数据缓存
本文介绍了 Data Cache 的工作原理,以及如何启用 Data Cache 以提高对外部数据查询的性能。从 v3.3.0 起,默认启用 Data Cache。
在数据湖分析中,StarRocks 充当 OLAP 引擎,扫描存储在 HDFS 和 Amazon S3 等外部存储系统中的数据文件。随着要扫描的文件数量增加,I/O 开销也会增加。此外,在某些即席查询场景中,频繁访问相同的数据会使 I/O 开销翻倍。
为了优化这些场景中的查询性能,StarRocks 2.5 提供了 Data Cache 功能。此功能根据预定义的策略将外部存储系统中的数据拆分为多个块,并将数据缓存在 StarRocks 后端 (BE) 上。这消除了每次访问请求都需要从外部系统拉取数据的需要,并加速了对热数据的查询和分析。Data Cache 仅在您使用外部 Catalog 或外部表(不包括 JDBC 兼容数据库的外部表)查询外部存储系统中的数据时有效。查询 StarRocks 原生表时无效。
工作原理
StarRocks 将外部存储系统中的数据拆分为多个大小相同的块(默认为 1 MB),并将数据缓存在 BE 上。块是数据缓存的最小单元,可以配置。
例如,如果将块大小设置为 1 MB,并且要从 Amazon S3 查询 128 MB 的 Parquet 文件,StarRocks 会将该文件拆分为 128 个块。这些块是 [0, 1 MB)、[1 MB, 2 MB)、[2 MB, 3 MB) ... [127 MB, 128 MB)。StarRocks 为每个块分配一个全局唯一 ID,称为缓存键。缓存键由以下三个部分组成。
hash(filename) + fileModificationTime + blockId
下表提供了每个部分的描述。
| 组件项 | 描述 |
|---|---|
| 文件名 | 数据文件的名称。 |
| fileModificationTime | 数据文件的最后修改时间。 |
| blockId | StarRocks 在拆分数据文件时分配给块的 ID。该 ID 在同一个数据文件下是唯一的,但在您的 StarRocks 集群中不是唯一的。 |
如果查询命中 [1 MB, 2 MB) 块,StarRocks 将执行以下操作
- 检查缓存中是否存在该块。
- 如果该块存在,StarRocks 从缓存中读取该块。如果该块不存在,StarRocks 从 Amazon S3 读取该块并将其缓存在 BE 上。
启用 Data Cache 后,StarRocks 会缓存从外部存储系统读取的数据块。
数据块的存储介质
StarRocks 使用 BE 机器的内存和磁盘来缓存块。它支持仅在内存中缓存,或者在内存和磁盘中都缓存。
如果您使用磁盘作为存储介质,缓存速度会直接受到磁盘性能的影响。因此,我们建议您使用高性能磁盘(如 NVMe 磁盘)进行数据缓存。如果您没有高性能磁盘,可以添加更多磁盘来缓解磁盘 I/O 压力。
缓存替换策略
StarRocks 支持内存和磁盘的分层缓存。您还可以根据您的业务需求配置仅使用全内存缓存或仅使用全磁盘缓存。
同时使用内存缓存和磁盘缓存时
- StarRocks 首先从内存中读取数据。如果在内存中未找到数据,StarRocks 将从磁盘中读取数据,并尝试将从磁盘中读取的数据加载到内存中。
- 从内存中丢弃的数据将被写入磁盘。从磁盘中丢弃的数据将被删除。
内存缓存和磁盘缓存根据它们自己的驱逐策略来驱逐缓存项。StarRocks 现在支持 LRU(最近最少使用)和 SLRU(分段 LRU)策略来缓存和驱逐数据。默认策略是 SLRU。
使用 SLRU 策略时,缓存空间被划分为驱逐段和保护段,这两个段都由 LRU 策略控制。首次访问数据时,它会进入驱逐段。驱逐段中的数据只有在再次访问时才会进入保护段。如果保护段中的数据被驱逐,它将再次进入驱逐段。如果驱逐段中的数据被驱逐,它将从缓存中删除。与 LRU 相比,SLRU 可以更好地抵抗突发的稀疏流量,并避免保护段数据被仅访问过一次的数据直接驱逐。
启用 Data Cache
现在,Data Cache 默认启用,系统以下列方式缓存数据
- 系统变量
enable_scan_datacache和 BE 参数datacache_enable默认设置为true。 - 在
storage_root_path下创建一个 datacache 目录作为缓存目录。从 v3.4.0 开始,不再支持直接更改磁盘缓存路径。如果要设置路径,可以创建一个符号链接。 - 如果未配置内存和磁盘限制,系统将按照以下规则自动设置内存和磁盘限制
- 系统启用 Data Cache 的自动磁盘空间调整。它设置限制以确保整体磁盘使用率在 80% 左右,并根据后续磁盘使用情况动态调整。(您可以使用 BE 参数
datacache_disk_high_level、datacache_disk_safe_level和datacache_disk_low_level修改此行为。) - Data Cache 的默认内存限制为
0。(您可以使用 BE 参数datacache_mem_size修改此设置。)
- 系统启用 Data Cache 的自动磁盘空间调整。它设置限制以确保整体磁盘使用率在 80% 左右,并根据后续磁盘使用情况动态调整。(您可以使用 BE 参数
- 系统默认采用异步缓存填充,以尽量减少其对数据读取操作的影响。
- 默认启用 I/O 适配器功能。当磁盘 I/O 负载较高时,系统会自动将某些请求路由到远程存储以降低磁盘压力。
要禁用 Data Cache,请执行以下语句
SET GLOBAL enable_scan_datacache=false;
填充数据缓存
填充规则
从 v3.3.2 开始,为了提高 Data Cache 的缓存命中率,StarRocks 根据以下规则填充 Data Cache
- 不会为非
SELECT语句填充缓存,例如ANALYZE TABLE和INSERT INTO SELECT。 - 扫描表的所有分区的查询不会填充缓存。但是,如果表只有一个分区,则默认执行填充。
- 扫描表的所有列的查询不会填充缓存。但是,如果表只有一列,则默认执行填充。
- 不会为非 Hive、Paimon、Delta Lake、Hudi 或 Iceberg 表填充缓存。
您可以使用 EXPLAIN VERBOSE 命令查看特定查询的填充行为。
示例
mysql> explain verbose select col1 from hudi_table;
| 0:HudiScanNode |
| TABLE: hudi_table |
| partitions=3/3 |
| cardinality=9084 |
| avgRowSize=2.0 |
| dataCacheOptions={populate: false} |
| cardinality: 9084 |
+-----------------------------------------+
dataCacheOptions={populate: false} 表示由于查询将扫描所有分区,因此不会填充缓存。
您还可以通过会话变量 populate_datacache_mode 微调 Data Cache 的填充行为。
填充模式
StarRocks 支持以同步或异步模式填充 Data Cache。
-
同步缓存填充
在同步填充模式下,当前查询读取的所有远程数据都会在本地缓存。同步填充效率很高,但可能会影响初始查询的性能,因为它发生在数据读取期间。
-
异步缓存填充
在异步填充模式下,系统尝试在后台缓存访问的数据,以尽量减少对读取性能的影响。异步填充可以减少缓存填充对初始读取的性能影响,但填充效率低于同步填充。通常,单个查询不能保证可以缓存所有访问的数据。可能需要多次尝试才能缓存所有访问的数据。
从 v3.3.0 开始,默认启用异步缓存填充。您可以通过设置会话变量 enable_datacache_async_populate_mode 来更改填充模式。
持久化
磁盘中缓存的数据默认可以持久化,这些数据可以在 BE 重启后重复使用。
检查查询是否命中数据缓存
您可以通过分析查询 profile 中的以下指标来检查查询是否命中数据缓存
DataCacheReadBytes:StarRocks 直接从其内存和磁盘读取的数据大小。DataCacheWriteBytes:从外部存储系统加载到 StarRocks 内存和磁盘的数据大小。BytesRead:读取的总数据量,包括 StarRocks 从外部存储系统以及其内存和磁盘读取的数据。
示例 1:在此示例中,StarRocks 从外部存储系统读取大量数据 (7.65 GB),仅从内存和磁盘读取少量数据 (518.73 MB)。这意味着很少命中数据缓存。
- Table: lineorder
- DataCacheReadBytes: 518.73 MB
- __MAX_OF_DataCacheReadBytes: 4.73 MB
- __MIN_OF_DataCacheReadBytes: 16.00 KB
- DataCacheReadCounter: 684
- __MAX_OF_DataCacheReadCounter: 4
- __MIN_OF_DataCacheReadCounter: 0
- DataCacheReadTimer: 737.357us
- DataCacheWriteBytes: 7.65 GB
- __MAX_OF_DataCacheWriteBytes: 64.39 MB
- __MIN_OF_DataCacheWriteBytes: 0.00
- DataCacheWriteCounter: 7.887K (7887)
- __MAX_OF_DataCacheWriteCounter: 65
- __MIN_OF_DataCacheWriteCounter: 0
- DataCacheWriteTimer: 23.467ms
- __MAX_OF_DataCacheWriteTimer: 62.280ms
- __MIN_OF_DataCacheWriteTimer: 0ns
- BufferUnplugCount: 15
- __MAX_OF_BufferUnplugCount: 2
- __MIN_OF_BufferUnplugCount: 0
- BytesRead: 7.65 GB
- __MAX_OF_BytesRead: 64.39 MB
- __MIN_OF_BytesRead: 0.00
示例 2:在此示例中,StarRocks 从数据缓存中读取大量数据 (46.08 GB),没有从外部存储系统读取数据,这意味着 StarRocks 仅从数据缓存读取数据。
Table: lineitem
- DataCacheReadBytes: 46.08 GB
- __MAX_OF_DataCacheReadBytes: 194.99 MB
- __MIN_OF_DataCacheReadBytes: 81.25 MB
- DataCacheReadCounter: 72.237K (72237)
- __MAX_OF_DataCacheReadCounter: 299
- __MIN_OF_DataCacheReadCounter: 118
- DataCacheReadTimer: 856.481ms
- __MAX_OF_DataCacheReadTimer: 1s547ms
- __MIN_OF_DataCacheReadTimer: 261.824ms
- DataCacheWriteBytes: 0.00
- DataCacheWriteCounter: 0
- DataCacheWriteTimer: 0ns
- BufferUnplugCount: 1.231K (1231)
- __MAX_OF_BufferUnplugCount: 81
- __MIN_OF_BufferUnplugCount: 35
- BytesRead: 46.08 GB
- __MAX_OF_BytesRead: 194.99 MB
- __MIN_OF_BytesRead: 81.25 MB
Footer Cache
除了在针对数据湖的查询期间缓存远程存储中文件的数据外,StarRocks 还支持缓存从文件解析的元数据(Footer)。Footer Cache 直接将解析的 Footer 对象缓存在内存中。当后续查询访问同一文件的 Footer 时,可以直接从缓存中获取对象描述符,避免重复解析。
目前,StarRocks 支持缓存 Parquet Footer 对象。
您可以通过设置以下系统变量来启用 Footer Cache
SET GLOBAL enable_file_metacache=true;
注意
Footer Cache 使用 Data Cache 的内存模块进行数据缓存。因此,您必须确保 BE 参数
datacache_enable设置为true并为datacache_mem_size配置一个合理的值。
I/O 适配器
为了防止由于高缓存磁盘 I/O 负载导致磁盘访问中出现明显的尾部延迟,从而导致缓存系统的负优化,Data Cache 提供了 I/O 适配器功能。此功能在磁盘负载较高时将一些缓存请求路由到远程存储,从而利用本地缓存和远程存储来提高 I/O 吞吐量。默认启用此功能。
您可以通过设置以下系统变量来启用 I/O 适配器
SET GLOBAL enable_datacache_io_adaptor=true;
动态伸缩
Data Cache 支持手动调整缓存容量而无需重启 BE 进程,并且还支持自动调整缓存容量。
手动伸缩
您可以通过动态调整 BE 配置项来修改 Data Cache 的内存限制或磁盘容量。
示例
-- Adjust the Data Cache memory limit for a specific BE instance.
UPDATE be_configs SET VALUE="10G" WHERE NAME="datacache_mem_size" and BE_ID=10005;
-- Adjust the Data Cache memory ratio limit for all BE instances.
UPDATE be_configs SET VALUE="10%" WHERE NAME="datacache_mem_size";
-- Adjust the Data Cache disk limit for all BE instances.
UPDATE be_configs SET VALUE="2T" WHERE NAME="datacache_disk_size";
注意
- 以这种方式调整容量时要小心。确保不要省略 WHERE 子句,以避免修改无关的配置项。
- 以这种方式进行的缓存容量调整不会持久化,并且在 BE 进程重启后会丢失。因此,您可以首先如上所述动态调整参数,然后手动修改 BE 配置文件,以确保更改在下次重启后生效。
自动伸缩
StarRocks 目前支持自动伸缩磁盘容量。如果您未在 BE 配置中指定缓存磁盘路径和容量限制,则默认启用自动伸缩。
您还可以通过将以下配置项添加到 BE 配置文件并重启 BE 进程来启用自动伸缩
datacache_auto_adjust_enable=true
启用自动伸缩后
- 当磁盘使用率超过 BE 参数
datacache_disk_high_level指定的阈值(默认值为80,即 80% 的磁盘空间)时,系统将自动驱逐缓存数据以释放磁盘空间。 - 当磁盘使用率持续低于 BE 参数
datacache_disk_low_level指定的阈值(默认值为60,即 60% 的磁盘空间),并且 Data Cache 当前使用的磁盘空间已满时,系统将自动扩展缓存容量。 - 自动伸缩缓存容量时,系统将尝试将缓存容量调整到 BE 参数
datacache_disk_safe_level指定的级别(默认值为70,即 70% 的磁盘空间)。
缓存共享
由于 Data Cache 依赖于 BE 节点的本地磁盘,因此在扩展集群时,数据路由的更改可能会导致缓存未命中,这很容易导致弹性伸缩期间的性能下降。
缓存共享用于支持通过网络访问节点之间的缓存数据。在集群伸缩期间,如果发生本地缓存未命中,系统首先尝试从同一集群中的其他节点获取缓存数据。只有当所有缓存都未命中时,系统才会从远程存储重新获取数据。此功能有效地减少了弹性伸缩期间缓存失效引起的性能抖动,并确保了稳定的查询性能。
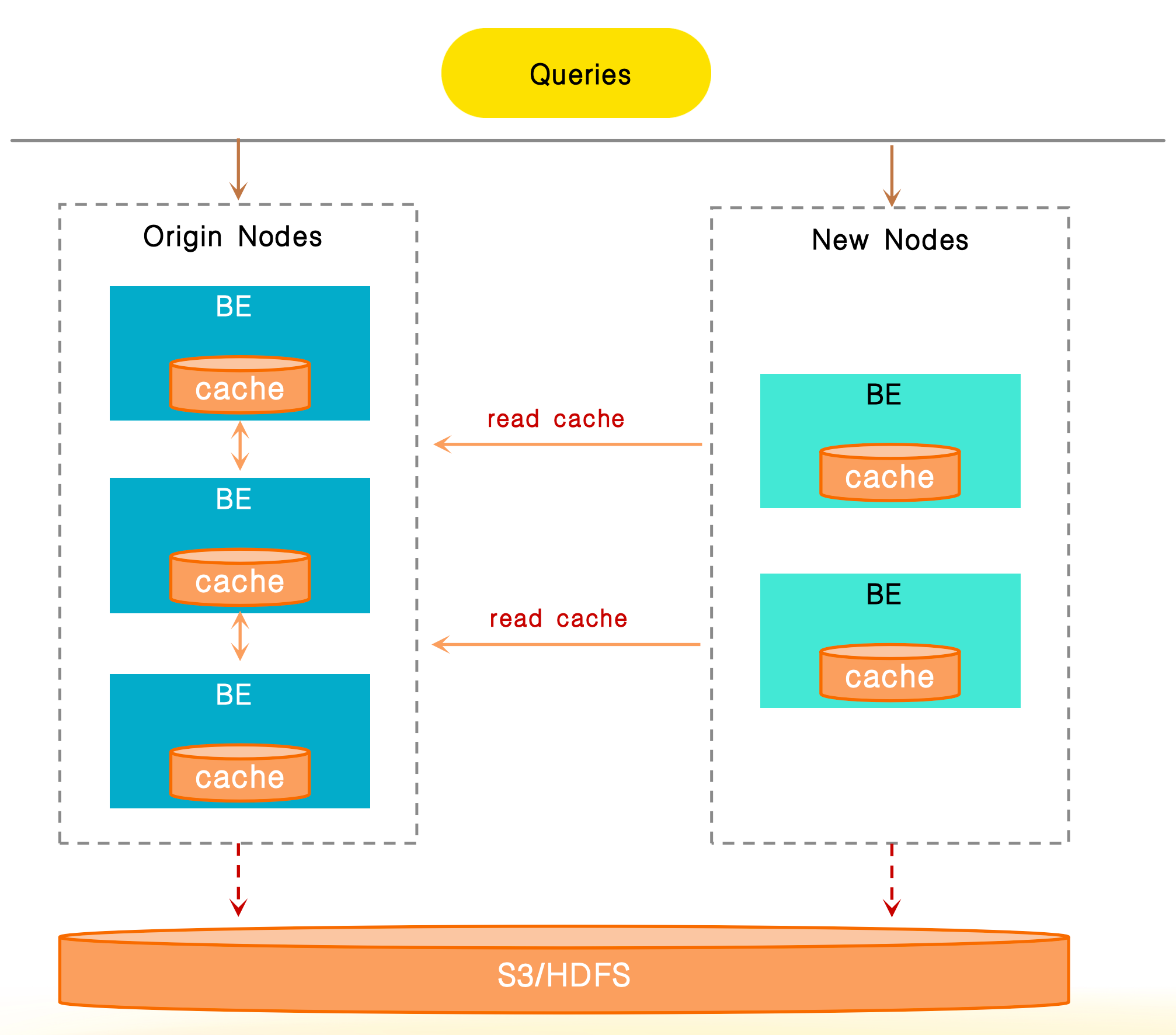
您可以通过配置以下两个项目来启用缓存共享功能
- 将 FE 配置项
enable_trace_historical_node设置为true。 - 将会话变量
enable_datacache_sharing设置为true。
此外,您可以在查询 profile 中检查以下指标以监视缓存共享
DataCacheReadPeerCounter:从其他缓存节点读取的计数。DataCacheReadPeerBytes:从其他缓存节点读取的字节数。DataCacheReadPeerTimer:用于从其他缓存节点访问缓存数据的时间。
配置和变量
您可以使用以下系统变量和参数来配置 Data Cache。
系统变量
- populate_datacache_mode
- enable_datacache_io_adaptor
- enable_file_metacache
- enable_datacache_async_populate_mode
- enable_datacache_sharing
FE 参数
BE 参数
- datacache_enable
- datacache_mem_size
- datacache_disk_size
- datacache_auto_adjust_enable
- datacache_disk_high_level
- datacache_disk_safe_level
- datacache_disk_low_level
- datacache_disk_adjust_interval_seconds
- datacache_disk_idle_seconds_for_expansion
- datacache_min_disk_quota_for_adjustment
- datacache_eviction_policy
- datacache_inline_item_count_limit