资源组
本文介绍了 StarRocks 的资源组功能。
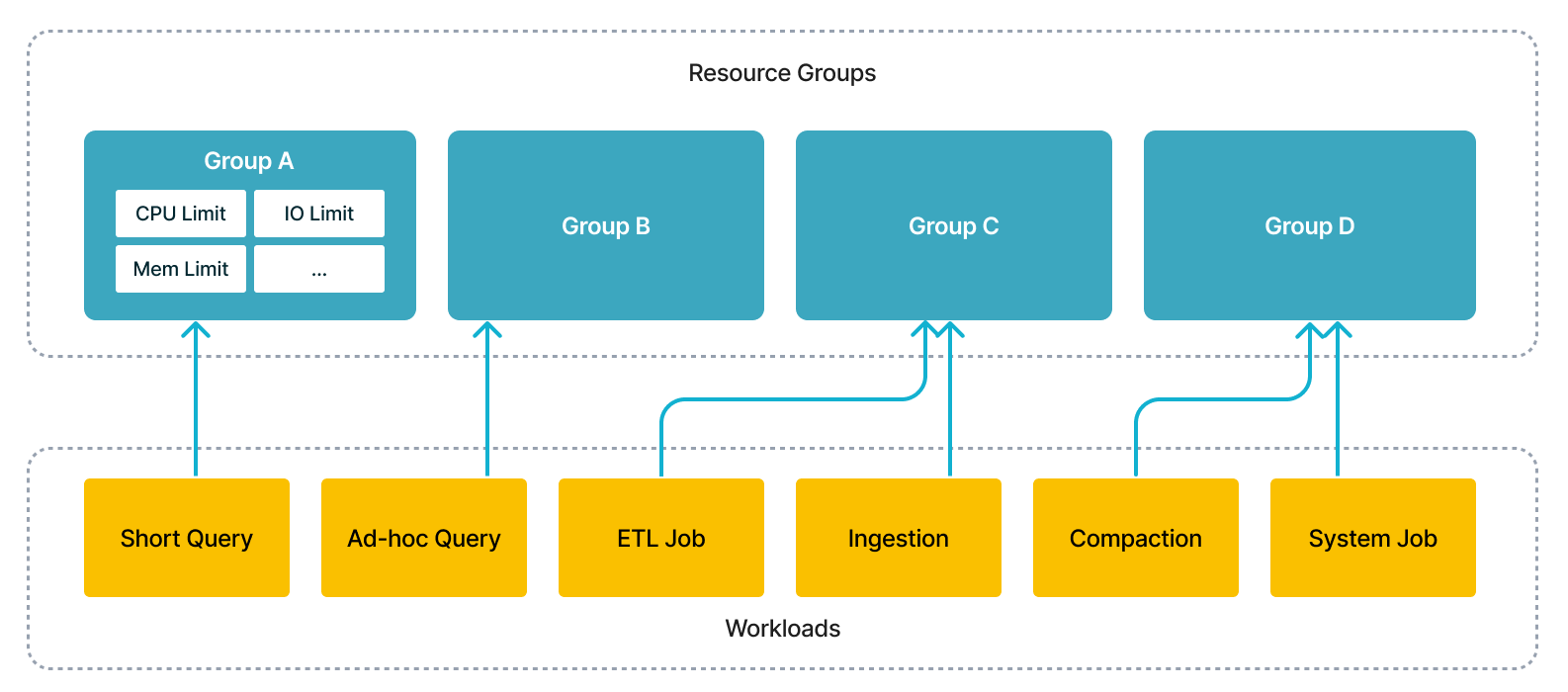
通过此功能,您可以在单个集群中同时运行多个工作负载,包括短查询、即席查询、ETL 作业,以节省部署多个集群的额外成本。从技术角度来看,执行引擎将根据用户的规范调度并发工作负载,并隔离它们之间的干扰。
资源组的路线图
- 从 v2.2 版本开始,StarRocks 支持限制查询的资源消耗,并在同一集群中的租户之间实现资源隔离和有效利用。
- 在 StarRocks v2.3 中,您可以进一步限制大查询的资源消耗,并防止集群资源被过大的查询请求耗尽,从而保证系统稳定性。
- StarRocks v2.5 支持限制数据加载(INSERT)的计算资源消耗。
- 从 v3.3.5 版本开始,StarRocks 支持对 CPU 资源施加硬限制。
| 内部表 | 外部表 | 大查询限制 | INSERT INTO | Broker Load | Routine Load, Stream Load, Schema Change | CPU 硬限制 | |
|---|---|---|---|---|---|---|---|
| 2.2 | √ | × | × | × | × | × | x |
| 2.3 | √ | √ | √ | × | × | × | x |
| 2.5 | √ | √ | √ | √ | × | × | x |
| 3.1 & 3.2 | √ | √ | √ | √ | √ | × | x |
| 3.3.5 及更高版本 | √ | √ | √ | √ | √ | × | √ |
术语
本节介绍了您在使用资源组功能之前必须了解的术语。
资源组
每个资源组都是来自特定 BE 的计算资源的集合。您可以将集群的每个 BE 划分为多个资源组。当查询被分配给资源组时,StarRocks 会根据您为资源组指定的资源配额为资源组分配 CPU 和内存资源。
您可以使用以下参数指定 BE 上资源组的 CPU 和内存资源配额
| 参数 | 描述 | 取值范围 | 默认 |
|---|---|---|---|
| cpu_weight | 此资源组在 BE 节点上的 CPU 调度权重。 | (0, avg_be_cpu_cores](大于 0 时生效) | 0 |
| exclusive_cpu_cores | 此资源组的 CPU 硬隔离参数。 | (0, min_be_cpu_cores - 1](大于 0 时生效) | 0 |
| mem_limit | 此资源组在当前 BE 节点上可用于查询的内存百分比。 | (0, 1](必需) | - |
| spill_mem_limit_threshold | 触发溢写到磁盘的内存使用阈值。 | (0, 1] | 1.0 |
| concurrency_limit | 此资源组中的最大并发查询数。 | 整数(大于 0 时生效) | 0 |
| big_query_cpu_second_limit | 每个 BE 节点上大查询任务的最大 CPU 时间(以秒为单位)。 | 整数(大于 0 时生效) | 0 |
| big_query_scan_rows_limit | 大查询任务在每个 BE 节点上可以扫描的最大行数。 | 整数(大于 0 时生效) | 0 |
| big_query_mem_limit | 大查询任务在每个 BE 节点上可以使用的最大内存。 | 整数(大于 0 时生效) | 0 |
CPU 资源参数
cpu_weight
此参数指定资源组在单个 BE 节点上的 CPU 调度权重,确定分配给来自该组的任务的 CPU 时间的相对份额。在 v3.3.5 之前,这被称为 cpu_core_limit。
其取值范围为 (0, avg_be_cpu_cores],其中 avg_be_cpu_cores 是所有 BE 节点的平均 CPU 核心数。该参数仅在设置为大于 0 时有效。cpu_weight 或 exclusive_cpu_cores 必须大于 0,但不能同时大于 0。
注意
例如,假设三个资源组 rg1、rg2 和 rg3 的 cpu_weight 值分别为 2、6 和 8。在完全加载的 BE 节点上,这些组将分别获得 12.5%、37.5% 和 50% 的 CPU 时间。如果节点未完全加载,并且 rg1 和 rg2 处于负载状态,而 rg3 处于空闲状态,则 rg1 和 rg2 将分别获得 25% 和 75% 的 CPU 时间。
exclusive_cpu_cores
此参数定义了资源组的 CPU 硬限制。它有两个含义
- 独占:为该资源组独占保留
exclusive_cpu_cores个 CPU 核心,即使在空闲时,其他组也无法使用它们。 - 配额:限制资源组仅使用这些保留的 CPU 核心,防止它使用来自其他组的可用 CPU 资源。
取值范围为 (0, min_be_cpu_cores - 1],其中 min_be_cpu_cores 是所有 BE 节点中的最小 CPU 核心数。仅当大于 0 时生效。cpu_weight 或 exclusive_cpu_cores 中只能有一个设置为大于 0。
exclusive_cpu_cores大于 0 的资源组称为独占资源组,分配给它们的 CPU 核心称为独占核心。其他组称为共享资源组,并在共享核心上运行。- 所有资源组的
exclusive_cpu_cores总数不能超过min_be_cpu_cores - 1。设置上限是为了至少保留一个可用的共享核心。
exclusive_cpu_cores 和 cpu_weight 之间的关系
cpu_weight 或 exclusive_cpu_cores 中一次只能激活一个。独占资源组在其自己的保留的独占核心上运行,而无需通过 cpu_weight 来共享 CPU 时间。
您可以使用 BE 配置 enable_resource_group_cpu_borrowing 来配置共享资源组是否可以从独占资源组借用独占核心。当设置为 true(默认)时,共享组可以在独占组空闲时借用 CPU 资源。
要动态修改此配置,请使用以下命令
UPDATE information_schema.be_configs SET VALUE = "false" WHERE NAME = "enable_resource_group_cpu_borrowing";
内存资源参数
mem_limit
指定当前 BE 节点上资源组可用的内存(查询池)百分比。取值范围为 (0,1]。
spill_mem_limit_threshold
定义触发溢写到磁盘的内存使用阈值。取值范围为 (0,1],默认值为 1(非活动)。在 v3.1.7 中引入。
- 当启用自动溢写(
spill_mode设置为auto)但禁用资源组时,当查询的内存使用量超过query_mem_limit的 80% 时,系统会将中间结果溢写到磁盘。 - 当启用资源组时,如果发生以下情况,将发生溢写
- 组中所有查询的总内存使用量超过
当前 BE 内存限制 * mem_limit * spill_mem_limit_threshold,或者 - 当前查询的内存使用量超过
query_mem_limit的 80%。
- 组中所有查询的总内存使用量超过
查询并发参数
concurrency_limit
定义资源组中的最大并发查询数,以防止系统过载。仅当大于 0 时有效,默认值为 0。
大查询资源参数
您可以使用以下参数专门为大型查询配置资源限制
big_query_cpu_second_limit
指定大型查询任务在每个 BE 节点上可以使用的最大 CPU 时间(以秒为单位),将并行任务使用的实际 CPU 时间相加。仅当大于 0 时有效,默认值为 0。
big_query_scan_rows_limit
设置大型查询任务在每个 BE 节点上可以扫描的行数的限制。仅当大于 0 时有效,默认值为 0。
big_query_mem_limit
定义大型查询任务在每个 BE 节点上可以使用的最大内存(以字节为单位)。仅当大于 0 时有效,默认值为 0。
注意
当资源组中运行的查询超过上述大查询限制时,查询将被终止并显示错误。您还可以在 FE 节点 fe.audit.log 的
ErrorCode列中查看错误消息。
类型(自 v3.3.5 起已弃用)
在 v3.3.5 之前,StarRocks 允许将资源组的 type 设置为 short_query。但是,参数 type 已被弃用,并由 exclusive_cpu_cores 替换。对于此类型的任何现有资源组,升级到 v3.3.5 后,系统会自动将它们转换为独占资源组,其中 exclusive_cpu_cores 值等于 cpu_weight。
系统定义的资源组
每个 StarRocks 实例中有两个系统定义的资源组:default_wg 和 default_mv_wg。您可以使用 ALTER RESOURCE GROUP 命令修改系统定义的资源组的配置,但不能为它们定义分类器或删除系统定义的资源组。
default_wg
default_wg 将分配给资源组管理下但不匹配任何分类器的常规查询。default_wg 的默认资源限制如下
cpu_core_limit:1(对于 v2.3.7 或更早版本)或 BE 的 CPU 核心数(对于高于 v2.3.7 的版本)。mem_limit: 100%.concurrency_limit: 0.big_query_cpu_second_limit: 0.big_query_scan_rows_limit: 0.big_query_mem_limit: 0.spill_mem_limit_threshold: 1.
default_mv_wg
如果在物化视图创建期间未在属性 resource_group 中为相应的物化视图分配资源组,则 default_mv_wg 将分配给异步物化视图刷新任务。default_mv_wg 的默认资源限制如下
cpu_core_limit: 1.mem_limit: 80%.concurrency_limit: 0.spill_mem_limit_threshold: 80%.
分类器
每个分类器都包含一个或多个可以与查询属性匹配的条件。StarRocks 根据匹配条件识别最匹配每个查询的分类器,并分配资源以运行查询。
分类器支持以下条件
user:用户名。role:用户的角色。query_type:查询的类型。支持SELECT和INSERT(来自 v2.5)。当 INSERT INTO 或 BROKER LOAD 任务命中query_type为insert的资源组时,BE 节点会为任务保留指定的 CPU 资源。source_ip:发起查询的 CIDR 块。db:查询访问的数据库。可以使用逗号,分隔的字符串指定。plan_cpu_cost_range:查询的估计 CPU 成本范围。格式为(DOUBLE, DOUBLE]。默认值为 NULL,表示没有此类限制。fe.audit.log中的PlanCpuCost列表示系统对查询的 CPU 成本的估计。从 v3.1.4 开始支持此参数。plan_mem_cost_range:查询的系统估计内存成本范围。格式为(DOUBLE, DOUBLE]。默认值为 NULL,表示没有此类限制。fe.audit.log中的PlanMemCost列表示系统对查询的内存成本的估计。从 v3.1.4 开始支持此参数。
仅当分类器的一个或所有条件与查询的信息匹配时,分类器才匹配查询。如果多个分类器匹配查询,StarRocks 会计算查询与每个分类器之间的匹配程度,并识别匹配程度最高的分类器。
注意
您可以在 FE 节点 fe.audit.log 的
ResourceGroup列中查看查询所属的资源组,或者通过运行EXPLAIN VERBOSE <query>,如查看查询的资源组中所述。
StarRocks 使用以下规则计算查询与分类器之间的匹配程度
- 如果分类器的
user值与查询的user值相同,则分类器的匹配程度增加 1。 - 如果分类器的
role值与查询的role值相同,则分类器的匹配程度增加 1。 - 如果分类器的
query_type值与查询的query_type值相同,则分类器的匹配程度增加 1 加上以下计算得出的数字:1/分类器中query_type字段的数量。 - 如果分类器的
source_ip值与查询的source_ip值相同,则分类器的匹配程度增加 1 加上以下计算得出的数字:(32 -cidr_prefix)/64。 - 如果分类器的
db值与查询的db值相同,则分类器的匹配程度增加 10。 - 如果查询的 CPU 成本落在
plan_cpu_cost_range内,则分类器的匹配程度增加 1。 - 如果查询的内存成本落在
plan_mem_cost_range内,则分类器的匹配程度增加 1。
如果多个分类器匹配查询,则条件数量较多的分类器具有较高的匹配程度。
-- Classifier B has more conditions than Classifier A. Therefore, Classifier B has a higher degree of matching than Classifier A.
classifier A (user='Alice')
classifier B (user='Alice', source_ip = '192.168.1.0/24')
如果多个匹配分类器具有相同数量的条件,则条件描述更准确的分类器具有更高的匹配程度。
-- The CIDR block that is specified in Classifier B is smaller in range than Classifier A. Therefore, Classifier B has a higher degree of matching than Classifier A.
classifier A (user='Alice', source_ip = '192.168.1.0/16')
classifier B (user='Alice', source_ip = '192.168.1.0/24')
-- Classifier C has fewer query types specified in it than Classifier D. Therefore, Classifier C has a higher degree of matching than Classifier D.
classifier C (user='Alice', query_type in ('select'))
classifier D (user='Alice', query_type in ('insert','select'))
如果多个分类器具有相同的匹配程度,则将随机选择其中一个分类器。
-- If a query simultaneously queries both db1 and db2 and the classifiers E and F have the
-- highest degree of matching among the hit classifiers, one of E and F will be randomly selected.
classifier E (db='db1')
classifier F (db='db2')
隔离计算资源
您可以通过配置资源组和分类器来隔离查询之间的计算资源。
启用资源组
要使用资源组,您必须为 StarRocks 集群启用 Pipeline Engine
-- Enable Pipeline Engine in the current session.
SET enable_pipeline_engine = true;
-- Enable Pipeline Engine globally.
SET GLOBAL enable_pipeline_engine = true;
注意
从 v3.1.0 开始,默认启用资源组,并且会话变量
enable_resource_group已被弃用。
创建资源组和分类器
执行以下语句以创建资源组,将资源组与分类器关联,并将计算资源分配给资源组
CREATE RESOURCE GROUP <group_name>
TO (
user='string',
role='string',
query_type in ('select'),
source_ip='cidr'
) --Create a classifier. If you create more than one classifier, separate the classifiers with commas (`,`).
WITH (
"{ cpu_weight | exclusive_cpu_cores }" = "INT",
"mem_limit" = "m%",
"concurrency_limit" = "INT",
"type" = "str" --The type of the resource group. Set the value to normal.
);
示例
CREATE RESOURCE GROUP rg1
TO
(user='rg1_user1', role='rg1_role1', query_type in ('select'), source_ip='192.168.x.x/24'),
(user='rg1_user2', query_type in ('select'), source_ip='192.168.x.x/24'),
(user='rg1_user3', source_ip='192.168.x.x/24'),
(user='rg1_user4'),
(db='db1')
WITH (
'exclusive_cpu_cores' = '10',
'mem_limit' = '20%',
'big_query_cpu_second_limit' = '100',
'big_query_scan_rows_limit' = '100000',
'big_query_mem_limit' = '1073741824'
);
指定资源组(可选)
您可以直接为当前会话指定资源组,包括 default_wg 和 default_mv_wg。
SET resource_group = 'group_name';
查看资源组和分类器
执行以下语句以查询所有资源组和分类器
SHOW RESOURCE GROUPS ALL;
执行以下语句以查询登录用户的资源组和分类器
SHOW RESOURCE GROUPS;
执行以下语句以查询指定的资源组及其分类器
SHOW RESOURCE GROUP group_name;
示例
mysql> SHOW RESOURCE GROUPS ALL;
+---------------+-------+------------+---------------------+-----------+----------------------------+---------------------------+---------------------+-------------------+---------------------------+----------------------------------------+
| name | id | cpu_weight | exclusive_cpu_cores | mem_limit | big_query_cpu_second_limit | big_query_scan_rows_limit | big_query_mem_limit | concurrency_limit | spill_mem_limit_threshold | classifiers |
+---------------+-------+------------+---------------------+-----------+----------------------------+---------------------------+---------------------+-------------------+---------------------------+----------------------------------------+
| default_mv_wg | 3 | 1 | 0 | 80.0% | 0 | 0 | 0 | null | 80% | (id=0, weight=0.0) |
| default_wg | 2 | 1 | 0 | 100.0% | 0 | 0 | 0 | null | 100% | (id=0, weight=0.0) |
| rge1 | 15015 | 0 | 6 | 90.0% | 0 | 0 | 0 | null | 100% | (id=15016, weight=1.0, user=rg1_user) |
| rgs1 | 15017 | 8 | 0 | 90.0% | 0 | 0 | 0 | null | 100% | (id=15018, weight=1.0, user=rgs1_user) |
| rgs2 | 15019 | 8 | 0 | 90.0% | 0 | 0 | 0 | null | 100% | (id=15020, weight=1.0, user=rgs2_user) |
+---------------+-------+------------+---------------------+-----------+----------------------------+---------------------------+---------------------+-------------------+---------------------------+----------------------------------------+
注意
在前面的示例中,
weight表示匹配程度。
要查询资源组的所有字段,包括已弃用的字段。
通过将关键字 VERBOSE 添加到上述三个命令中,您可以查看资源组的所有字段,包括已弃用的字段,例如 type 和 max_cpu_cores。
SHOW VERBOSE RESOURCE GROUPS ALL;
SHOW VERBOSE RESOURCE GROUPS;
SHOW VERBOSE RESOURCE GROUP group_name;
管理资源组和分类器
您可以修改每个资源组的资源配额。您还可以从资源组添加或删除分类器。
执行以下语句以修改现有资源组的资源配额
ALTER RESOURCE GROUP group_name WITH (
'cpu_core_limit' = 'INT',
'mem_limit' = 'm%'
);
执行以下语句以删除资源组
DROP RESOURCE GROUP group_name;
执行以下语句以将分类器添加到资源组
ALTER RESOURCE GROUP <group_name> ADD (user='string', role='string', query_type in ('select'), source_ip='cidr');
执行以下语句以从资源组中删除分类器
ALTER RESOURCE GROUP <group_name> DROP (CLASSIFIER_ID_1, CLASSIFIER_ID_2, ...);
执行以下语句以删除资源组的所有分类器
ALTER RESOURCE GROUP <group_name> DROP ALL;
观察资源组
查看查询的资源组
对于尚未执行的查询,您可以从 EXPLAIN VERBOSE <query> 返回的 RESOURCE GROUP 字段中查看查询匹配的资源组。
在查询运行时,您可以从 SHOW PROC '/current_queries' 和 SHOW PROC '/global_current_queries' 返回的 ResourceGroup 字段中检查查询命中的资源组。
查询完成后,您可以通过检查 FE 节点上的 fe.audit.log 文件中的 ResourceGroup 字段来查看查询匹配的资源组。
- 如果查询不受资源组管理,则列值为空字符串
""。 - 如果查询受资源组管理但不匹配任何分类器,则列值为空字符串
""。但是此查询已分配给默认资源组default_wg。
监控资源组
您可以为资源组设置监控和警报。
与资源组相关的 FE 和 BE 指标如下所示。以下所有指标都有一个 name 标签,指示其对应的资源组。
FE 指标
以下 FE 指标仅提供当前 FE 节点内的统计信息
| 指标 | 单位 | 类型 | 描述 |
|---|---|---|---|
| starrocks_fe_query_resource_group | 计数 | 瞬时 | 此资源组中历史上运行的查询数(包括当前正在运行的查询)。 |
| starrocks_fe_query_resource_group_latency | 毫秒 | 瞬时 | 此资源组的查询延迟百分位数。标签 type 指示特定的百分位数,包括 mean、75_quantile、95_quantile、98_quantile、99_quantile、999_quantile。 |
| starrocks_fe_query_resource_group_err | 计数 | 瞬时 | 此资源组中遇到错误的查询数。 |
| starrocks_fe_resource_group_query_queue_total | 计数 | 瞬时 | 此资源组中历史上排队的总查询数(包括当前正在运行的查询)。从 v3.1.4 开始支持此指标。仅在启用查询队列时有效。 |
| starrocks_fe_resource_group_query_queue_pending | 计数 | 瞬时 | 此资源组队列中当前的查询数。从 v3.1.4 开始支持此指标。仅在启用查询队列时有效。 |
| starrocks_fe_resource_group_query_queue_timeout | 计数 | 瞬时 | 此资源组中在队列中超时的查询数。从 v3.1.4 开始支持此指标。仅在启用查询队列时有效。 |
BE 指标
| 指标 | 单位 | 类型 | 描述 |
|---|---|---|---|
| resource_group_running_queries | 计数 | 瞬时 | 此资源组中当前正在运行的查询数。 |
| resource_group_total_queries | 计数 | 瞬时 | 此资源组中历史上运行的查询数(包括当前正在运行的查询)。 |
| resource_group_bigquery_count | 计数 | 瞬时 | 此资源组中触发大查询限制的查询数。 |
| resource_group_concurrency_overflow_count | 计数 | 瞬时 | 此资源组中触发 concurrency_limit 限制的查询数。 |
| resource_group_mem_limit_bytes | 字节 | 瞬时 | 此资源组的内存限制。 |
| resource_group_mem_inuse_bytes | 字节 | 瞬时 | 此资源组当前正在使用的内存。 |
| resource_group_cpu_limit_ratio | 百分比 | 瞬时 | 此资源组的 cpu_core_limit 与所有资源组的总 cpu_core_limit 的比率。 |
| resource_group_inuse_cpu_cores | 计数 | 平均值 | 此资源组正在使用的估计 CPU 核心数。此值是一个近似估计。它表示基于两次连续指标收集的统计信息计算的平均值。从 v3.1.4 开始支持此指标。 |
| resource_group_cpu_use_ratio | 百分比 | 平均值 | 已弃用 此资源组使用的 Pipeline 线程时间片与所有资源组使用的总 Pipeline 线程时间片的比率。它表示基于两次连续指标收集的统计信息计算的平均值。 |
| resource_group_connector_scan_use_ratio | 百分比 | 平均值 | 已弃用 此资源组使用的外部表扫描线程时间片与所有资源组使用的总 Pipeline 线程时间片的比率。它表示基于两次连续指标收集的统计信息计算的平均值。 |
| resource_group_scan_use_ratio | 百分比 | 平均值 | 已弃用 此资源组使用的内部表扫描线程时间片与所有资源组使用的总 Pipeline 线程时间片的比率。它表示基于两次连续指标收集的统计信息计算的平均值。 |
查看资源组使用信息
从 v3.1.4 开始,StarRocks 支持 SQL 语句 SHOW USAGE RESOURCE GROUPS,该语句用于显示每个资源组在 BE 上的使用信息。每个字段的描述如下
Name:资源组的名称。Id:资源组的 ID。Backend:BE 的 IP 或 FQDN。BEInUseCpuCores:此资源组在此 BE 上当前正在使用的 CPU 核心数。此值是一个近似估计。BEInUseMemBytes:此资源组在此 BE 上当前正在使用的内存字节数。BERunningQueries:此资源组中仍在 BE 上运行的查询数。
请注意
- BE 以
report_resource_usage_interval_ms中指定的间隔定期向 Leader FE 报告此资源使用信息,默认设置为 1 秒。 - 结果将仅显示
BEInUseCpuCores/BEInUseMemBytes/BERunningQueries中至少有一个是正数的行。换句话说,仅当资源组正在 BE 上主动使用某些资源时才会显示信息。
示例
MySQL [(none)]> SHOW USAGE RESOURCE GROUPS;
+------------+----+-----------+-----------------+-----------------+------------------+
| Name | Id | Backend | BEInUseCpuCores | BEInUseMemBytes | BERunningQueries |
+------------+----+-----------+-----------------+-----------------+------------------+
| default_wg | 0 | 127.0.0.1 | 0.100 | 1 | 5 |
+------------+----+-----------+-----------------+-----------------+------------------+
| default_wg | 0 | 127.0.0.2 | 0.200 | 2 | 6 |
+------------+----+-----------+-----------------+-----------------+------------------+
| wg1 | 0 | 127.0.0.1 | 0.300 | 3 | 7 |
+------------+----+-----------+-----------------+-----------------+------------------+
| wg2 | 0 | 127.0.0.1 | 0.400 | 4 | 8 |
+------------+----+-----------+-----------------+-----------------+------------------+
查看独占和共享资源组的线程信息
查询执行主要涉及三个线程池:pip_exec、pip_scan 和 pip_con_scan。
- 独占资源组在其专用线程池中运行,并绑定到分配给它们的独占 CPU 核心。
- 共享资源组在共享线程池中运行,并绑定到剩余的共享 CPU 核心。
这三个池中的线程遵循命名约定 { pip_exec | pip_scan | pip_con_scan }_{ com | <resource_group_id> },其中 com 指的是共享线程池,<resource_group_id> 指的是独占资源组的 ID。
您可以通过系统定义的视图 information_schema.be_threads 查看绑定到每个 BE 线程的 CPU 信息。字段 BE_ID、NAME 和 BOUND_CPUS 分别代表 BE 的 ID、线程的名称和绑定到该线程的 CPU 核心数。
select * from information_schema.be_threads where name like '%pip_exec%';
select * from information_schema.be_threads where name like '%pip_scan%';
select * from information_schema.be_threads where name like '%pip_con_scan%';
示例
select BE_ID, NAME, FINISHED_TASKS, BOUND_CPUS from information_schema.be_threads where name like '%pip_exec_com%' and be_id = 10223;
+-------+--------------+----------------+------------+
| BE_ID | NAME | FINISHED_TASKS | BOUND_CPUS |
+-------+--------------+----------------+------------+
| 10223 | pip_exec_com | 2091295 | 10 |
| 10223 | pip_exec_com | 2088025 | 10 |
| 10223 | pip_exec_com | 1637603 | 6 |
| 10223 | pip_exec_com | 1641260 | 6 |
| 10223 | pip_exec_com | 1634197 | 6 |
| 10223 | pip_exec_com | 1633804 | 6 |
| 10223 | pip_exec_com | 1638184 | 6 |
| 10223 | pip_exec_com | 1636374 | 6 |
| 10223 | pip_exec_com | 2095951 | 10 |
| 10223 | pip_exec_com | 2095248 | 10 |
| 10223 | pip_exec_com | 2098745 | 10 |
| 10223 | pip_exec_com | 2085338 | 10 |
| 10223 | pip_exec_com | 2101221 | 10 |
| 10223 | pip_exec_com | 2093901 | 10 |
| 10223 | pip_exec_com | 2092364 | 10 |
| 10223 | pip_exec_com | 2091366 | 10 |
+-------+--------------+----------------+------------+