查询 Hint
查询提示是指令或注释,它显式地建议查询优化器如何执行查询。目前,StarRocks 支持三种类型的提示:系统变量提示 (SET_VAR)、用户自定义变量提示 (SET_USER_VARIABLE) 和 Join 提示。提示仅在单个查询中生效。
系统变量提示
您可以使用 SET_VAR 提示在 SELECT 和 SUBMIT TASK 语句中设置一个或多个系统变量,然后执行这些语句。您还可以在包含在其他语句中的 SELECT 子句中使用 SET_VAR 提示,例如 CREATE MATERIALIZED VIEW AS SELECT 和 CREATE VIEW AS SELECT。请注意,如果在 CTE 的 SELECT 子句中使用 SET_VAR 提示,即使语句执行成功,SET_VAR 提示也不会生效。
与系统变量的一般用法在会话级别生效相比,SET_VAR 提示在语句级别生效,不会影响整个会话。
语法
[...] SELECT /*+ SET_VAR(key=value [, key = value]) */ ...
SUBMIT [/*+ SET_VAR(key=value [, key = value]) */] TASK ...
示例
要指定聚合查询的聚合模式,请使用 SET_VAR 提示在聚合查询中设置系统变量 streaming_preaggregation_mode 和 new_planner_agg_stage。
SELECT /*+ SET_VAR (streaming_preaggregation_mode = 'force_streaming',new_planner_agg_stage = '2') */ SUM(sales_amount) AS total_sales_amount FROM sales_orders;
要指定 SUBMIT TASK 语句的执行超时时间,请使用 SET_VAR 提示在 SUBMIT TASK 语句中设置系统变量 insert_timeout。
SUBMIT /*+ SET_VAR(insert_timeout=3) */ TASK AS CREATE TABLE temp AS SELECT count(*) AS cnt FROM tbl1;
要指定创建物化视图的子查询执行超时时间,请使用 SET_VAR 提示在 SELECT 子句中设置系统变量 query_timeout。
CREATE MATERIALIZED VIEW mv
PARTITION BY dt
DISTRIBUTED BY HASH(`key`)
BUCKETS 10
REFRESH ASYNC
AS SELECT /*+ SET_VAR(query_timeout=500) */ * from dual;
用户自定义变量提示
您可以使用 SET_USER_VARIABLE 提示在 SELECT 语句或 INSERT 语句中设置一个或多个用户自定义变量。如果其他语句包含 SELECT 子句,您也可以在该 SELECT 子句中使用 SET_USER_VARIABLE 提示。其他语句可以是 SELECT 语句和 INSERT 语句,但不能是 CREATE MATERIALIZED VIEW AS SELECT 语句和 CREATE VIEW AS SELECT 语句。请注意,如果在 CTE 的 SELECT 子句中使用 SET_USER_VARIABLE 提示,即使语句执行成功,SET_USER_VARIABLE 提示也不会生效。自 v3.2.4 起,StarRocks 支持用户自定义变量提示。
与用户自定义变量的一般用法在会话级别生效相比,SET_USER_VARIABLE 提示在语句级别生效,不会影响整个会话。
语法
[...] SELECT /*+ SET_USER_VARIABLE(@var_name = expr [, @var_name = expr]) */ ...
INSERT /*+ SET_USER_VARIABLE(@var_name = expr [, @var_name = expr]) */ ...
示例
以下 SELECT 语句引用标量子查询 select max(age) from users 和 select min(name) from users,因此您可以使用 SET_USER_VARIABLE 提示将这两个标量子查询设置为用户自定义变量,然后运行查询。
SELECT /*+ SET_USER_VARIABLE (@a = (select max(age) from users), @b = (select min(name) from users)) */ * FROM sales_orders where sales_orders.age = @a and sales_orders.name = @b;
Join 提示
对于多表 Join 查询,优化器通常会选择最佳的 Join 执行方法。在特殊情况下,您可以使用 Join 提示显式地建议优化器 Join 执行方法或禁用 Join 重排序。目前,Join 提示支持建议 Shuffle Join、Broadcast Join、Bucket Shuffle Join 或 Colocate Join 作为 Join 执行方法。使用 Join 提示时,优化器不会执行 Join 重排序。因此,您需要选择较小的表作为右表。此外,当建议Colocate Join或 Bucket Shuffle Join 作为 Join 执行方法时,请确保 Join 表的数据分布满足这些 Join 执行方法的要求。否则,建议的 Join 执行方法可能不会生效。
语法
... JOIN { [BROADCAST] | [SHUFFLE] | [BUCKET] | [COLOCATE] | [UNREORDER]} ...
Join 提示不区分大小写。
示例
-
Shuffle Join
如果需要在执行 Join 操作之前,将表 A 和表 B 中具有相同 bucketing key 值的数行数据 shuffle 到同一台机器上,您可以提示 Join 执行方法为 Shuffle Join。
select k1 from t1 join [SHUFFLE] t2 on t1.k1 = t2.k2 group by t2.k2; -
Broadcast Join
如果表 A 是一个大表,表 B 是一个小表,您可以提示 Join 执行方法为 Broadcast Join。表 B 的数据完全广播到表 A 数据所在的机器上,然后执行 Join 操作。与 Shuffle Join 相比,Broadcast Join 节省了 shuffle 表 A 数据的成本。
select k1 from t1 join [BROADCAST] t2 on t1.k1 = t2.k2 group by t2.k2; -
Bucket Shuffle Join
如果 Join 查询中的 Join 等值连接表达式包含表 A 的 bucketing key,尤其是在表 A 和表 B 都是大表时,您可以提示 Join 执行方法为 Bucket Shuffle Join。表 B 的数据根据表 A 的数据分布 shuffle 到表 A 数据所在的机器上,然后执行 Join 操作。与 Broadcast Join 相比,Bucket Shuffle Join 显著减少了数据传输,因为表 B 的数据仅全局 shuffle 一次。参与 Bucket Shuffle Join 的表必须是非分区表或 Colocate 表。
select k1 from t1 join [BUCKET] t2 on t1.k1 = t2.k2 group by t2.k2; -
Colocate Join
如果表 A 和表 B 属于同一个 Colocation Group(在创建表时指定),则来自表 A 和表 B 的具有相同 bucketing key 值的数行数据将分布在同一个 BE 节点上。当 Join 查询中的 Join 等值连接表达式包含表 A 和表 B 的 bucketing key 时,您可以提示 Join 执行方法为 Colocate Join。具有相同 key 值的数据直接在本地进行 Join,从而减少了节点间数据传输所花费的时间,并提高了查询性能。
select k1 from t1 join [COLOCATE] t2 on t1.k1 = t2.k2 group by t2.k2;
查看 Join 执行方法
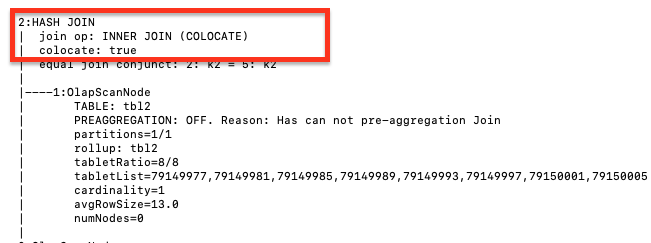
使用 EXPLAIN 命令查看实际的 Join 执行方法。如果返回的结果表明 Join 执行方法与 Join 提示匹配,则表示 Join 提示有效。
EXPLAIN select k1 from t1 join [COLOCATE] t2 on t1.k1 = t2.k2 group by t2.k2;