Hudi Catalog
Hudi catalog 是一种外部 catalog,无需数据导入即可查询 Apache Hudi 中的数据。
您还可以通过 Hudi catalog,使用 INSERT INTO 直接转换和加载 Hudi 中的数据。 StarRocks 从 v2.4 版本开始支持 Hudi catalog。
为了确保您可以在 Hudi 集群上成功运行 SQL 作业,您的 StarRocks 集群必须能够访问 Hudi 集群的存储系统和 Metastore。 StarRocks 支持以下存储系统和 Metastore:
-
分布式文件系统(HDFS)或对象存储,如 AWS S3、Microsoft Azure Storage、Google GCS 或其他 S3 兼容的存储系统(例如,MinIO)
-
Metastore,如 Hive Metastore 或 AWS Glue
注意
如果您选择 AWS S3 作为存储,则可以使用 HMS 或 AWS Glue 作为 Metastore。如果您选择任何其他存储系统,则只能使用 HMS 作为 Metastore。
使用说明
- StarRocks 支持 Hudi 的 Parquet 文件格式。 Parquet 文件支持以下压缩格式:SNAPPY、LZ4、ZSTD、GZIP 和 NO_COMPRESSION。
- StarRocks 完全支持 Hudi 的 Copy On Write (COW) 表和 Merge On Read (MOR) 表。
集成准备
在创建 Hudi catalog 之前,请确保您的 StarRocks 集群可以与 Hudi 集群的存储系统和 Metastore 集成。
AWS IAM
如果您的 Hudi 集群使用 AWS S3 作为存储或 AWS Glue 作为 Metastore,请选择合适的身份验证方式并做好必要的准备,以确保您的 StarRocks 集群可以访问相关的 AWS 云资源。
建议使用以下身份验证方法
- 实例配置文件
- Assume Role
- IAM 用户
在上述三种身份验证方法中,实例配置文件使用最广泛。
有关更多信息,请参见 AWS IAM 中身份验证的准备工作。
HDFS
如果您选择 HDFS 作为存储,请按如下方式配置您的 StarRocks 集群
-
(可选)设置用于访问您的 HDFS 集群和 Hive Metastore 的用户名。 默认情况下,StarRocks 使用 FE 和 BE 或 CN 进程的用户名来访问您的 HDFS 集群和 Hive Metastore。 您也可以通过在每个 FE 的 fe/conf/hadoop_env.sh 文件开头和每个 BE 的 be/conf/hadoop_env.sh 文件或每个 CN 的 cn/conf/hadoop_env.sh 文件开头添加
export HADOOP_USER_NAME="<user_name>"来设置用户名。 在这些文件中设置用户名后,重启每个 FE 和每个 BE 或 CN 以使参数设置生效。 您只能为每个 StarRocks 集群设置一个用户名。 -
当您查询 Hudi 数据时,StarRocks 集群的 FE 和 BE 或 CN 会使用 HDFS 客户端访问您的 HDFS 集群。 在大多数情况下,您无需配置 StarRocks 集群即可实现此目的,StarRocks 会使用默认配置启动 HDFS 客户端。 您仅在以下情况下需要配置 StarRocks 集群:
- 为您的 HDFS 集群启用了高可用性 (HA):将您的 HDFS 集群的 hdfs-site.xml 文件添加到每个 FE 的 $FE_HOME/conf 路径和每个 BE 的 $BE_HOME/conf 路径或每个 CN 的 $CN_HOME/conf 路径。
- 为您的 HDFS 集群启用了 View File System (ViewFs):将您的 HDFS 集群的 core-site.xml 文件添加到每个 FE 的 $FE_HOME/conf 路径和每个 BE 的 $BE_HOME/conf 路径或每个 CN 的 $CN_HOME/conf 路径。
注意
如果在发送查询时返回指示未知主机的错误,则必须将您的 HDFS 集群节点的 hostname 和 IP 地址之间的映射添加到 /etc/hosts 路径。
Kerberos 身份验证
如果您的 HDFS 集群或 Hive Metastore 启用了 Kerberos 身份验证,请按如下方式配置您的 StarRocks 集群
- 在每个 FE 和每个 BE 或 CN 上运行
kinit -kt keytab_path principal命令,以从 Key Distribution Center (KDC) 获取 Ticket Granting Ticket (TGT)。 要运行此命令,您必须具有访问您的 HDFS 集群和 Hive Metastore 的权限。 请注意,使用此命令访问 KDC 对时间敏感。 因此,您需要使用 cron 定期运行此命令。 - 将
JAVA_OPTS="-Djava.security.krb5.conf=/etc/krb5.conf"添加到每个 FE 的 $FE_HOME/conf/fe.conf 文件和每个 BE 的 $BE_HOME/conf/be.conf 文件或每个 CN 的 $CN_HOME/conf/cn.conf 文件。 在此示例中,/etc/krb5.conf是 krb5.conf 文件的保存路径。 您可以根据需要修改路径。
创建 Hudi catalog
语法
CREATE EXTERNAL CATALOG <catalog_name>
[COMMENT <comment>]
PROPERTIES
(
"type" = "hudi",
MetastoreParams,
StorageCredentialParams,
MetadataUpdateParams
)
参数
catalog_name
Hudi catalog 的名称。 命名约定如下:
- 该名称可以包含字母、数字 (0-9) 和下划线 (_)。它必须以字母开头。
- 该名称区分大小写,长度不能超过 1023 个字符。
comment
Hudi catalog 的描述。 此参数是可选的。
type
您的数据源的类型。 将该值设置为 hudi。
MetastoreParams
一组关于 StarRocks 如何与数据源的 Metastore 集成的参数。
Hive Metastore
如果您选择 Hive Metastore 作为数据源的 Metastore,请按如下方式配置 MetastoreParams
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "<hive_metastore_uri>"
注意
在查询 Hudi 数据之前,您必须将 Hive Metastore 节点的hostname与IP地址的映射添加到
/etc/hosts路径。 否则,当您启动查询时,StarRocks 可能无法访问您的 Hive Metastore。
下表描述了您需要在 MetastoreParams 中配置的参数。
| 参数 | 必需 | 描述 |
|---|---|---|
| hive.metastore.type | 是 | 您为 Hudi 集群使用的 Metastore 类型。 将该值设置为 hive。 |
| hive.metastore.uris | 是 | 您的 Hive Metastore 的 URI。格式:thrift://<metastore_IP_address>:<metastore_port>。如果为您的 Hive Metastore 启用了高可用性 (HA),您可以指定多个 Metastore URI,并用逗号 ( ,) 分隔它们,例如,"thrift://<metastore_IP_address_1>:<metastore_port_1>,thrift://<metastore_IP_address_2>:<metastore_port_2>,thrift://<metastore_IP_address_3>:<metastore_port_3>"。 |
AWS Glue
如果您选择 AWS Glue 作为数据源的 Metastore,这仅在您选择 AWS S3 作为存储时才支持,请执行以下操作之一
-
要选择基于实例配置文件的身份验证方法,请按如下方式配置
MetastoreParams"hive.metastore.type" = "glue",
"aws.glue.use_instance_profile" = "true",
"aws.glue.region" = "<aws_glue_region>" -
要选择基于 Assume Role 的身份验证方法,请按如下方式配置
MetastoreParams"hive.metastore.type" = "glue",
"aws.glue.use_instance_profile" = "true",
"aws.glue.iam_role_arn" = "<iam_role_arn>",
"aws.glue.region" = "<aws_glue_region>" -
要选择基于 IAM 用户的身份验证方法,请按如下方式配置
MetastoreParams"hive.metastore.type" = "glue",
"aws.glue.use_instance_profile" = "false",
"aws.glue.access_key" = "<iam_user_access_key>",
"aws.glue.secret_key" = "<iam_user_secret_key>",
"aws.glue.region" = "<aws_s3_region>"
下表描述了您需要在 MetastoreParams 中配置的参数。
| 参数 | 必需 | 描述 |
|---|---|---|
| hive.metastore.type | 是 | 您为 Hudi 集群使用的 Metastore 类型。 将该值设置为 glue。 |
| aws.glue.use_instance_profile | 是 | 指定是否启用基于实例配置文件的身份验证方法和基于 Assume Role 的身份验证方法。有效值:true 和 false。默认值:false。 |
| aws.glue.iam_role_arn | 否 | 具有对您的 AWS Glue Data Catalog 权限的 IAM 角色的 ARN。如果您使用基于 Assume Role 的身份验证方法访问 AWS Glue,则必须指定此参数。 |
| aws.glue.region | 是 | 您的 AWS Glue Data Catalog 所在的区域。示例:us-west-1。 |
| aws.glue.access_key | 否 | 您的 AWS IAM 用户的访问密钥。如果您使用基于 IAM 用户的身份验证方法访问 AWS Glue,则必须指定此参数。 |
| aws.glue.secret_key | 否 | 您的 AWS IAM 用户的密钥。如果您使用基于 IAM 用户的身份验证方法访问 AWS Glue,则必须指定此参数。 |
有关如何选择访问 AWS Glue 的身份验证方法以及如何在 AWS IAM 控制台中配置访问控制策略的信息,请参见访问 AWS Glue 的身份验证参数。
StorageCredentialParams
一组关于 StarRocks 如何与您的存储系统集成的参数。此参数集是可选的。
如果您使用 HDFS 作为存储,则无需配置 StorageCredentialParams。
如果您使用 AWS S3、其他 S3 兼容的存储系统、Microsoft Azure Storage 或 Google GCS 作为存储,则必须配置 StorageCredentialParams。
AWS S3
如果您选择 AWS S3 作为 Hudi 集群的存储,请执行以下操作之一:
-
要选择基于实例配置文件的身份验证方法,请按如下方式配置
StorageCredentialParams"aws.s3.use_instance_profile" = "true",
"aws.s3.region" = "<aws_s3_region>" -
要选择基于假设角色的身份验证方法,请按如下方式配置
StorageCredentialParams"aws.s3.use_instance_profile" = "true",
"aws.s3.iam_role_arn" = "<iam_role_arn>",
"aws.s3.region" = "<aws_s3_region>" -
要选择基于 IAM 用户的身份验证方法,请按如下方式配置
StorageCredentialParams"aws.s3.use_instance_profile" = "false",
"aws.s3.access_key" = "<iam_user_access_key>",
"aws.s3.secret_key" = "<iam_user_secret_key>",
"aws.s3.region" = "<aws_s3_region>"
下表描述了需要在 StorageCredentialParams 中配置的参数。
| 参数 | 必需 | 描述 |
|---|---|---|
| aws.s3.use_instance_profile | 是 | 指定是否启用基于实例配置文件的身份验证方法和基于 Assume Role 的身份验证方法。有效值:true 和 false。默认值:false。 |
| aws.s3.iam_role_arn | 否 | 具有对您的 AWS S3 存储桶权限的 IAM 角色的 ARN。如果您使用基于 Assume Role 的身份验证方法访问 AWS S3,则必须指定此参数。 |
| aws.s3.region | 是 | 您的 AWS S3 bucket 所在的区域。示例:us-west-1。 |
| aws.s3.access_key | 否 | 您的 IAM 用户的访问密钥。如果您使用基于 IAM 用户的身份验证方法访问 AWS S3,则必须指定此参数。 |
| aws.s3.secret_key | 否 | 您的 IAM 用户的密钥。如果您使用基于 IAM 用户的身份验证方法访问 AWS S3,则必须指定此参数。 |
有关如何选择访问 AWS S3 的身份验证方法以及如何在 AWS IAM 控制台中配置访问控制策略的信息,请参见访问 AWS S3 的身份验证参数。
S3 兼容的存储系统
Hudi catalog 从 v2.5 版本开始支持与 S3 兼容的存储系统。
如果您选择与 S3 兼容的存储系统(例如 MinIO)作为 Hudi 集群的存储,请如下配置 StorageCredentialParams 以确保成功集成:
"aws.s3.enable_ssl" = "false",
"aws.s3.enable_path_style_access" = "true",
"aws.s3.endpoint" = "<s3_endpoint>",
"aws.s3.access_key" = "<iam_user_access_key>",
"aws.s3.secret_key" = "<iam_user_secret_key>"
下表描述了需要在 StorageCredentialParams 中配置的参数。
| 参数 | 必需 | 描述 |
|---|---|---|
| aws.s3.enable_ssl | 是 | 指定是否启用 SSL 连接。 有效值: true 和 false。默认值:true。 |
| aws.s3.enable_path_style_access | 是 | 指定是否启用 path-style 访问。 有效值: true 和 false。默认值:false。对于 MinIO,您必须将值设置为 true。Path-style URL 使用以下格式: https://s3.<region_code>.amazonaws.com/<bucket_name>/<key_name>。 例如,如果您在美国西部(俄勒冈)区域中创建了一个名为 DOC-EXAMPLE-BUCKET1 的存储桶,并且想要访问该存储桶中的 alice.jpg 对象,则可以使用以下 path-style URL:https://s3.us-west-2.amazonaws.com/DOC-EXAMPLE-BUCKET1/alice.jpg。 |
| aws.s3.endpoint | 是 | 用于连接到您的 S3 兼容存储系统而不是 AWS S3 的端点。 |
| aws.s3.access_key | 是 | 您的 IAM 用户的访问密钥。 |
| aws.s3.secret_key | 是 | 您的 IAM 用户的密钥。 |
Microsoft Azure Storage
Hudi catalog 从 v3.0 版本开始支持 Microsoft Azure Storage。
Azure Blob Storage
如果您选择 Blob Storage 作为 Hudi 集群的存储,请执行以下操作之一:
-
要选择共享密钥身份验证方法,请按如下方式配置
StorageCredentialParams"azure.blob.storage_account" = "<storage_account_name>",
"azure.blob.shared_key" = "<storage_account_shared_key>"下表描述了需要在
StorageCredentialParams中配置的参数。参数 必需 描述 azure.blob.storage_account 是 您的 Blob Storage 帐户的用户名。 azure.blob.shared_key 是 您的 Blob Storage 帐户的共享密钥。 -
要选择 SAS 令牌身份验证方法,请按如下方式配置
StorageCredentialParams"azure.blob.storage_account" = "<storage_account_name>",
"azure.blob.container" = "<container_name>",
"azure.blob.sas_token" = "<storage_account_SAS_token>"下表描述了需要在
StorageCredentialParams中配置的参数。参数 必需 描述 azure.blob.storage_account 是 您的 Blob Storage 帐户的用户名。 azure.blob.container 是 存储数据的 Blob 容器的名称。 azure.blob.sas_token 是 用于访问 Blob 存储帐户的 SAS 令牌。
Azure Data Lake Storage Gen2
如果您选择 Data Lake Storage Gen2 作为 Hudi 集群的存储,请执行以下操作之一:
-
要选择托管标识身份验证方法,请按如下方式配置
StorageCredentialParams"azure.adls2.oauth2_use_managed_identity" = "true",
"azure.adls2.oauth2_tenant_id" = "<service_principal_tenant_id>",
"azure.adls2.oauth2_client_id" = "<service_client_id>"下表描述了需要在
StorageCredentialParams中配置的参数。参数 必需 描述 azure.adls2.oauth2_use_managed_identity 是 指定是否启用托管标识身份验证方法。将值设置为 true。azure.adls2.oauth2_tenant_id 是 您要访问其数据的租户的 ID。 azure.adls2.oauth2_client_id 是 托管标识的客户端(应用程序)ID。 -
要选择共享密钥身份验证方法,请按如下方式配置
StorageCredentialParams"azure.adls2.storage_account" = "<storage_account_name>",
"azure.adls2.shared_key" = "<storage_account_shared_key>"下表描述了需要在
StorageCredentialParams中配置的参数。参数 必需 描述 azure.adls2.storage_account 是 您的 Data Lake Storage Gen2 存储帐户的用户名。 azure.adls2.shared_key 是 您的 Data Lake Storage Gen2 存储帐户的共享密钥。 -
要选择服务主体身份验证方法,请按如下方式配置
StorageCredentialParams"azure.adls2.oauth2_client_id" = "<service_client_id>",
"azure.adls2.oauth2_client_secret" = "<service_principal_client_secret>",
"azure.adls2.oauth2_client_endpoint" = "<service_principal_client_endpoint>"下表描述了您需要在
StorageCredentialParams中配置的参数。参数 必需 描述 azure.adls2.oauth2_client_id 是 服务主体的客户端(应用程序)ID。 azure.adls2.oauth2_client_secret 是 创建的新客户端(应用程序)密钥的值。 azure.adls2.oauth2_client_endpoint 是 服务主体或应用程序的 OAuth 2.0 令牌端点 (v1)。
Azure Data Lake Storage Gen1
如果您选择 Data Lake Storage Gen1 作为 Hudi 集群的存储,请执行以下操作之一:
-
要选择托管服务标识身份验证方法,请按如下方式配置
StorageCredentialParams"azure.adls1.use_managed_service_identity" = "true"下表描述了需要在
StorageCredentialParams中配置的参数。参数 必需 描述 azure.adls1.use_managed_service_identity 是 指定是否启用托管服务标识身份验证方法。将值设置为 true。 -
要选择服务主体身份验证方法,请按如下方式配置
StorageCredentialParams"azure.adls1.oauth2_client_id" = "<application_client_id>",
"azure.adls1.oauth2_credential" = "<application_client_credential>",
"azure.adls1.oauth2_endpoint" = "<OAuth_2.0_authorization_endpoint_v2>"下表描述了需要在
StorageCredentialParams中配置的参数。参数 必需 描述 azure.adls1.oauth2_client_id 是 服务主体的客户端(应用程序)ID。 azure.adls1.oauth2_credential 是 创建的新客户端(应用程序)密钥的值。 azure.adls1.oauth2_endpoint 是 服务主体或应用程序的 OAuth 2.0 令牌端点 (v1)。
Google GCS
Hudi catalog 从 v3.0 版本开始支持 Google GCS。
如果您选择 Google GCS 作为 Hudi 集群的存储,请执行以下操作之一:
-
要选择基于 VM 的身份验证方法,请按如下方式配置
StorageCredentialParams"gcp.gcs.use_compute_engine_service_account" = "true"下表描述了需要在
StorageCredentialParams中配置的参数。参数 默认值 值 示例 描述 gcp.gcs.use_compute_engine_service_account false true 指定是否直接使用绑定到您的 Compute Engine 的服务帐户。 -
要选择基于服务帐户的身份验证方法,请按如下方式配置
StorageCredentialParams"gcp.gcs.service_account_email" = "<google_service_account_email>",
"gcp.gcs.service_account_private_key_id" = "<google_service_private_key_id>",
"gcp.gcs.service_account_private_key" = "<google_service_private_key>"下表描述了需要在
StorageCredentialParams中配置的参数。参数 默认值 值 示例 描述 gcp.gcs.service_account_email "" "user@hello.iam.gserviceaccount.com" 在创建服务帐户时生成的 JSON 文件中的电子邮件地址。 gcp.gcs.service_account_private_key_id "" "61d257bd8479547cb3e04f0b9b6b9ca07af3b7ea" 在创建服务帐户时生成的 JSON 文件中的私钥 ID。 gcp.gcs.service_account_private_key "" "-----BEGIN PRIVATE KEY----xxxx-----END PRIVATE KEY-----\n" 在创建服务帐户时生成的 JSON 文件中的私钥。 -
要选择基于模拟的身份验证方法,请按如下方式配置
StorageCredentialParams-
使 VM 实例模拟服务帐户
"gcp.gcs.use_compute_engine_service_account" = "true",
"gcp.gcs.impersonation_service_account" = "<assumed_google_service_account_email>"下表描述了需要在
StorageCredentialParams中配置的参数。参数 默认值 值 示例 描述 gcp.gcs.use_compute_engine_service_account false true 指定是否直接使用绑定到您的 Compute Engine 的服务帐户。 gcp.gcs.impersonation_service_account "" "hello" 您要模拟的服务帐户。 -
使服务帐户(暂时命名为 meta service account)模拟另一个服务帐户(暂时命名为 data service account)
"gcp.gcs.service_account_email" = "<google_service_account_email>",
"gcp.gcs.service_account_private_key_id" = "<meta_google_service_account_email>",
"gcp.gcs.service_account_private_key" = "<meta_google_service_account_email>",
"gcp.gcs.impersonation_service_account" = "<data_google_service_account_email>"下表描述了需要在
StorageCredentialParams中配置的参数。参数 默认值 值 示例 描述 gcp.gcs.service_account_email "" "user@hello.iam.gserviceaccount.com" 在创建元服务帐户时生成的 JSON 文件中的电子邮件地址。 gcp.gcs.service_account_private_key_id "" "61d257bd8479547cb3e04f0b9b6b9ca07af3b7ea" 在创建元服务帐户时生成的 JSON 文件中的私钥 ID。 gcp.gcs.service_account_private_key "" "-----BEGIN PRIVATE KEY----xxxx-----END PRIVATE KEY-----\n" 在创建元服务帐户时生成的 JSON 文件中的私钥。 gcp.gcs.impersonation_service_account "" "hello" 您要模拟的数据服务帐户。
-
MetadataUpdateParams
一组关于 StarRocks 如何更新 Hudi 缓存元数据的参数。 此参数集是可选的。
StarRocks 默认实现元数据自动异步更新策略。
在大多数情况下,您可以忽略 MetadataUpdateParams,并且无需调整其中的策略参数,因为这些参数的默认值已经为您提供了开箱即用的性能。
但是,如果 Hudi 中的数据更新频率很高,您可以调整这些参数以进一步优化自动异步更新的性能。
注意
在大多数情况下,如果您的 Hudi 数据以 1 小时或更小的粒度更新,则数据更新频率被认为是高的。
| 参数 | 必需 | 描述 |
|---|---|---|
| enable_metastore_cache | 否 | 指定 StarRocks 是否缓存 Hudi 表的元数据。 有效值:true 和 false。 默认值:true。 值 true 启用缓存,值 false 禁用缓存。 |
| enable_remote_file_cache | 否 | 指定 StarRocks 是否缓存 Hudi 表或分区的基础数据文件的元数据。 有效值:true 和 false。 默认值:true。 值 true 启用缓存,值 false 禁用缓存。 |
| metastore_cache_refresh_interval_sec | 否 | StarRocks 异步更新自身缓存的 Hudi 表或分区的元数据的时间间隔。 单位:秒。 默认值:7200,即 2 小时。 |
| remote_file_cache_refresh_interval_sec | 否 | StarRocks 异步更新自身缓存的 Hudi 表或分区的基础数据文件的元数据的时间间隔。 单位:秒。 默认值:60。 |
| metastore_cache_ttl_sec | 否 | StarRocks 自动丢弃自身缓存的 Hudi 表或分区的元数据的时间间隔。 单位:秒。 默认值:86400,即 24 小时。 |
| remote_file_cache_ttl_sec | 否 | StarRocks 自动丢弃自身缓存的 Hudi 表或分区的基础数据文件的元数据的时间间隔。 单位:秒。 默认值:129600,即 36 小时。 |
示例
以下示例根据您使用的 Metastore 类型,创建一个名为 hudi_catalog_hms 或 hudi_catalog_glue 的 Hudi catalog,以查询 Hudi 集群中的数据。
HDFS
如果您使用 HDFS 作为存储,请运行如下命令
CREATE EXTERNAL CATALOG hudi_catalog_hms
PROPERTIES
(
"type" = "hudi",
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083"
);
AWS S3
如果您选择基于实例配置文件的凭据
-
如果您在 Hudi 集群中使用 Hive Metastore,请运行如下命令:
CREATE EXTERNAL CATALOG hudi_catalog_hms
PROPERTIES
(
"type" = "hudi",
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"aws.s3.use_instance_profile" = "true",
"aws.s3.region" = "us-west-2"
); -
如果您在 Amazon EMR Hudi 集群中使用 AWS Glue,请运行如下命令:
CREATE EXTERNAL CATALOG hudi_catalog_glue
PROPERTIES
(
"type" = "hudi",
"hive.metastore.type" = "glue",
"aws.glue.use_instance_profile" = "true",
"aws.glue.region" = "us-west-2",
"aws.s3.use_instance_profile" = "true",
"aws.s3.region" = "us-west-2"
);
如果您选择基于代入角色的凭据
-
如果您在 Hudi 集群中使用 Hive Metastore,请运行如下命令:
CREATE EXTERNAL CATALOG hudi_catalog_hms
PROPERTIES
(
"type" = "hudi",
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"aws.s3.use_instance_profile" = "true",
"aws.s3.iam_role_arn" = "arn:aws:iam::081976408565:role/test_s3_role",
"aws.s3.region" = "us-west-2"
); -
如果您在 Amazon EMR Hudi 集群中使用 AWS Glue,请运行如下命令:
CREATE EXTERNAL CATALOG hudi_catalog_glue
PROPERTIES
(
"type" = "hudi",
"hive.metastore.type" = "glue",
"aws.glue.use_instance_profile" = "true",
"aws.glue.iam_role_arn" = "arn:aws:iam::081976408565:role/test_glue_role",
"aws.glue.region" = "us-west-2",
"aws.s3.use_instance_profile" = "true",
"aws.s3.iam_role_arn" = "arn:aws:iam::081976408565:role/test_s3_role",
"aws.s3.region" = "us-west-2"
);
如果选择基于 IAM 用户的凭据
-
如果您在 Hudi 集群中使用 Hive Metastore,请运行如下命令:
CREATE EXTERNAL CATALOG hudi_catalog_hms
PROPERTIES
(
"type" = "hudi",
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"aws.s3.use_instance_profile" = "false",
"aws.s3.access_key" = "<iam_user_access_key>",
"aws.s3.secret_key" = "<iam_user_access_key>",
"aws.s3.region" = "us-west-2"
); -
如果您在 Amazon EMR Hudi 集群中使用 AWS Glue,请运行如下命令:
CREATE EXTERNAL CATALOG hudi_catalog_glue
PROPERTIES
(
"type" = "hudi",
"hive.metastore.type" = "glue",
"aws.glue.use_instance_profile" = "false",
"aws.glue.access_key" = "<iam_user_access_key>",
"aws.glue.secret_key" = "<iam_user_secret_key>",
"aws.glue.region" = "us-west-2",
"aws.s3.use_instance_profile" = "false",
"aws.s3.access_key" = "<iam_user_access_key>",
"aws.s3.secret_key" = "<iam_user_secret_key>",
"aws.s3.region" = "us-west-2"
);
S3 兼容的存储系统
以 MinIO 为例。运行如下命令
CREATE EXTERNAL CATALOG hudi_catalog_hms
PROPERTIES
(
"type" = "hudi",
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"aws.s3.enable_ssl" = "true",
"aws.s3.enable_path_style_access" = "true",
"aws.s3.endpoint" = "<s3_endpoint>",
"aws.s3.access_key" = "<iam_user_access_key>",
"aws.s3.secret_key" = "<iam_user_secret_key>"
);
Microsoft Azure Storage
Azure Blob Storage
-
如果您选择 Shared Key 身份验证方法,请运行如下命令
CREATE EXTERNAL CATALOG hudi_catalog_hms
PROPERTIES
(
"type" = "hudi",
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"azure.blob.storage_account" = "<blob_storage_account_name>",
"azure.blob.shared_key" = "<blob_storage_account_shared_key>"
); -
如果您选择 SAS Token 身份验证方法,请运行如下命令
CREATE EXTERNAL CATALOG hudi_catalog_hms
PROPERTIES
(
"type" = "hudi",
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"azure.blob.storage_account" = "<blob_storage_account_name>",
"azure.blob.container" = "<blob_container_name>",
"azure.blob.sas_token" = "<blob_storage_account_SAS_token>"
);
Azure Data Lake Storage Gen1
-
如果您选择 Managed Service Identity 身份验证方法,请运行如下命令
CREATE EXTERNAL CATALOG hudi_catalog_hms
PROPERTIES
(
"type" = "hudi",
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"azure.adls1.use_managed_service_identity" = "true"
); -
如果您选择 Service Principal 身份验证方法,请运行如下命令
CREATE EXTERNAL CATALOG hudi_catalog_hms
PROPERTIES
(
"type" = "hudi",
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"azure.adls1.oauth2_client_id" = "<application_client_id>",
"azure.adls1.oauth2_credential" = "<application_client_credential>",
"azure.adls1.oauth2_endpoint" = "<OAuth_2.0_authorization_endpoint_v2>"
);
Azure Data Lake Storage Gen2
-
如果您选择 Managed Identity 身份验证方法,请运行如下命令
CREATE EXTERNAL CATALOG hudi_catalog_hms
PROPERTIES
(
"type" = "hudi",
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"azure.adls2.oauth2_use_managed_identity" = "true",
"azure.adls2.oauth2_tenant_id" = "<service_principal_tenant_id>",
"azure.adls2.oauth2_client_id" = "<service_client_id>"
); -
如果您选择 Shared Key 身份验证方法,请运行如下命令
CREATE EXTERNAL CATALOG hudi_catalog_hms
PROPERTIES
(
"type" = "hudi",
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"azure.adls2.storage_account" = "<storage_account_name>",
"azure.adls2.shared_key" = "<shared_key>"
); -
如果您选择 Service Principal 身份验证方法,请运行如下命令
CREATE EXTERNAL CATALOG hudi_catalog_hms
PROPERTIES
(
"type" = "hudi",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"azure.adls2.oauth2_client_id" = "<service_client_id>",
"azure.adls2.oauth2_client_secret" = "<service_principal_client_secret>",
"azure.adls2.oauth2_client_endpoint" = "<service_principal_client_endpoint>"
);
Google GCS
-
如果您选择基于 VM 的身份验证方法,请运行如下命令
CREATE EXTERNAL CATALOG hudi_catalog_hms
PROPERTIES
(
"type" = "hudi",
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"gcp.gcs.use_compute_engine_service_account" = "true"
); -
如果您选择基于服务帐户的身份验证方法,请运行如下命令
CREATE EXTERNAL CATALOG hudi_catalog_hms
PROPERTIES
(
"type" = "hudi",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"gcp.gcs.service_account_email" = "<google_service_account_email>",
"gcp.gcs.service_account_private_key_id" = "<google_service_private_key_id>",
"gcp.gcs.service_account_private_key" = "<google_service_private_key>"
); -
如果您选择基于 Impersonation 的身份验证方法
-
如果您使 VM 实例模拟服务帐户,请运行如下命令
CREATE EXTERNAL CATALOG hudi_catalog_hms
PROPERTIES
(
"type" = "hudi",
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"gcp.gcs.use_compute_engine_service_account" = "true",
"gcp.gcs.impersonation_service_account" = "<assumed_google_service_account_email>"
); -
如果您使服务帐户模拟另一个服务帐户,请运行如下命令
CREATE EXTERNAL CATALOG hudi_catalog_hms
PROPERTIES
(
"type" = "hudi",
"hive.metastore.type" = "hive",
"hive.metastore.uris" = "thrift://xx.xx.xx.xx:9083",
"gcp.gcs.service_account_email" = "<google_service_account_email>",
"gcp.gcs.service_account_private_key_id" = "<meta_google_service_account_email>",
"gcp.gcs.service_account_private_key" = "<meta_google_service_account_email>",
"gcp.gcs.impersonation_service_account" = "<data_google_service_account_email>"
);
-
查看 Hudi catalog
您可以使用 SHOW CATALOGS 查询当前 StarRocks 集群中的所有 Catalog
SHOW CATALOGS;
您还可以使用 SHOW CREATE CATALOG 查询外部 catalog 的创建语句。 以下示例查询名为 hudi_catalog_glue 的 Hudi catalog 的创建语句:
SHOW CREATE CATALOG hudi_catalog_glue;
切换到 Hudi Catalog 及其中的数据库
您可以使用以下方法之一切换到 Hudi catalog 及其中的数据库:
-
使用 SET CATALOG 在当前会话中指定 Hudi catalog,然后使用 USE 指定活动数据库:
-- Switch to a specified catalog in the current session:
SET CATALOG <catalog_name>
-- Specify the active database in the current session:
USE <db_name> -
直接使用 USE 切换到 Hudi catalog 及其中的数据库:
USE <catalog_name>.<db_name>
删除 Hudi catalog
您可以使用 DROP CATALOG 删除外部 Catalog。
以下示例删除名为 hudi_catalog_glue 的 Hudi catalog:
DROP Catalog hudi_catalog_glue;
查看 Hudi 表的 schema
您可以使用以下语法之一来查看 Hudi 表的 schema:
-
查看 Schema
DESC[RIBE] <catalog_name>.<database_name>.<table_name> -
从 CREATE 语句中查看 Schema 和 Location
SHOW CREATE TABLE <catalog_name>.<database_name>.<table_name>
查询 Hudi 表
-
使用 SHOW DATABASES 查看 Hudi 集群中的数据库:
SHOW DATABASES FROM <catalog_name> -
使用 SELECT 查询指定数据库中的目标表
SELECT count(*) FROM <table_name> LIMIT 10
从 Hudi 加载数据
假设您有一个名为 olap_tbl 的 OLAP 表,您可以转换和加载数据,如下所示
INSERT INTO default_catalog.olap_db.olap_tbl SELECT * FROM hudi_table
手动或自动更新元数据缓存
手动更新
默认情况下,StarRocks 会缓存 Hudi 的元数据,并以异步模式自动更新元数据,以提供更好的性能。 此外,在对 Hudi 表进行一些 schema 更改或表更新后,您还可以使用 REFRESH EXTERNAL TABLE 手动更新其元数据,从而确保 StarRocks 尽早获取最新的元数据并生成适当的执行计划。
REFRESH EXTERNAL TABLE <table_name> [PARTITION ('partition_name', ...)]
附录:了解元数据自动异步更新
自动异步更新是 StarRocks 用于更新 Hudi catalog 中元数据的默认策略。
默认情况下(即,当 enable_metastore_cache 和 enable_remote_file_cache 参数都设置为 true 时),如果查询命中 Hudi 表的分区,StarRocks 会自动缓存该分区的元数据和该分区的基础数据文件的元数据。 缓存的元数据通过使用延迟更新策略进行更新。
例如,有一个名为 table2 的 Hudi 表,它有四个分区:p1、p2、p3 和 p4。 查询命中 p1,StarRocks 缓存 p1 的元数据和 p1 的基础数据文件的元数据。 假设更新和丢弃缓存元数据的默认时间间隔如下:
- 异步更新
p1缓存元数据的时间间隔(由metastore_cache_refresh_interval_sec参数指定)为 2 小时。 - 异步更新
p1基础数据文件的缓存元数据的时间间隔(由remote_file_cache_refresh_interval_sec参数指定)为 60 秒。 - 自动丢弃
p1缓存元数据的时间间隔(由metastore_cache_ttl_sec参数指定)为 24 小时。 - 自动丢弃
p1基础数据文件的缓存元数据的时间间隔(由remote_file_cache_ttl_sec参数指定)为 36 小时。
下图显示了时间轴上的时间间隔,以便于理解。
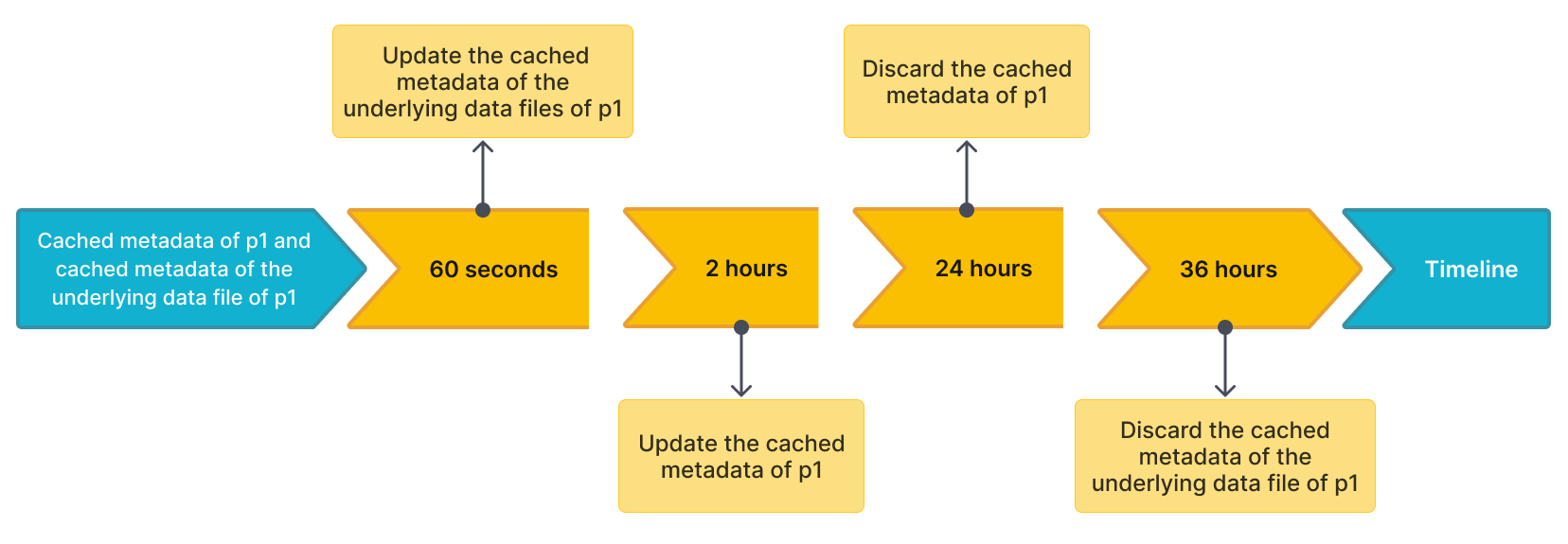
然后,StarRocks 根据以下规则更新或丢弃元数据:
- 如果另一个查询再次命中
p1,并且自上次更新以来的当前时间小于 60 秒,则 StarRocks 不会更新p1的缓存元数据或p1的基础数据文件的缓存元数据。 - 如果另一个查询再次命中
p1,并且自上次更新以来的当前时间大于 60 秒,则 StarRocks 会更新p1的基础数据文件的缓存元数据。 - 如果另一个查询再次命中
p1,并且自上次更新以来的当前时间大于 2 小时,则 StarRocks 会更新p1的缓存元数据。 - 如果自上次更新以来 24 小时内未访问
p1,则 StarRocks 会丢弃p1的缓存元数据。 元数据将在下次查询时缓存。 - 如果自上次更新以来 36 小时内未访问
p1,则 StarRocks 会丢弃p1的基础数据文件的缓存元数据。 元数据将在下次查询时缓存。