查询计划
优化查询性能是分析系统中常见的挑战。缓慢的查询可能会影响用户体验和整体集群性能。在 StarRocks 中,理解和解释查询计划和查询 Profile 是诊断和改进慢查询的基础。这些工具可以帮助您:
- 识别瓶颈和昂贵的操作
- 发现次优的 Join 策略或缺失的索引
- 了解数据如何被过滤、聚合和移动
- 排除故障并优化资源使用
查询计划是由 StarRocks FE 生成的详细路线图,描述了 SQL 语句的执行方式。它将查询分解为一系列操作(例如扫描、Join、聚合和排序),并确定执行这些操作的最有效方法。
StarRocks 提供了几种检查查询计划的方法:
-
EXPLAIN 语句:
使用EXPLAIN显示查询的逻辑或物理执行计划。您可以添加选项来控制输出:EXPLAIN LOGICAL <query>:显示简化的计划。EXPLAIN <query>:显示基本的物理计划。EXPLAIN VERBOSE <query>:显示带有详细信息的物理计划。EXPLAIN COSTS <query>:包括每个操作的估计成本,用于诊断统计信息问题。
-
EXPLAIN ANALYZE:
使用EXPLAIN ANALYZE <query>执行查询并显示实际的执行计划以及实际的运行时统计信息。有关详细信息,请参阅 Explain Anlayze 文档。示例
EXPLAIN ANALYZE SELECT * FROM sales_orders WHERE amount > 1000; -
Query Profile:
运行查询后,您可以查看其详细的执行 Profile,其中包括时间、资源使用情况和操作符级别的统计信息。有关如何访问和解释此信息,请参阅 Query Profile 文档。- SQL 命令:可以使用
SHOW PROFILELIST和ANALYZE PROFILE FOR <query_id>来检索特定查询的执行 Profile。 - FE HTTP Service:通过 StarRocks FE Web UI 访问查询 Profile,方法是导航到 Query 或 Profile 部分,您可以在其中搜索和检查查询执行详细信息。
- Managed Version:在云或托管部署中,使用提供的 Web 控制台或监控仪表板查看查询计划和 Profile,通常具有增强的可视化和过滤选项。
- SQL 命令:可以使用
通常,查询计划用于诊断与查询计划和优化方式相关的问题,而查询 Profile 有助于识别查询执行期间的性能问题。在以下各节中,我们将探讨查询执行的关键概念,并通过一个具体的示例来分析查询计划。
查询执行流程
查询在 StarRocks 中的生命周期包括三个主要阶段:
- 规划:查询经过解析、分析和优化,最终生成查询计划。
- 调度:调度器和协调器将计划分发到所有参与的后端节点。
- 执行:使用 Pipeline 执行引擎执行计划。
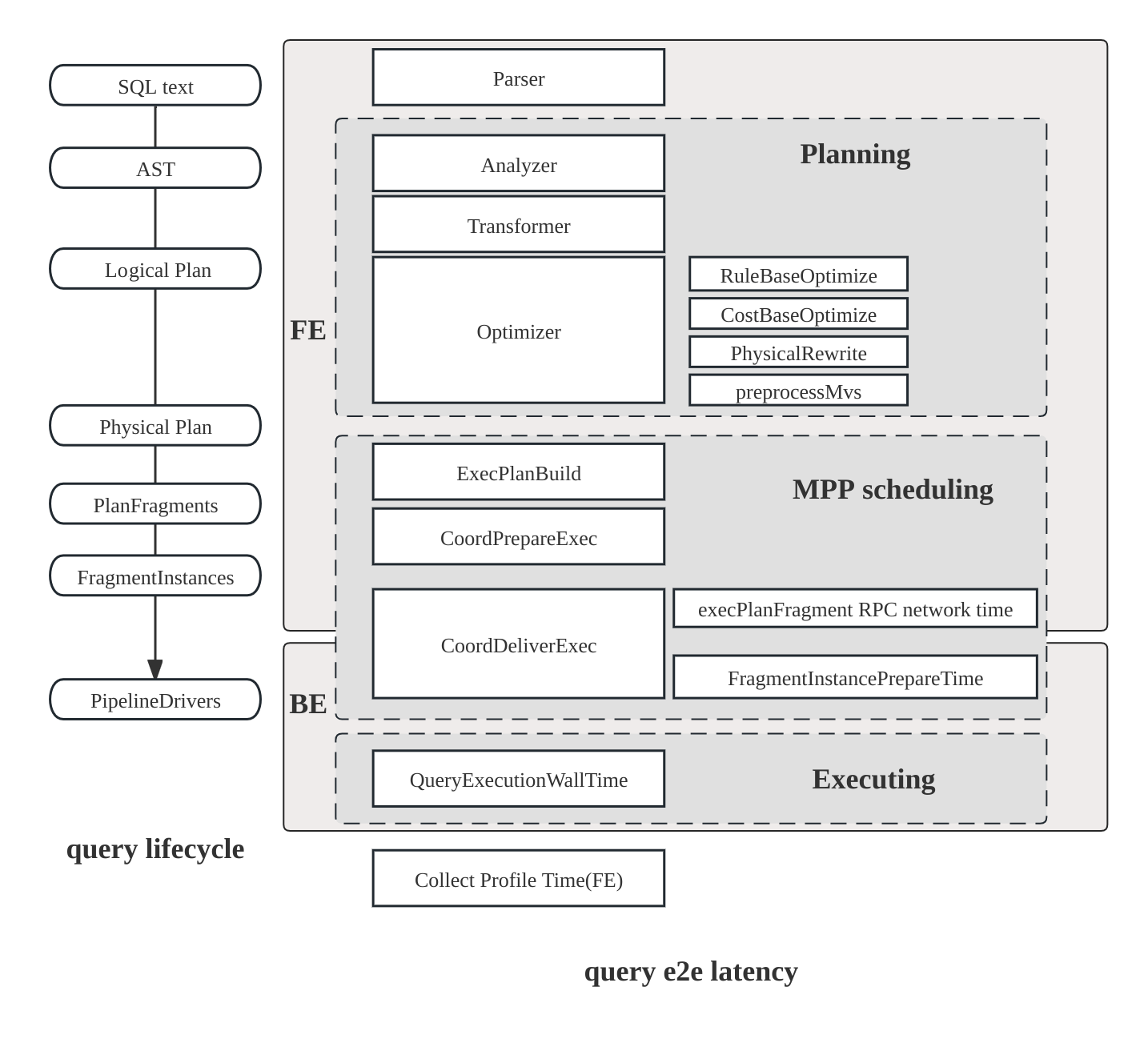
计划结构
StarRocks 计划是分层的:
- Fragment(片段):顶层工作切片;每个 Fragment 产生多个 FragmentInstance(片段实例),这些实例在不同的后端节点上运行。
- Pipeline(流水线):在一个实例中,Pipeline 将操作符连接在一起;多个 PipelineDrivers(流水线驱动)在单独的 CPU 核心上并发运行相同的 Pipeline。
- Operator(操作符):实际处理数据的原子步骤——扫描、Join、聚合。
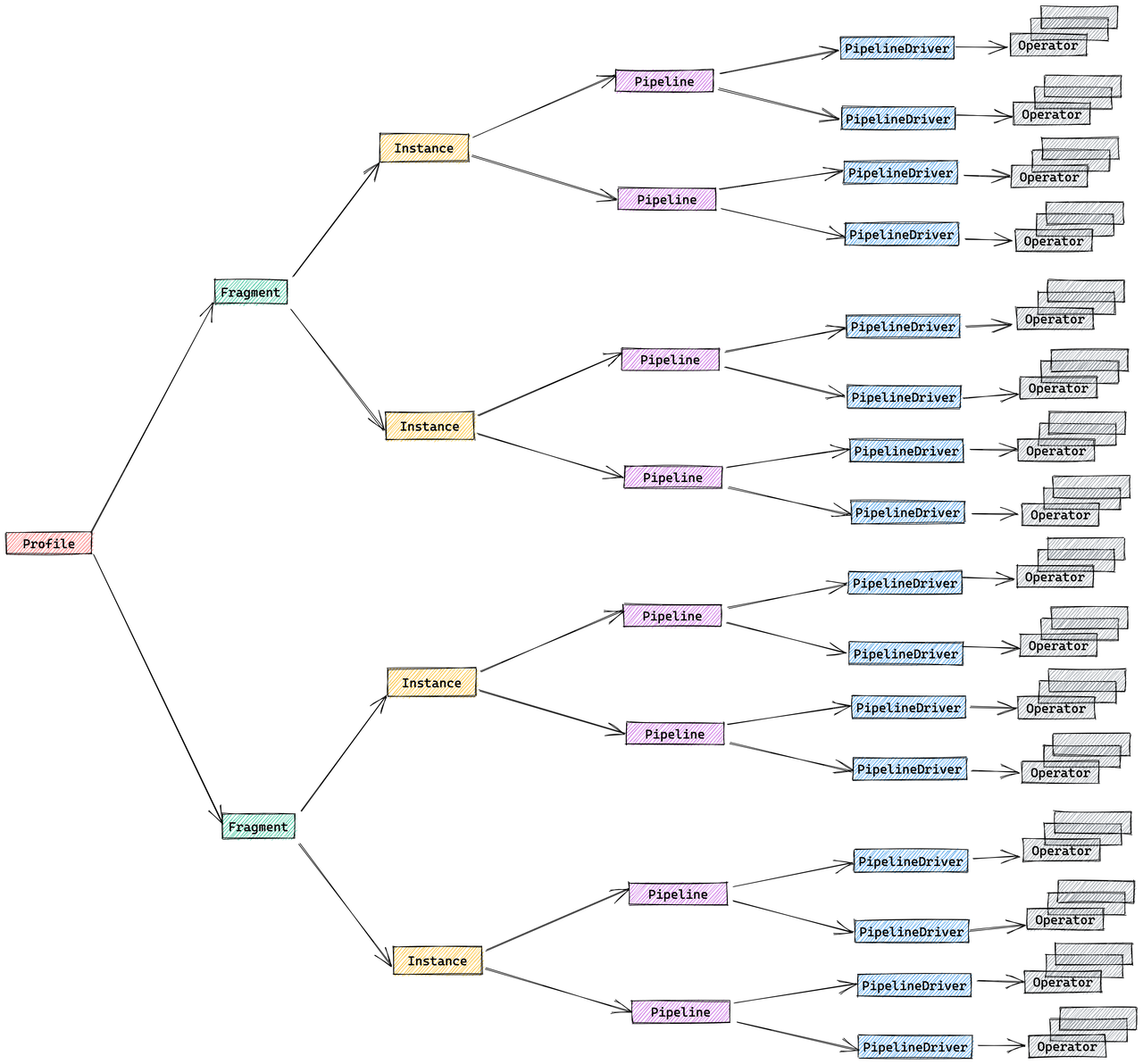
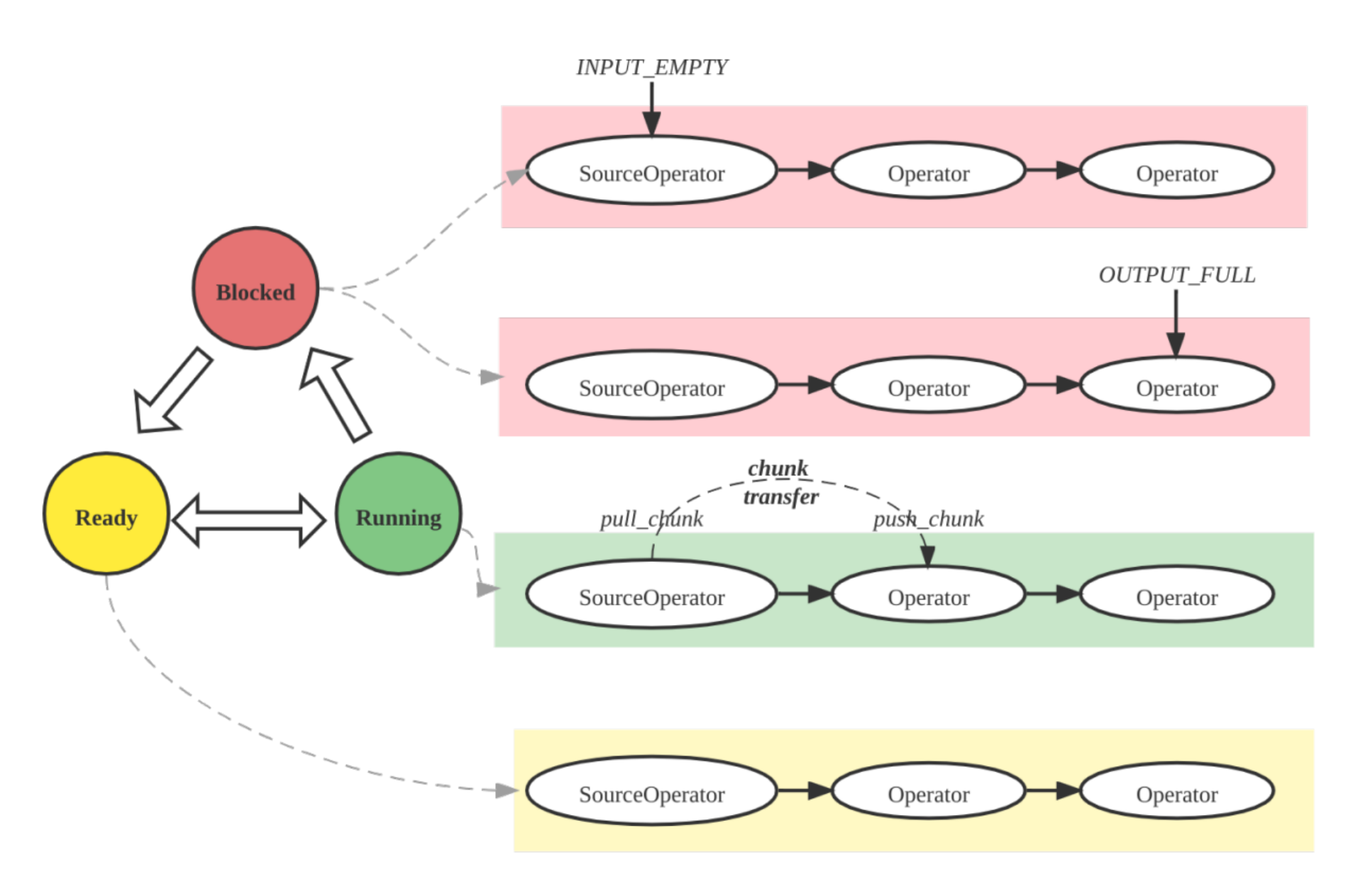
Pipeline 执行引擎
Pipeline 引擎以并行和高效的方式执行查询计划,处理复杂的计划和大量数据,以实现高性能和可伸缩性。
指标合并策略
默认情况下,StarRocks 合并 FragmentInstance 和 PipelineDriver 层以减少 Profile 体积,从而产生简化的三层结构:
- Fragment(片段)
- Pipeline(流水线)
- Operator(操作符)
您可以通过会话变量 pipeline_profile_level 控制此合并行为。
示例
如何阅读查询计划和 Profile
-
理解结构:查询计划分为 Fragment,每个 Fragment 代表一个执行阶段。从下往上读:首先是扫描节点,然后是 Join、聚合,最后是结果。
-
整体分析:
- 检查总运行时间、内存使用情况和 CPU/Wall time 比率。
- 通过按操作符时间排序来查找慢操作符。
- 确保尽可能下推过滤器。
- 查找数据倾斜(操作符时间或行数不均匀)。
- 监控高内存或磁盘溢出;如果需要,调整 Join 顺序或使用 Rollup 视图。
- 使用物化视图和查询提示(
BROADCAST、SHUFFLE、COLOCATE)根据需要进行优化。
-
扫描操作:查找
OlapScanNode或类似项。注意扫描哪些表,应用哪些过滤器,以及是否使用预聚合或物化视图。 -
Join 操作:识别 Join 类型(
HASH JOIN、BROADCAST、SHUFFLE、COLOCATE、BUCKET SHUFFLE)。Join 方法会影响性能:- Broadcast(广播):小表发送到所有节点;适用于小表。
- Shuffle(洗牌):行被分区和洗牌;适用于大表。
- Colocate(协同):表以相同的方式分区;启用本地 Join。
- Bucket Shuffle(桶洗牌):只洗牌一个表以减少网络成本。
-
聚合和排序:查找
AGGREGATE、TOP-N或ORDER BY。对于大型或高基数数据,这些操作可能很昂贵。 -
数据移动:
EXCHANGE节点显示 Fragment 或节点之间的数据传输。过多的数据移动会损害性能。 -
Predicate Pushdown(谓词下推):尽早(在扫描时)应用过滤器可减少下游数据。检查
PREDICATES或PushdownPredicates以查看下推了哪些过滤器。
查询计划示例
EXPLAIN select count(*)
from store_sales
,household_demographics
,time_dim
, store
where ss_sold_time_sk = time_dim.t_time_sk
and ss_hdemo_sk = household_demographics.hd_demo_sk
and ss_store_sk = s_store_sk
and time_dim.t_hour = 8
and time_dim.t_minute >= 30
and household_demographics.hd_dep_count = 5
and store.s_store_name = 'ese'
order by count(*) limit 100;
输出是一个分层计划,显示 StarRocks 如何执行查询,分为 Fragment 和操作符。这是一个简化的查询计划 Fragment 示例:
PLAN FRAGMENT 1
6:HASH JOIN (BROADCAST)
|-- 4:HASH JOIN (BROADCAST)
| |-- 2:HASH JOIN (BROADCAST)
| | |-- 0:OlapScanNode (store_sales)
| | |-- 1:OlapScanNode (time_dim)
| |-- 3:OlapScanNode (household_demographics)
|-- 5:OlapScanNode (store)
- OlapScanNode:扫描表,可能带有过滤器和预聚合。
- HASH JOIN (BROADCAST):通过广播较小的表来 Join 两个表。
- Fragments(片段):每个 Fragment 可以在不同的节点上并行执行。
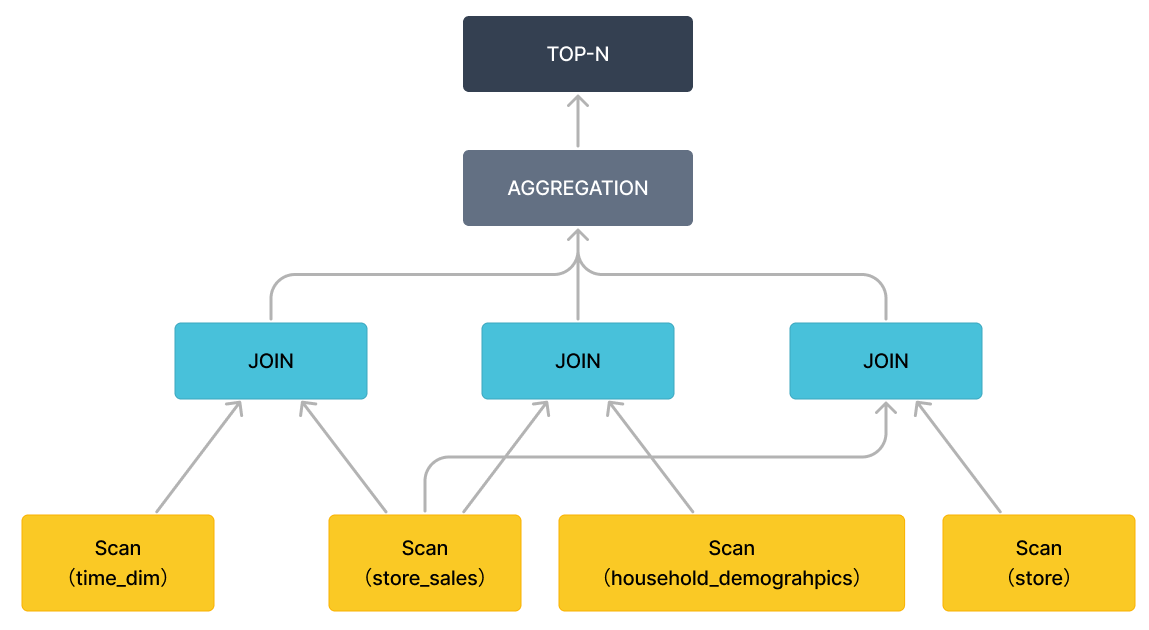
Query 96 的查询计划分为五个 Fragment,编号从 0 到 4。查询计划可以自下而上逐一读取。
Fragment 4 负责扫描 time_dim 表并提前执行相关的查询条件(即 time_dim.t_hour = 8 and time_dim.t_minute >= 30)。此步骤也称为谓词下推。StarRocks 决定是否为聚合表启用 PREAGGREGATION。在上图中,time_dim 的预聚合被禁用。在这种情况下,将读取 time_dim 的所有维度列,如果表中有很多维度列,这可能会对性能产生负面影响。如果 time_dim 表选择 range partition 进行数据划分,则会在查询计划中命中多个分区,并且会自动过滤掉不相关的分区。如果存在物化视图,StarRocks 将根据查询自动选择物化视图。如果没有物化视图,查询将自动命中基本表(例如,上图中的 rollup: time_dim)。
扫描完成后,Fragment 4 结束。数据将传递到其他 Fragment,如上图中的 EXCHANGE ID : 09 所示,传递到标记为 9 的接收节点。
对于 Query 96 的查询计划,Fragment 2、3 和 4 具有相似的功能,但它们负责扫描不同的表。具体来说,查询中的 Order/Aggregation/Join 操作在 Fragment 1 中执行。
Fragment 1 使用 BROADCAST 方法执行 Order/Aggregation/Join 操作,即将小表广播到大表。如果两个表都很大,我们建议您使用 SHUFFLE 方法。目前,StarRocks 仅支持 HASH JOIN。colocate 字段用于表明两个 Join 表以相同的方式进行分区和分桶,以便可以本地执行 Join 操作而无需迁移数据。Join 操作完成后,将执行上层 aggregation、order by 和 top-n 操作。
通过删除特定表达式(仅保留操作符),查询计划可以以更宏观的视图呈现,如下图所示。