Dataphin
Dataphin 是阿里巴巴集团 OneData 数据治理方法论的内部实践的云端输出。它提供大数据整个生命周期中的数据集成、建设、管理和利用的一站式解决方案,旨在帮助企业显著提高数据治理水平,并构建一个高质量、可靠、便捷消费以及安全经济生产的企业级数据中台。Dataphin 提供多种计算平台支持和可扩展的开放能力,以满足各行业企业的平台技术架构和特定需求。
有几种方法可以将 Dataphin 与 StarRocks 集成
-
作为数据集成的数据源或目标数据源。可以从 StarRocks 读取数据并推送到其他数据源,也可以从其他数据源拉取数据并写入 StarRocks。
-
作为 Flink SQL 和 Datastram 开发的源表(无界扫描)、维度表(有界扫描)或结果表(流式 Sink 和批量 Sink)。
-
作为数据仓库或数据集市。StarRocks 可以注册为计算源,用于 SQL 脚本开发、调度、数据质量检测、安全识别和其他数据研究和治理任务。
数据集成
您可以创建 StarRocks 数据源,并在离线集成任务中使用 StarRocks 数据源作为源数据库或目标数据库。步骤如下
创建 StarRocks 数据源
基本信息

-
名称:必填。输入数据源名称。只能包含中文字符、字母、数字、下划线 (_) 和连字符 (-)。长度不能超过 64 个字符。
-
数据源代码:可选。配置数据源代码后,可以使用
数据源代码.表或数据源代码.schema.表格式在数据源中引用 Flink SQL。如果要自动访问相应环境中的数据源,请使用${数据源代码}.表或${数据源代码}.schema.表格式访问。注意
目前,仅支持 MySQL、Hologres 和 MaxCompute 数据源。
-
支持的场景:数据源可以应用的场景。
-
描述:可选。您可以输入数据源的简要说明。最多允许 128 个字符。
-
环境:如果业务数据源区分生产数据源和开发数据源,请选择“生产和开发”。如果业务数据源不区分生产和开发数据源,请选择“生产”。
-
标签:您可以选择标签来标记数据源。
配置信息

-
JDBC URL:必填。格式为
jdbc:mysql://<host>:<port>/<dbname>。host是 StarRocks 集群中 FE(前端)主机的 IP 地址,port是 FE 的查询端口,dbname是数据库名称。 -
Load URL:必填。格式为
fe_ip:http_port;fe_ip:http_port。fe_ip是 FE(前端)的主机,http_port是 FE 的端口。 -
用户名:必填。数据库的用户名。
-
密码:必填。数据库的密码。
高级设置

-
connectTimeout:数据库的 connectTimeout(以毫秒为单位)。默认值为 900000 毫秒(15 分钟)。
-
socketTimeout:数据库的 socketTimeout(以毫秒为单位)。默认值为 1800000 毫秒(30 分钟)。
从 StarRocks 数据源读取数据并将数据写入其他数据源
将 StarRocks 输入组件拖到离线集成任务画布

StarRocks 输入组件配置

-
步骤名称:根据当前组件的场景和位置输入适当的名称。
-
数据源:选择在 Dataphin 上创建的 StarRocks 数据源或项目。需要数据源的读取权限。如果没有满意的数据源,您可以添加数据源或申请相关权限。
-
源表:选择单个表或多个具有相同表结构的表作为输入。
-
表:从下拉列表中选择 StarRocks 数据源中的表。
-
拆分键:与并发配置一起使用。您可以使用源数据表中的一列作为拆分键。建议使用主键或索引列作为拆分键。
-
批量数:一批中提取的数据记录数。
-
输入过滤:可选。
在以下两种情况下,您需要填写过滤信息
- 如果要过滤数据的某个部分。
- 如果您需要每日增量追加数据或获取完整数据,则需要填写日期,其值设置为 Dataphin 控制台的系统时间。例如,StarRocks 中的一个事务表,其事务创建日期设置为
${bizdate}。
-
输出字段:根据输入表信息列出相关字段。您可以再次重命名、删除、添加和移动字段。一般来说,重命名字段是为了提高下游数据的可读性或方便输出时字段的映射。可以在输入阶段删除字段,因为在应用场景中不需要相关字段。更改字段的顺序是为了确保当合并多个输入数据或在下游侧输出时,可以通过映射同一行中具有不同名称的字段来有效地合并数据或映射输出数据。
选择和配置输出组件作为目标数据源

从其他数据源读取数据并将数据写入 StarRocks 数据源
在离线集成任务中配置输入组件,并选择和配置 StarRocks 输出组件作为目标数据源
配置 StarRocks 输出组件

-
步骤名称:根据当前组件的场景和位置输入适当的名称。
-
数据源:选择在 StarRocks 中创建的 Dataphin 数据源或项目。配置人员具有同步写入权限的数据源。如果数据源不满意,您可以添加数据源或申请相关权限。
-
表:从下拉列表中选择 StarRocks 数据源中的表。
-
一键生成目标表:如果在 StarRocks 数据源中未创建目标表,您可以自动获取从上游读取的字段的名称、类型和备注,并生成表创建语句。单击以一键生成目标表。
-
CSV 导入列分隔符:使用 StreamLoad CSV 导入。您可以配置 CSV 导入列分隔符。默认值
\t。不要在此处指定默认值。如果数据本身包含\t,则必须使用其他字符作为分隔符。 -
CSV 导入行分隔符:使用 StreamLoad CSV 导入。您可以配置 CSV 导入行分隔符。默认值:
\n。不要在此处指定默认值。如果数据本身包含\n,则必须使用其他字符作为分隔符。 -
解析方案:可选。这是在写入数据之前或之后的一些特殊处理。准备语句在数据写入 StarRocks 数据源之前执行,完成语句在数据写入后执行。
-
字段映射:您可以手动选择字段进行映射,也可以使用基于名称或位置的映射来一次处理多个字段,具体取决于来自上游输入中的字段和目标表中的字段。
实时开发
简要介绍
StarRocks 是一个快速且可扩展的实时分析数据库。它通常用于实时计算中,以读取和写入数据,以满足实时数据分析和查询的需求。它广泛应用于企业实时计算场景。可用于实时业务监控和分析、实时用户行为分析、实时广告竞价系统、实时风险控制、反欺诈、实时监控和预警等应用场景。通过实时分析和查询数据,企业可以快速了解业务状况、优化决策、提供更好的服务和保护自身利益。
StarRocks Connector
StarRocks 连接器支持以下信息
| 类别 | 事实和数字 |
|---|---|
| 支持的类型 | 源表、维度表、结果表 |
| 运行模式 | 流模式和批处理模式 |
| 数据格式 | JSON 和 CSV |
| 特殊指标 | None (无) |
| API 类型 | Datastream 和 SQL |
| 是否支持更新或删除结果表中的数据? | 是 |
如何使用它?
Dataphin 支持将 StarRocks 数据源作为实时计算的读取和写入目标。您可以创建 StarRocks 元表,并将它们用于实时计算任务
创建 StarRocks 元表
-
转到 Dataphin > 研发 > 开发 > 表。
-
单击 创建 以选择实时计算表。

-
表类型:选择 元表。
-
元表:输入元表的名称。名称不可变。
-
数据源:选择 StarRocks 数据源。
-
目录:选择要创建表的目录。
-
描述:可选。

-
-
创建元表后,您可以编辑元表,包括修改数据源、源表、元表字段和配置元表参数。

-
提交元表。
创建 Flink SQL 任务以将数据从 Kafka 实时写入 StarRocks
-
转到 Dataphin > 研发 > 开发 > 计算任务。
-
单击 创建 Flink SQL 任务。

-
编辑 Flink SQL 代码并预编译它。Kafka 元表用作输入表,StarRocks 元表用作输出表。


-
预编译成功后,您可以调试并提交代码。
-
可以通过打印日志和写入测试表来在开发环境中进行测试。可以在元表 > 属性 > 调试测试配置中设置测试表。


-
开发环境中的任务正常运行后,您可以将任务和使用的元表发布到生产环境。

-
启动生产环境中的任务以将数据从 Kafka 实时写入 StarRocks。您可以查看运行分析中每个指标的状态和日志,以了解任务运行状态,或为任务配置监控警报。


数据仓库或数据集市
前提条件
-
StarRocks 版本为 3.0.6 或更高版本。
-
已安装 Dataphin,Dataphin 版本为 3.12 或更高版本。
-
必须启用统计信息收集。安装 StarRocks 后,默认情况下启用收集。有关更多信息,请参阅 收集 CBO 的统计信息。
-
支持 StarRocks 内部目录(默认目录),不支持外部目录。
连接配置
元数据仓库设置
Dataphin 可以根据元数据呈现和显示信息,包括表使用信息和元数据更改。您可以使用 StarRocks 来处理和计算元数据。因此,在使用元数据之前,您需要初始化元数据计算引擎(元数据仓库)。步骤如下
-
使用管理员帐户登录到 Dataphin 元数据仓库租户
-
转到管理 > 系统 > 元数据仓库配置
a. 单击启动
b. 选择 StarRocks
c. 配置参数。通过连接测试后,单击下一步。
d. 完成元数据仓库初始化

参数描述如下
-
JDBC URL:JDBC 连接字符串,分为两部分
-
第一部分:格式为
jdbc:mysql://<Host>:<Port>/。Host是 StarRocks 集群中 FE 主机的 IP 地址。Port是 FE 的查询端口。默认值:9030。 -
第二部分:格式为
database? key1 = value1 & key2 = value2,其中database是用于元数据计算的 StarRocks 数据库的名称,这是必需的。'?' 之后的参数是可选的。
-
-
Load URL:格式为
fe_ip:http_port;fe_ip:http_port。fe_ip是 FE(前端)的主机,http_port是 FE 的端口。 -
用户名:用于连接到 StarRocks 的用户名。
用户需要对 JDBC URL 中指定的数据库具有读写权限,并且必须对以下数据库和表具有访问权限
-
Information Schema 中的所有表
-
statistics.column_statistics
-
statistics.table_statistic_v1
-
-
密码:StarRocks 链接的密码。
-
元项目:在 Dataphin 中用于元数据处理的项目的名称。它仅在 Dataphin 系统中使用。我们建议您使用
dataphin_meta作为项目名称。
创建 StarRocks 项目并启动数据开发
要启动数据开发,请按照以下步骤操作
-
计算设置。
-
创建 StarRocks 计算源。
-
创建一个项目。
-
创建 StarRocks SQL 任务。
计算设置
计算设置设置租户的计算引擎类型和集群地址。详细步骤如下
-
以系统管理员或超级管理员身份登录到 Dataphin。
-
转到 管理 > 系统 > 计算配置。
-
选择 StarRocks,然后单击 下一步。
-
输入 JDBC URL 并验证它。JDBC URL 的格式为
jdbc:mysql://<Host>:<Port>/。Host是 StarRocks 集群中 FE 主机的 IP 地址。Port是 FE 的查询端口。默认值:9030。
StarRocks 计算源
计算源是 Dataphin 的一个概念。其主要目的是将 Dataphin 项目空间与 StarRocks 存储计算空间(数据库)绑定和注册。您必须为每个项目创建一个计算源。详细步骤如下
-
以系统管理员或超级管理员身份登录到 Dataphin。
-
转到 规划 > 引擎。
-
单击右上角的 添加计算引擎 以创建计算源。
详细配置信息如下
-
基本信息

-
计算引擎类型:选择 StarRocks。
-
计算引擎名称:我们建议您使用与要创建的项目相同的名称。对于开发项目,添加后缀
_dev。 -
描述:可选。输入计算源的描述。
-
-
配置信息
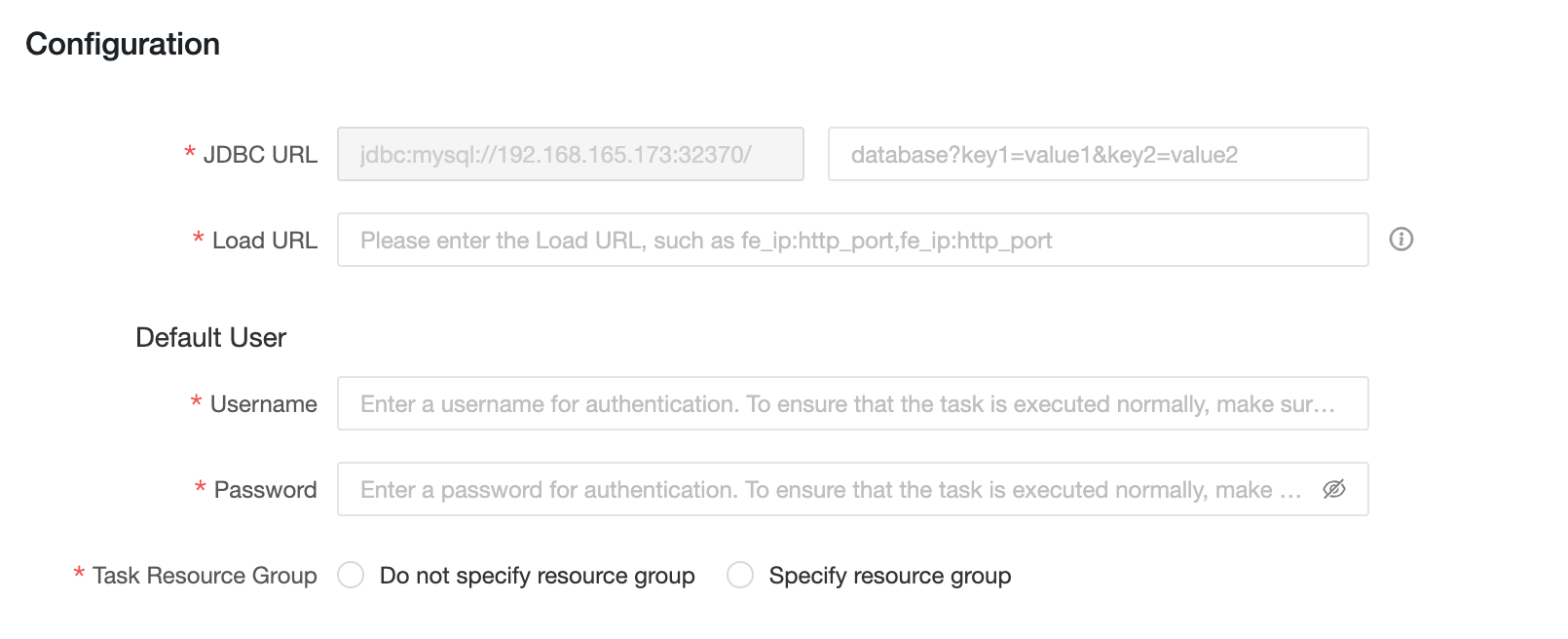
-
JDBC URL:格式为
jdbc:mysql://<Host>:<Port>/。Host是 StarRocks 集群中 FE 主机的 IP 地址。Port是 FE 的查询端口。默认值:9030。 -
Load URL:格式为
fe_ip:http_port;fe_ip:http_port。fe_ip是 FE(前端)的主机,http_port是 FE 的端口。 -
用户名:用于连接到 StarRocks 的用户名。
-
密码:StarRocks 的密码。
-
任务资源组:您可以为具有不同优先级的任务指定不同的 StarRocks 资源组。当您选择不指定资源组时,StarRocks 引擎将确定要执行的资源组。当您选择指定资源组时,具有不同优先级的任务将由 Dataphin 分配给指定的资源组。如果在 SQL 任务的代码中或逻辑表的物化配置中指定了资源组,则在执行任务时将忽略计算源任务的资源组配置。

-
Dataphin 项目
创建计算源后,您可以将其绑定到 Dataphin 项目。Dataphin 项目管理项目成员、StarRocks 存储和计算空间,以及管理和维护计算任务。
要创建 Dataphin 项目,请按照以下步骤操作
-
以系统管理员或超级管理员身份登录到 Dataphin。
-
转到 规划 > 项目管理。
-
单击右上角的 创建项目 以创建一个项目。
-
输入基本信息,然后从离线引擎中选择在上一步中创建的 StarRocks 引擎。
-
单击 创建。
StarRocks SQL
创建项目后,您可以创建一个 StarRocks SQL 任务以对 StarRocks 执行 DDL 或 DML 操作。
详细步骤如下
-
转到 研发 > 开发。
-
单击右上角的“+”以创建 StarRocks SQL 任务。

-
输入名称和调度类型以创建 SQL 任务。
-
在编辑器中输入 SQL 以开始对 StarRock 执行 DDL 和 DML 操作。
