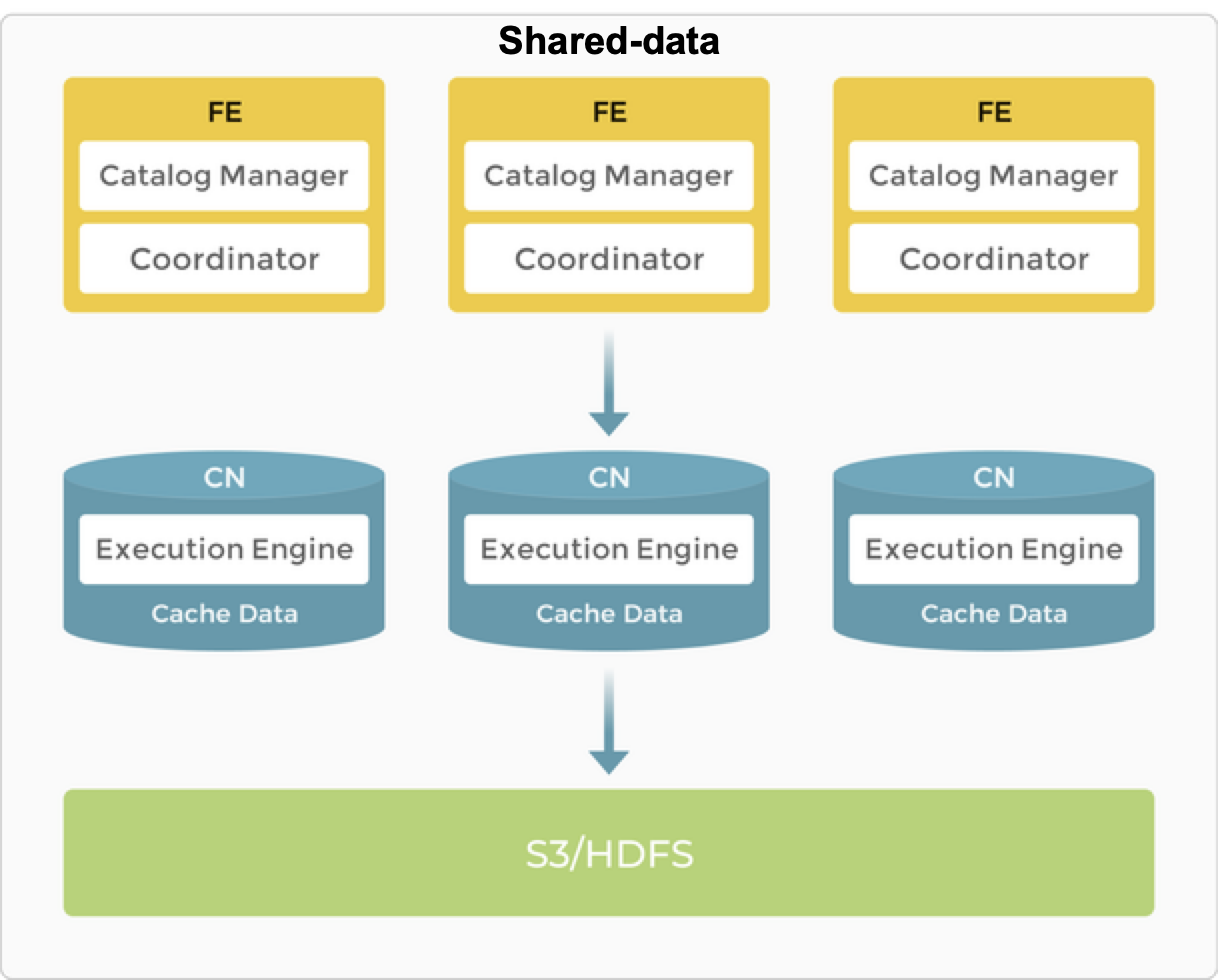
节点
Shared-Data 架构中的 FE 提供与 Shared-Nothing 架构中相同的功能。
BE 被 CN (计算节点) 取代,存储功能被卸载到对象存储或 HDFS。 CN 是无状态计算节点,执行 BE 的所有功能,除了数据存储。
存储
StarRocks Shared-Data 集群支持两种存储解决方案:对象存储 (例如,AWS S3、Google GCS、Azure Blob Storage 或 MinIO) 和 HDFS。
在 Shared-Data 集群中,数据文件格式与 Shared-Nothing 集群 (具有耦合的存储和计算) 的数据文件格式保持一致。数据被组织成段文件,并且各种索引技术在云原生表中被重用,云原生表是专门在 Shared-Data 集群中使用的表。
缓存
StarRocks Shared-Data 集群将数据存储和计算分离,允许每个独立扩展,从而降低成本并提高弹性。但是,此架构可能会影响查询性能。
为了减轻影响,StarRocks 建立了一个多层数据访问系统,包括内存、本地磁盘和远程存储,以更好地满足各种业务需求。
针对热数据的查询直接扫描缓存,然后扫描本地磁盘,而冷数据需要从对象存储加载到本地缓存中,以加速后续查询。通过将热数据保持在靠近计算单元的位置,StarRocks 实现了真正的高性能计算和经济高效的存储。此外,通过数据预取策略优化了对冷数据的访问,有效地消除了查询的性能限制。
创建表时可以启用缓存。如果启用了缓存,数据将被写入本地磁盘和后端对象存储。在查询期间,CN 节点首先从本地磁盘读取数据。如果未找到数据,将从后端对象存储中检索数据,并同时缓存在本地磁盘上。
动手学习
尝试快速入门以了解在实际场景中使用 StarRocks 的概况。