数据湖仓
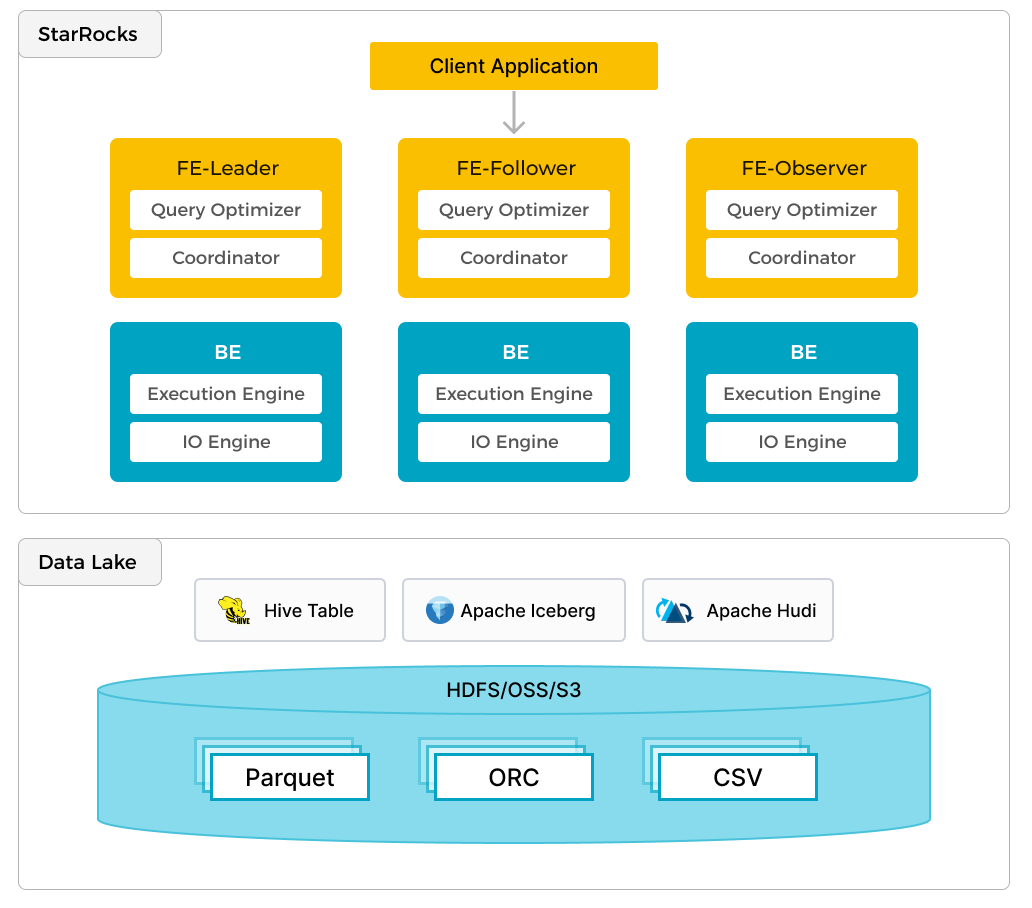
除了高效分析本地数据外,StarRocks 还可以作为计算引擎来分析存储在 data lake 中的数据,例如 Apache Hudi、Apache Iceberg 和 Delta Lake。 StarRocks 的主要功能之一是它的外部 Catalog,它充当与外部维护的元数据存储的链接。此功能使用户能够无缝查询外部数据源,而无需数据迁移。因此,用户可以分析来自不同系统(例如 HDFS 和 Amazon S3)的数据,以各种文件格式(例如 Parquet、ORC 和 CSV 等)。
上图显示了一个 data lake 分析场景,其中 StarRocks 负责数据计算和分析,而 data lake 负责数据存储、组织和维护。 Data lake 允许用户以开放存储格式存储数据,并使用灵活的 Schema 生成各种 BI、AI、Ad-hoc 和报告用例的“单一事实来源”的报告。 StarRocks 充分利用其向量化引擎和 CBO 的优势,显着提高了 data lake 分析的性能。
主要思路
- 开放数据格式:支持多种数据类型,包括 JSON、Parquet 和 Avro,方便结构化和非结构化数据的存储和处理。
- 元数据管理:实现共享元数据层,通常利用 Iceberg 表格式等格式,以有效地组织和管理数据。
- 多样化的查询引擎:结合了多个引擎,如 Presto 和 Spark 的增强版本,以满足各种分析和 AI 用例。
- 治理和安全性:具有强大的内置机制,用于数据安全、隐私和合规性,确保数据的完整性和可信度。
Data Lakehouse 架构的优势
- 灵活性和可扩展性:无缝管理各种数据类型,并根据组织的需求进行扩展。
- 成本效益:与传统方法相比,为数据存储和处理提供了一种经济的替代方案。
- 增强的数据治理:改进了数据控制、管理和完整性,确保可靠和安全的数据处理。
- AI 和分析就绪:非常适合复杂的分析任务,包括机器学习和 AI 驱动的数据处理。
StarRocks 方法
需要考虑的关键事项是
- 标准化与 Catalog 或元数据服务的集成
- 计算节点的弹性可扩展性
- 灵活的缓存机制
Catalogs
StarRocks 有两种类型的 Catalog:内部 Catalog 和外部 Catalog。 内部 Catalog 包含 StarRocks 数据库中存储的数据的元数据。 外部 Catalog 用于处理外部存储的数据,包括由 Hive、Iceberg、Delta Lake 和 Hudi 管理的数据。 还有许多其他外部系统,链接位于页面底部的更多信息部分。
计算节点 (CN) 扩展
存储和计算分离降低了扩展的复杂性。 由于 StarRocks 计算节点仅存储本地缓存,因此可以根据负载添加或删除节点。
数据缓存
计算节点上的缓存是可选的。 如果您的计算节点根据快速变化的负载模式快速启动和关闭,或者您的查询通常仅针对最新数据,则缓存数据可能没有意义。
🗃️ Catalog
14 个项目
🗃️ 数据缓存
4 个项目
📄️ 外部表
- 从 v3.0 开始,我们建议您使用 Catalog 从 Hive、Iceberg 和 Hudi 查询数据。 请参阅 Hive catalog、Iceberg catalog 和 Hudi catalog。
📄️ File 外部表
文件外部表是一种特殊的外部表。 它允许您直接查询外部存储系统中的 Parquet 和 ORC 数据文件,而无需将数据加载到 StarRocks 中。 此外,文件外部表不依赖于元数据存储。 在当前版本中,StarRocks 支持以下外部存储系统:HDFS、Amazon S3 和其他 S3 兼容的存储系统。
📄️ Data lake 常见问题
本主题介绍了一些关于 data lake 的常见问题 (FAQ),并提供了针对这些问题的解决方案。 本主题中提到的一些指标只能从 SQL 查询的 profiles 中获得。 要获得 SQL 查询的 profiles,您必须指定 set enable_profile=true。
📄️ 功能支持
从 v2.3 开始,StarRocks 支持通过外部 Catalog 管理外部数据源和分析 data lake 中的数据。