查询 Profile 指标
由 StarRocks 查询 Profile 发出的原始指标的权威参考,按算子分组。
将其用作词汇表;要获取故障排除指导,请跳转到 query_profile_tuning_recipes.md。
总结指标
关于查询执行的基本信息
| 指标 | 描述 |
|---|---|
| 总计 | 查询消耗的总时间,包括规划、执行和 Profile 阶段的持续时间。 |
| 查询状态 | 查询状态,可能的状态包括已完成、错误和正在运行。 |
| 查询 ID | 查询的唯一标识符。 |
| 开始时间 | 查询开始的时间戳。 |
| 结束时间 | 查询结束的时间戳。 |
| 总计 | 查询的总持续时间。 |
| 查询类型 | 查询的类型。 |
| 查询状态 | 查询的当前状态。 |
| StarRocks 版本 | 使用的 StarRocks 版本。 |
| 用户 | 执行查询的用户。 |
| 默认数据库 | 查询使用的默认数据库。 |
| Sql 语句 | 执行的 SQL 语句。 |
| 变量 | 查询使用的重要变量。 |
| NonDefaultSessionVariables | 查询使用的非默认会话变量。 |
| 收集 Profile 时间 | 收集 Profile 所花费的时间。 |
| IsProfileAsync | 指示 Profile 收集是否为异步。 |
规划器指标
它提供了规划器的全面概述。通常,如果规划器花费的总时间少于 10 毫秒,则无需担心。
在某些情况下,规划器可能需要更多时间
- 复杂的查询可能需要更多的时间来解析和优化,以确保最佳的执行计划。
- 大量物化视图的存在会增加查询重写所需的时间。
- 当多个并发查询耗尽系统资源并利用查询队列时,
Pending时间可能会延长。 - 涉及外部表的查询可能会产生与外部元数据服务器通信的额外时间。
示例
- -- Parser[1] 0
- -- Total[1] 3ms
- -- Analyzer[1] 0
- -- Lock[1] 0
- -- AnalyzeDatabase[1] 0
- -- AnalyzeTemporaryTable[1] 0
- -- AnalyzeTable[1] 0
- -- Transformer[1] 0
- -- Optimizer[1] 1ms
- -- MVPreprocess[1] 0
- -- MVTextRewrite[1] 0
- -- RuleBaseOptimize[1] 0
- -- CostBaseOptimize[1] 0
- -- PhysicalRewrite[1] 0
- -- DynamicRewrite[1] 0
- -- PlanValidate[1] 0
- -- InputDependenciesChecker[1] 0
- -- TypeChecker[1] 0
- -- CTEUniqueChecker[1] 0
- -- ColumnReuseChecker[1] 0
- -- ExecPlanBuild[1] 0
- -- Pending[1] 0
- -- Prepare[1] 0
- -- Deploy[1] 2ms
- -- DeployLockInternalTime[1] 2ms
- -- DeploySerializeConcurrencyTime[2] 0
- -- DeployStageByStageTime[6] 0
- -- DeployWaitTime[6] 1ms
- -- DeployAsyncSendTime[2] 0
- DeployDataSize: 10916
Reason:
执行概述指标
高级执行统计信息
| 指标 | 描述 | 经验法则 |
|---|---|---|
| FrontendProfileMergeTime | FE 端 profile 处理时间 | < 10ms 正常 |
| QueryAllocatedMemoryUsage | 跨节点的总分配内存 | |
| QueryDeallocatedMemoryUsage | 跨节点的总释放内存 | |
| QueryPeakMemoryUsagePerNode | 每个节点的最大峰值内存 | < 容量的 80% 正常 |
| QuerySumMemoryUsage | 跨节点的总峰值内存 | |
| QueryExecutionWallTime | 执行的实际时间 | |
| QueryCumulativeCpuTime | 跨节点的总 CPU 时间 | 与 walltime * totalCpuCores 比较 |
| QueryCumulativeOperatorTime | 算子的总执行时间 | 算子时间百分比的分母 |
| QueryCumulativeNetworkTime | Exchange 节点的总网络时间 | |
| QueryCumulativeScanTime | Scan 节点的总 IO 时间 | |
| QueryPeakScheduleTime | Pipeline 的最大 ScheduleTime | 对于简单查询,< 1 秒是正常的 |
| QuerySpillBytes | 溢出到磁盘的数据 | < 1GB 正常 |
Fragment 指标
Fragment 级别的执行详细信息
| 指标 | 描述 |
|---|---|
| InstanceNum | FragmentInstance 的数量 |
| InstanceIds | 所有 FragmentInstance 的 ID |
| BackendNum | 参与 BE 的数量 |
| BackendAddresses | BE 地址 |
| FragmentInstancePrepareTime | Fragment 准备阶段的持续时间 |
| InstanceAllocatedMemoryUsage | 实例的总分配内存 |
| InstanceDeallocatedMemoryUsage | 实例的总释放内存 |
| InstancePeakMemoryUsage | 跨实例的峰值内存 |
Pipeline 指标
Pipeline 执行的详细信息和关系
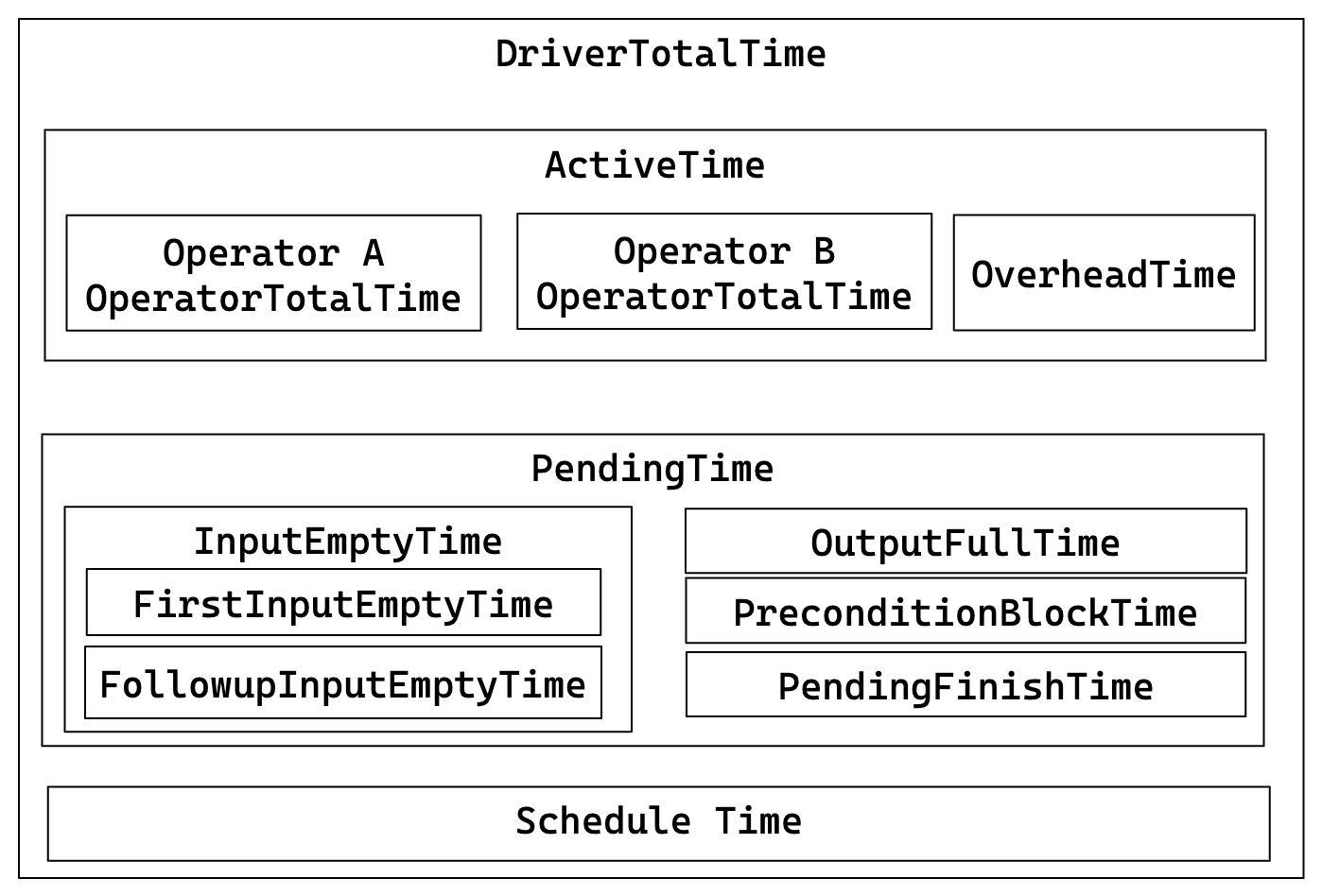
关键关系
- DriverTotalTime = ActiveTime + PendingTime + ScheduleTime
- ActiveTime = ∑ OperatorTotalTime + OverheadTime
- PendingTime = InputEmptyTime + OutputFullTime + PreconditionBlockTime + PendingFinishTime
- InputEmptyTime = FirstInputEmptyTime + FollowupInputEmptyTime
| 指标 | 描述 |
|---|---|
| DegreeOfParallelism | Pipeline 执行的并行度。 |
| TotalDegreeOfParallelism | 并行度的总和。由于同一个 Pipeline 可能会在多台机器上执行,因此该项会聚合所有值。 |
| DriverPrepareTime | 准备阶段花费的时间。此指标不包含在 DriverTotalTime 中。 |
| DriverTotalTime | Pipeline 的总执行时间,不包括在准备阶段花费的时间。 |
| ActiveTime | Pipeline 的执行时间,包括每个算子的执行时间以及整体框架开销,例如在调用 has_output、need_input 等方法上花费的时间。 |
| PendingTime | Pipeline 由于各种原因而被阻止调度的时间。 |
| InputEmptyTime | Pipeline 由于输入队列为空而被阻止的时间。 |
| FirstInputEmptyTime | Pipeline 首次由于输入队列为空而被阻止的时间。首次阻塞时间是单独计算的,因为首次阻塞主要是由 Pipeline 依赖关系引起的。 |
| FollowupInputEmptyTime | Pipeline 随后由于输入队列为空而被阻止的时间。 |
| OutputFullTime | Pipeline 由于输出队列已满而被阻止的时间。 |
| PreconditionBlockTime | Pipeline 由于未满足依赖关系而被阻止的时间。 |
| PendingFinishTime | Pipeline 被阻止等待异步任务完成的时间。 |
| ScheduleTime | Pipeline 的调度时间,从进入就绪队列到被调度执行。 |
| BlockByInputEmpty | Pipeline 由于 InputEmpty 而被阻止的次数。 |
| BlockByOutputFull | Pipeline 由于 OutputFull 而被阻止的次数。 |
| BlockByPrecondition | Pipeline 由于未满足前提条件而被阻止的次数。 |
算子指标
| 指标 | 描述 |
|---|---|
| PrepareTime | 准备阶段花费的时间。 |
| OperatorTotalTime | 算子消耗的总时间。它满足以下等式:OperatorTotalTime = PullTotalTime + PushTotalTime + SetFinishingTime + SetFinishedTime + CloseTime。它不包括准备阶段花费的时间。 |
| PullTotalTime | 算子执行 push_chunk 所花费的总时间。 |
| PushTotalTime | 算子执行 pull_chunk 所花费的总时间。 |
| SetFinishingTime | 算子执行 set_finishing 所花费的总时间。 |
| SetFinishedTime | 算子执行 set_finished 所花费的总时间。 |
| PushRowNum | 算子的累积输入行数。 |
| PullRowNum | 算子的累积输出行数。 |
| JoinRuntimeFilterEvaluate | Join 运行时过滤器被评估的次数。 |
| JoinRuntimeFilterHashTime | 计算 Join 运行时过滤器的哈希值所花费的时间。 |
| JoinRuntimeFilterInputRows | Join 运行时过滤器的输入行数。 |
| JoinRuntimeFilterOutputRows | Join 运行时过滤器的输出行数。 |
| JoinRuntimeFilterTime | 在 Join 运行时过滤器上花费的时间。 |
Scan 算子
OLAP Scan 算子
OLAP_SCAN 算子负责从 StarRocks 原生表读取数据。
| 指标 | 描述 |
|---|---|
| 表 | 表名。 |
| Rollup | 物化视图名称。如果没有命中物化视图,则等同于表名。 |
| SharedScan | 是否启用了 enable_shared_scan 会话变量。 |
| TabletCount | Tablet 的数量。 |
| MorselsCount | Morsel 的数量,这是基本的 IO 执行单元。 |
| PushdownPredicates | 下推谓词的数量。 |
| Predicates | 谓词表达式。 |
| BytesRead | 读取的数据大小。 |
| CompressedBytesRead | 从磁盘读取的压缩数据的大小。 |
| UncompressedBytesRead | 从磁盘读取的未压缩数据的大小。 |
| RowsRead | 读取的行数(经过谓词过滤后)。 |
| RawRowsRead | 读取的原始行数(在谓词过滤之前)。 |
| ReadPagesNum | 读取的页面数。 |
| CachedPagesNum | 缓存的页面数。 |
| ChunkBufferCapacity | Chunk Buffer 的容量。 |
| DefaultChunkBufferCapacity | Chunk Buffer 的默认容量。 |
| PeakChunkBufferMemoryUsage | Chunk Buffer 的峰值内存使用量。 |
| PeakChunkBufferSize | Chunk Buffer 的峰值大小。 |
| PrepareChunkSourceTime | 准备 Chunk Source 所花费的时间。 |
| ScanTime | 累积扫描时间。扫描操作在异步 I/O 线程池中完成。 |
| IOTaskExecTime | IO 任务的执行时间。 |
| IOTaskWaitTime | 从成功提交到计划执行 IO 任务的等待时间。 |
| SubmitTaskCount | 提交 IO 任务的次数。 |
| SubmitTaskTime | 提交任务所花费的时间。 |
| PeakIOTasks | IO 任务的峰值数量。 |
| PeakScanTaskQueueSize | IO 任务队列的峰值大小。 |
Connector Scan 算子
它类似于 OLAP_SCAN 算子,但用于扫描外部表,如 Iceberg/Hive/Hudi/Detal。
| 指标 | 描述 |
|---|---|
| DataSourceType | 数据源类型,可以是 HiveDataSource、ESDataSource 等。 |
| 表 | 表名。 |
| TabletCount | Tablet 的数量。 |
| MorselsCount | Morsel 的数量。 |
| Predicates | 谓词表达式。 |
| PredicatesPartition | 应用于分区的谓词表达式。 |
| SharedScan | 是否启用了 enable_shared_scan 会话变量。 |
| ChunkBufferCapacity | Chunk Buffer 的容量。 |
| DefaultChunkBufferCapacity | Chunk Buffer 的默认容量。 |
| PeakChunkBufferMemoryUsage | Chunk Buffer 的峰值内存使用量。 |
| PeakChunkBufferSize | Chunk Buffer 的峰值大小。 |
| PrepareChunkSourceTime | 准备 Chunk Source 所花费的时间。 |
| ScanTime | 累积扫描时间。扫描操作在异步 I/O 线程池中完成。 |
| IOTaskExecTime | I/O 任务的执行时间。 |
| IOTaskWaitTime | 从成功提交到计划执行 IO 任务的等待时间。 |
| SubmitTaskCount | 提交 IO 任务的次数。 |
| SubmitTaskTime | 提交任务所花费的时间。 |
| PeakIOTasks | IO 任务的峰值数量。 |
| PeakScanTaskQueueSize | IO 任务队列的峰值大小。 |
Exchange 算子
Exchange 算子负责在 BE 节点之间传输数据。可以有几种类型的 exchange 操作:GATHER/BROADCAST/SHUFFLE。
可能使 Exchange 算子成为查询瓶颈的典型场景
- Broadcast Join:这是一种适用于小表的方法。但是,在优化器选择次优查询计划的特殊情况下,它可能会导致网络带宽的显着增加。
- Shuffle Aggregation/Join:Shuffle 一个大表可能会导致网络带宽的显着增加。
Exchange Sink 算子
| 指标 | 描述 |
|---|---|
| ChannelNum | 通道数。一般来说,通道数等于接收器的数量。 |
| DestFragments | 目标 FragmentInstance ID 列表。 |
| DestID | 目标节点 ID。 |
| PartType | 数据分发模式,包括:UNPARTITIONED、RANDOM、HASH_PARTITIONED 和 BUCKET_SHUFFLE_HASH_PARTITIONED。 |
| SerializeChunkTime | 序列化 Chunk 所花费的时间。 |
| SerializedBytes | 序列化数据的大小。 |
| ShuffleChunkAppendCounter | 当 PartType 为 HASH_PARTITIONED 或 BUCKET_SHUFFLE_HASH_PARTITIONED 时,Chunk Append 操作的数量。 |
| ShuffleChunkAppendTime | 当 PartType 为 HASH_PARTITIONED 或 BUCKET_SHUFFLE_HASH_PARTITIONED 时,Chunk Append 操作所花费的时间。 |
| ShuffleHashTime | 当 PartType 为 HASH_PARTITIONED 或 BUCKET_SHUFFLE_HASH_PARTITIONED 时,计算哈希值所花费的时间。 |
| RequestSent | 已发送的数据包数量。 |
| RequestUnsent | 未发送的数据包数量。当存在短路逻辑时,此指标为非零;否则,它为零。 |
| BytesSent | 已发送数据的大小。 |
| BytesUnsent | 未发送数据的大小。当存在短路逻辑时,此指标为非零;否则,它为零。 |
| BytesPassThrough | 如果目标节点是当前节点,则数据将不会通过网络传输,这称为直通数据。此指标表示此类直通数据的大小。直通由 enable_exchange_pass_through 控制。 |
| PassThroughBufferPeakMemoryUsage | PassThrough Buffer 的峰值内存使用量。 |
| CompressTime | 压缩时间。 |
| CompressedBytes | 压缩数据的大小。 |
| OverallThroughput | 吞吐率。 |
| NetworkTime | 数据包传输所花费的时间(不包括接收后处理时间)。 |
| NetworkBandwidth | 估计的网络带宽。 |
| WaitTime | 由于发送方队列已满而导致的等待时间。 |
| OverallTime | 整个传输过程的总时间,即从发送第一个数据包到确认正确接收最后一个数据包。 |
| RpcAvgTime | RPC 的平均时间。 |
| RpcCount | RPC 的总数。 |
Exchange Source 算子
| 指标 | 描述 |
|---|---|
| RequestReceived | 接收到的数据包的大小。 |
| BytesReceived | 接收到的数据的大小。 |
| DecompressChunkTime | 解压缩 Chunk 所花费的时间。 |
| DeserializeChunkTime | 反序列化 Chunk 所花费的时间。 |
| ClosureBlockCount | 被阻止的 Closure 的数量。 |
| ClosureBlockTime | Closure 的被阻止时间。 |
| ReceiverProcessTotalTime | 接收方处理所花费的总时间。 |
| WaitLockTime | 锁定等待时间。 |
Aggregate 算子
指标列表
| 指标 | 描述 |
|---|---|
GroupingKeys | GROUP BY 列。 |
AggregateFunctions | 聚合函数计算所花费的时间。 |
AggComputeTime | AggregateFunctions + Group By 的时间。 |
ChunkBufferPeakMem | Chunk Buffer 的峰值内存使用量。 |
ChunkBufferPeakSize | Chunk Buffer 的峰值大小。 |
ExprComputeTime | 表达式计算的时间。 |
ExprReleaseTime | 表达式释放的时间。 |
GetResultsTime | 提取聚合结果的时间。 |
HashTableSize | 哈希表的大小。 |
HashTableMemoryUsage | 哈希表的内存大小。 |
InputRowCount | 输入行数。 |
PassThroughRowCount | 在 Auto 模式下,在低聚合导致降级到流模式后,以流模式处理的数据行数。 |
ResultAggAppendTime | 追加聚合结果列所花费的时间。 |
ResultGroupByAppendTime | 追加 Group By 列所花费的时间。 |
ResultIteratorTime | 迭代哈希表的时间。 |
StreamingTime | 流模式下的处理时间。 |
Join 算子
指标列表
| 指标 | 描述 |
|---|---|
DistributionMode | 分发类型,包括:BROADCAST、PARTITIONED、COLOCATE 等。 |
JoinPredicates | Join 谓词。 |
JoinType | Join 类型。 |
BuildBuckets | 哈希表中的 Bucket 数量。 |
BuildKeysPerBucket | 哈希表中每个 Bucket 的键数。 |
BuildConjunctEvaluateTime | 在构建阶段进行 conjunct 评估所花费的时间。 |
BuildHashTableTime | 构建哈希表所花费的时间。 |
ProbeConjunctEvaluateTime | 在探测阶段进行 conjunct 评估所花费的时间。 |
SearchHashTableTimer | 搜索哈希表所花费的时间。 |
CopyRightTableChunkTime | 从右表复制 Chunk 所花费的时间。 |
OutputBuildColumnTime | 输出构建侧的列所花费的时间。 |
OutputProbeColumnTime | 输出探测侧的列所花费的时间。 |
HashTableMemoryUsage | 哈希表的内存使用量。 |
RuntimeFilterBuildTime | 构建运行时过滤器所花费的时间。 |
RuntimeFilterNum | 运行时过滤器的数量。 |
Window Function 算子
| 指标 | 描述 |
|---|---|
ProcessMode | 执行模式,包括两个部分:第一部分包括 Materializing 和 Streaming;第二部分包括 Cumulative、RemovableCumulative、ByDefinition。 |
ComputeTime | 窗口函数计算所花费的时间。 |
PartitionKeys | 分区列。 |
AggregateFunctions | 聚合函数。 |
ColumnResizeTime | 调整列大小所花费的时间。 |
PartitionSearchTime | 搜索分区边界所花费的时间。 |
PeerGroupSearchTime | 搜索 Peer Group 边界所花费的时间。仅当窗口类型为 RANGE 时才有意义。 |
PeakBufferedRows | 缓冲区中的峰值行数。 |
RemoveUnusedRowsCount | 删除未使用的缓冲区的次数。 |
RemoveUnusedTotalRows | 从未使用缓冲区中删除的总行数。 |
Sort 算子
| 指标 | 描述 |
|---|---|
SortKeys | 排序键。 |
SortType | 查询结果排序方法:全排序或对前 N 个结果进行排序。 |
MaxBufferedBytes | 缓冲数据的峰值大小。 |
MaxBufferedRows | 缓冲行的峰值数量。 |
NumSortedRuns | 排序运行的数量。 |
BuildingTime | 在排序期间维护内部数据结构所花费的时间。 |
MergingTime | 在排序期间合并排序运行所花费的时间。 |
SortingTime | 排序所花费的时间。 |
OutputTime | 构建输出排序序列所花费的时间。 |
Merge 算子
| 指标 | 描述 | Level |
|---|---|---|
Limit | 限制。 | Primary |
Offset | 偏移量。 | Primary |
StreamingBatchSize | 在 Streaming 模式下执行 Merge 操作时,每次 Merge 操作处理的数据大小 | Primary |
LateMaterializationMaxBufferChunkNum | 启用延迟物化时,缓冲区中的最大 Chunk 数量。 | Primary |
OverallStageCount | 所有阶段的总执行计数。 | Primary |
OverallStageTime | 每个阶段的总执行时间。 | Primary |
1-InitStageCount | Init 阶段的执行计数。 | Secondary |
2-PrepareStageCount | Prepare 阶段的执行计数。 | Secondary |
3-ProcessStageCount | Process 阶段的执行计数。 | Secondary |
4-SplitChunkStageCount | SplitChunk 阶段的执行计数。 | Secondary |
5-FetchChunkStageCount | FetchChunk 阶段的执行计数。 | Secondary |
6-PendingStageCount | Pending 阶段的执行计数。 | Secondary |
7-FinishedStageCount | Finished 阶段的执行计数。 | Secondary |
1-InitStageTime | Init 阶段的执行时间。 | Secondary |
2-PrepareStageTime | Prepare 阶段的执行时间。 | Secondary |
3-ProcessStageTime | Process 阶段的执行时间。 | Secondary |
4-SplitChunkStageTime | Split 阶段所花费的时间。 | Secondary |
5-FetchChunkStageTime | Fetch 阶段所花费的时间。 | Secondary |
6-PendingStageTime | Pending 阶段所花费的时间。 | Secondary |
7-FinishedStageTime | Finished 阶段所花费的时间。 | Secondary |
LateMaterializationGenerateOrdinalTime | 在延迟物化期间生成序号列所花费的时间。 | Tertiary |
SortedRunProviderTime | 在 Process 阶段从提供程序检索数据所花费的时间。 | Tertiary |
TableFunction 算子
| 指标 | 描述 |
|---|---|
TableFunctionExecTime | Table Function 的计算时间。 |
TableFunctionExecCount | Table Function 的执行次数。 |
Project 算子
Project 算子负责执行 SELECT <expr>。如果查询中存在一些开销很大的表达式,则此算子可能会花费大量时间。
| 指标 | 描述 |
|---|---|
ExprComputeTime | 表达式的计算时间。 |
CommonSubExprComputeTime | 公共子表达式的计算时间。 |
LocalExchange 算子
| 指标 | 描述 |
|---|---|
| 类型 | Local Exchange 的类型,包括:Passthrough、Partition 和 Broadcast。 |
ShuffleNum | Shuffle 的数量。此指标仅当 Type 为 Partition 时有效。 |
LocalExchangePeakMemoryUsage | 峰值内存使用量。 |
LocalExchangePeakBufferSize | 缓冲区的峰值大小。 |
LocalExchangePeakBufferMemoryUsage | 缓冲区的峰值内存使用量。 |
LocalExchangePeakBufferChunkNum | 缓冲区中的 Chunk 的峰值数量。 |
LocalExchangePeakBufferRowNum | 缓冲区中的峰值行数。 |
LocalExchangePeakBufferBytes | 缓冲区中数据的峰值大小。 |
LocalExchangePeakBufferChunkSize | 缓冲区中 Chunk 的峰值大小。 |
LocalExchangePeakBufferChunkRowNum | 缓冲区中每个 Chunk 的峰值行数。 |
LocalExchangePeakBufferChunkBytes | 缓冲区中每个 Chunk 的数据峰值大小。 |
OlapTableSink 算子
OlapTableSink 算子负责执行 INSERT INTO <table> 操作。
提示
OlapTableSink的PushChunkNum指标的 Max 值和 Min 值之间过大的差异表示上游算子中的数据倾斜,这可能会导致加载性能瓶颈。RpcClientSideTime等于RpcServerSideTime加上网络传输时间加上 RPC 框架处理时间。如果RpcClientSideTime和RpcServerSideTime之间存在显着差异,请考虑启用压缩以减少传输时间。
| 指标 | 描述 |
|---|---|
IndexNum | 为目标表创建的同步物化视图的数量。 |
ReplicatedStorage | 是否启用了 Single Leader Replication。 |
TxnID | 加载事务的 ID。 |
RowsRead | 从上游算子读取的行数。 |
RowsFiltered | 由于数据质量不足而过滤掉的行数。 |
RowsReturned | 写入目标表的行数。 |
RpcClientSideTime | 客户端记录的加载 RPC 总时间消耗。 |
RpcServerSideTime | 服务器端记录的加载 RPC 总时间消耗。 |
PrepareDataTime | 数据准备阶段的总时间消耗,包括数据格式转换和数据质量检查。 |
SendDataTime | 发送数据的本地时间消耗,包括序列化和压缩数据的时间,以及将任务提交到发送方队列的时间。 |