使用 Prometheus 和 Grafana 进行监控和告警
StarRocks 通过使用 Prometheus 和 Grafana 提供监控和告警解决方案。这允许您可视化集群的运行状况,从而方便监控和故障排除。
概述
StarRocks 提供与 Prometheus 兼容的信息收集接口。 Prometheus 可以通过连接 BE 和 FE 节点的 HTTP 端口来检索 StarRocks 的指标信息,并将信息存储在自己的时间序列数据库中。 然后,Grafana 可以使用 Prometheus 作为数据源来可视化指标信息。 通过使用 StarRocks 提供的仪表盘模板,您可以轻松监控 StarRocks 集群,并使用 Grafana 为其设置告警。
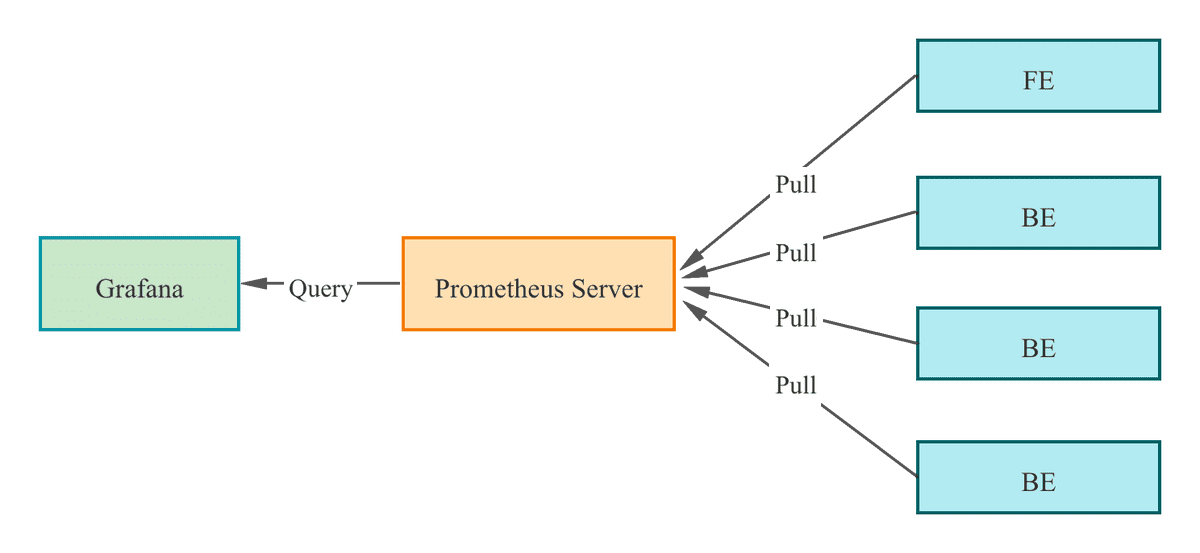
请按照以下步骤将 StarRocks 集群与 Prometheus 和 Grafana 集成
- 安装必要的组件 - Prometheus 和 Grafana。
- 了解 StarRocks 的核心监控指标。
- 设置告警渠道和告警规则。
步骤 1:安装监控组件
Prometheus 和 Grafana 的默认端口与 StarRocks 的端口不冲突。 但是,建议将它们部署在与 StarRocks 集群不同的服务器上以进行生产。 这降低了资源冲突的风险,并避免了由于服务器异常关闭而导致的潜在告警失败。
此外,请注意 Prometheus 和 Grafana 无法监控其自身服务的可用性。 因此,在生产环境中,建议使用 Supervisor 为它们设置心跳服务。
以下教程使用 root OS 用户在监控节点 (IP: 192.168.110.23) 上部署监控组件。 它们监控以下 StarRocks 集群(使用默认端口)。 根据本教程为自己的 StarRocks 集群设置监控服务时,只需替换 IP 地址即可。
| 主机 | IP | 操作系统用户 | 服务 |
|---|---|---|---|
| node01 | 192.168.110.101 | 根 | 1 FE + 1 BE |
| node02 | 192.168.110.102 | 根 | 1 FE + 1 BE |
| node03 | 192.168.110.103 | 根 | 1 FE + 1 BE |
注意
Prometheus 和 Grafana 只能监控 FE、BE 和 CN 节点,不能监控 Broker 节点。
1.1 部署 Prometheus
1.1.1 下载 Prometheus
对于 StarRocks,您只需要下载 Prometheus 服务器的安装包。 将软件包下载到监控节点。
以 LTS 版本 v2.45.0 为例,单击软件包下载。
或者,您可以使用 wget 命令下载它
# The following example downloads the LTS version v2.45.0.
# You can download other versions by replacing the version number in the command.
wget https://github.com/prometheus/prometheus/releases/download/v2.45.0/prometheus-2.45.0.linux-amd64.tar.gz
下载完成后,将安装包上传或复制到监控节点上的目录 /opt。
1.1.2 安装 Prometheus
-
导航到 /opt 并解压缩 Prometheus 安装包。
cd /opt
tar xvf prometheus-2.45.0.linux-amd64.tar.gz -
为了便于管理,请将解压后的目录重命名为 prometheus。
mv prometheus-2.45.0.linux-amd64 prometheus -
为 Prometheus 创建数据存储路径。
mkdir prometheus/data -
为了便于管理,您可以为 Prometheus 创建一个系统服务启动文件。
vim /etc/systemd/system/prometheus.service将以下内容添加到文件中
[Unit]
Description=Prometheus service
After=network.target
[Service]
User=root
Type=simple
ExecReload=/bin/sh -c "/bin/kill -1 `/usr/bin/pgrep prometheus`"
ExecStop=/bin/sh -c "/bin/kill -9 `/usr/bin/pgrep prometheus`"
ExecStart=/opt/prometheus/prometheus --config.file=/opt/prometheus/prometheus.yml --storage.tsdb.path=/opt/prometheus/data --storage.tsdb.retention.time=30d --storage.tsdb.retention.size=30GB
[Install]
WantedBy=multi-user.target然后,保存并退出编辑器。
注意
如果您在不同的路径下部署 Prometheus,请确保同步上述文件中 ExecStart 命令中的路径。 此外,该文件将 Prometheus 数据存储的过期条件配置为“30 天或更长时间”或“大于 30 GB”。 您可以根据需要修改此设置。
-
修改 Prometheus 配置文件 prometheus/prometheus.yml。 该文件对内容格式有严格要求。 修改时请特别注意空格和缩进。
vim prometheus/prometheus.yml将以下内容添加到文件中
global:
scrape_interval: 15s # Set the global scrape interval to 15s. The default is 1 min.
evaluation_interval: 15s # Set the global rule evaluation interval to 15s. The default is 1 min.
scrape_configs:
- job_name: 'StarRocks_Cluster01' # A cluster being monitored corresponds to a job. You can customize the StarRocks cluster name here.
metrics_path: '/metrics' # Specify the Restful API for retrieving monitoring metrics.
static_configs:
# The following configuration specifies an FE group, which includes 3 FE nodes.
# Here, you need to fill in the IP and HTTP ports corresponding to each FE.
# If you modified the HTTP ports during cluster deployment, make sure to adjust them accordingly.
- targets: ['192.168.110.101:8030','192.168.110.102:8030','192.168.110.103:8030']
labels:
group: fe
# The following configuration specifies a BE group, which includes 3 BE nodes.
# Here, you need to fill in the IP and HTTP ports corresponding to each BE.
# If you modified the HTTP ports during cluster deployment, make sure to adjust them accordingly.
- targets: ['192.168.110.101:8040','192.168.110.102:8040','192.168.110.103:8040']
labels:
group: be修改配置文件后,可以使用
promtool验证修改是否有效。./prometheus/promtool check config prometheus/prometheus.yml以下提示表明检查已通过。 然后您可以继续。
SUCCESS: prometheus/prometheus.yml is valid prometheus config file syntax -
启动 Prometheus。
systemctl daemon-reload
systemctl start prometheus.service -
检查 Prometheus 的状态。
systemctl status prometheus.service如果返回
Active: active (running),则表示 Prometheus 已成功启动。您也可以使用
netstat检查默认 Prometheus 端口 (9090) 的状态。netstat -nltp | grep 9090 -
设置 Prometheus 在启动时启动。
systemctl enable prometheus.service
其他命令:
-
停止 Prometheus。
systemctl stop prometheus.service -
重新启动 Prometheus。
systemctl restart prometheus.service -
在运行时重新加载配置。
systemctl reload prometheus.service -
禁用启动时启动。
systemctl disable prometheus.service
1.1.3 访问 Prometheus
您可以通过浏览器访问 Prometheus Web UI,默认端口为 9090。 对于本教程中的监控节点,您需要访问 192.168.110.23:9090。
在 Prometheus 主页上,导航到顶部菜单中的 Status --> Targets。 在这里,您可以看到在 prometheus.yml 文件中配置的每个组作业的所有受监控节点。 通常,所有节点的状态都应为 UP,表示服务通信正常。
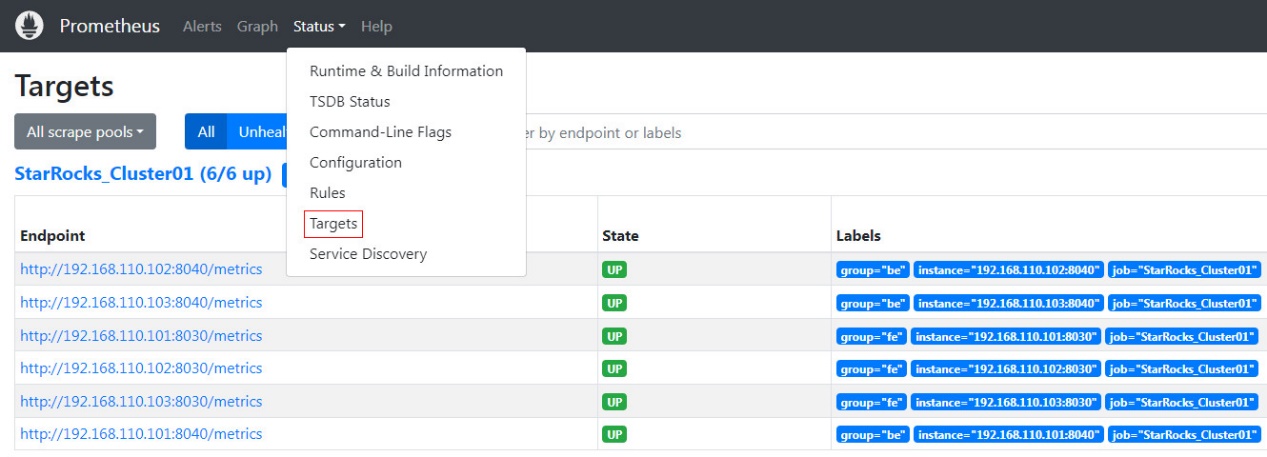
此时,Prometheus 已配置和设置。 有关更多详细信息,您可以参考 Prometheus 文档。
1.2 部署 Grafana
1.2.1 下载 Grafana
或者,您可以使用 wget 命令下载 Grafana RPM 安装包。
# The following example downloads the LTS version v10.0.3.
# You can download other versions by replacing the version number in the command.
wget https://dl.grafana.com/enterprise/release/grafana-enterprise-10.0.3-1.x86_64.rpm
1.2.2 安装 Grafana
-
使用
yum命令安装 Grafana。 此命令将自动安装 Grafana 所需的依赖项。yum -y install grafana-enterprise-10.0.3-1.x86_64.rpm -
启动 Grafana。
systemctl start grafana-server.service -
检查 Grafana 的状态。
systemctl status grafana-server.service如果返回
Active: active (running),则表示 Grafana 已成功启动。您也可以使用
netstat检查默认 Grafana 端口 (3000) 的状态。netstat -nltp | grep 3000 -
设置 Grafana 在启动时启动。
systemctl enable grafana-server.service
其他命令:
-
停止 Grafana。
systemctl stop grafana-server.service -
重新启动 Grafana。
systemctl restart grafana-server.service -
禁用启动时启动。
systemctl disable grafana-server.service
有关更多信息,请参阅 Grafana 文档。
1.2.3 访问 Grafana
您可以通过浏览器访问 Grafana Web UI,默认端口为 3000。 对于本教程中的监控节点,您需要访问 192.168.110.23:3000。 登录所需的默认用户名和密码均设置为 admin。 首次登录时,Grafana 将提示您更改默认登录密码。 如果您现在想跳过此步骤,可以单击 Skip。 然后,您将被重定向到 Grafana Web UI 主页。
1.2.4 配置数据源
单击左上角的菜单按钮,展开 Administration,然后单击 Data sources。
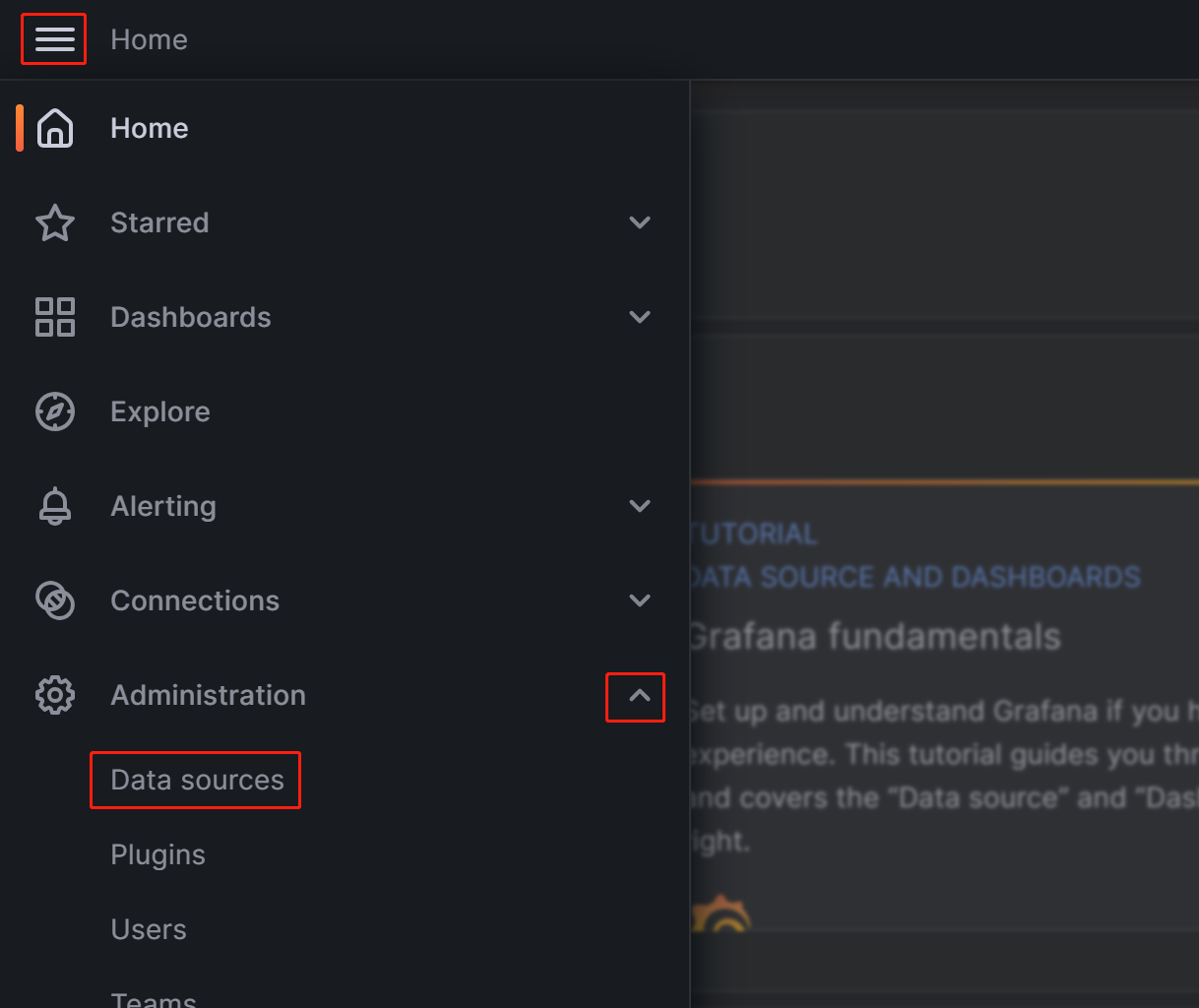
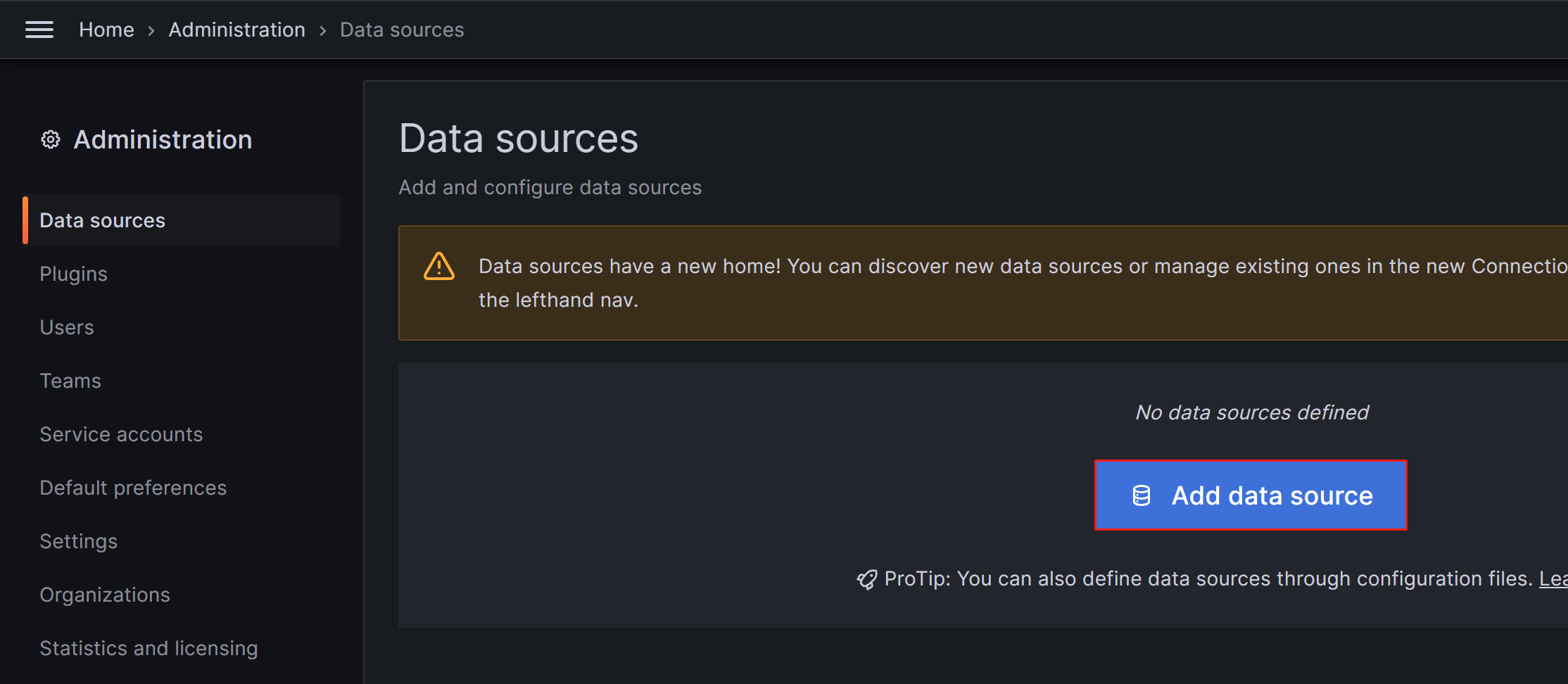
在出现的页面上,单击 Add data source,然后选择 Prometheus。
要将 Grafana 与您的 Prometheus 服务集成,您需要修改以下配置
-
Name:数据源的名称。 您可以自定义数据源的名称。

-
Prometheus Server URL:Prometheus 服务器的 URL,在本教程中为
http://192.168.110.23:9090。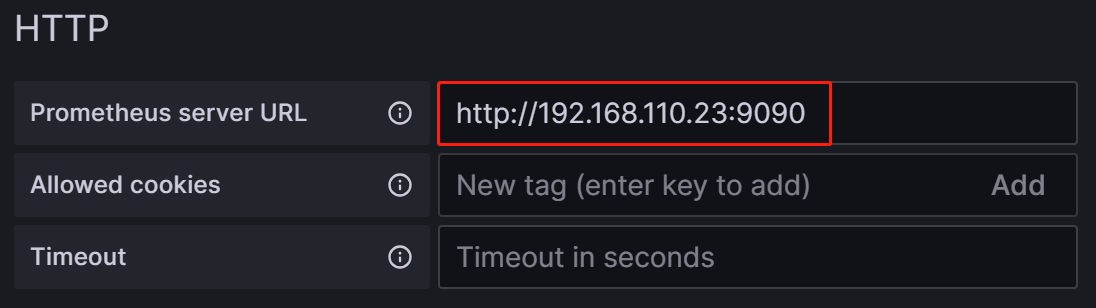
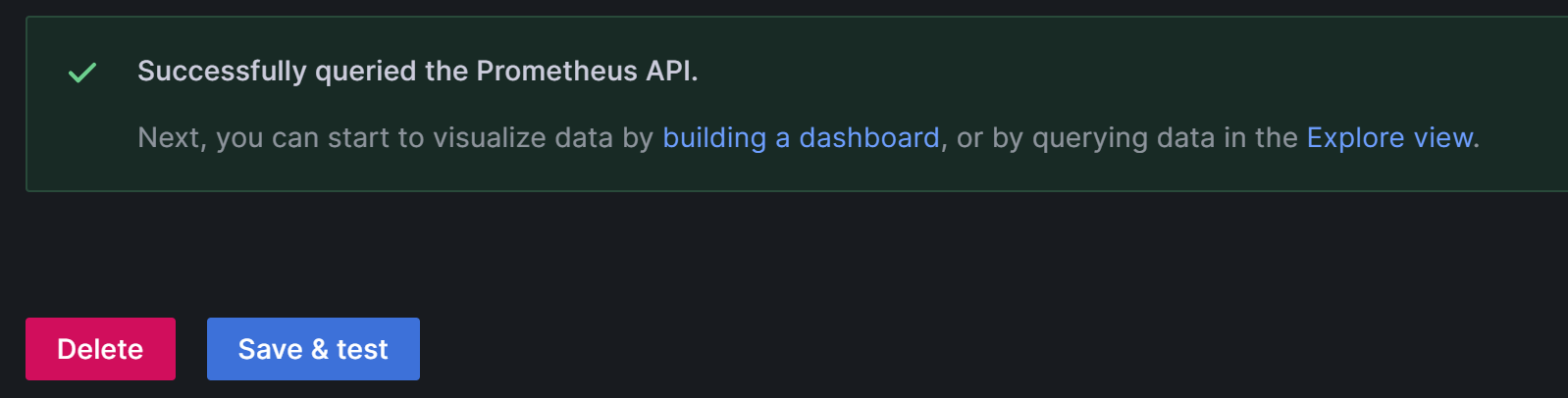
配置完成后,单击 Save & Test 以保存和测试配置。 如果显示 Successfully queried the Prometheus API,则表示数据源可访问。
1.2.5 配置仪表盘
-
根据您的 StarRocks 版本下载相应的仪表盘模板。
注意
需要通过 Grafana Web UI 上传模板文件。 因此,您需要将模板文件下载到用于访问 Grafana 的计算机,而不是监控节点本身。
-
配置仪表盘模板。
单击左上角的菜单按钮,然后单击 Dashboards。
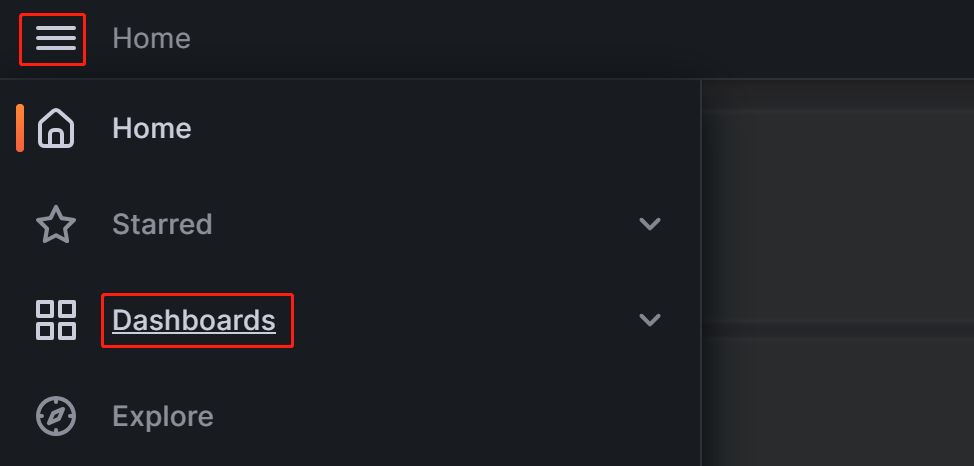
在出现的页面上,展开 New 按钮,然后单击 Import。
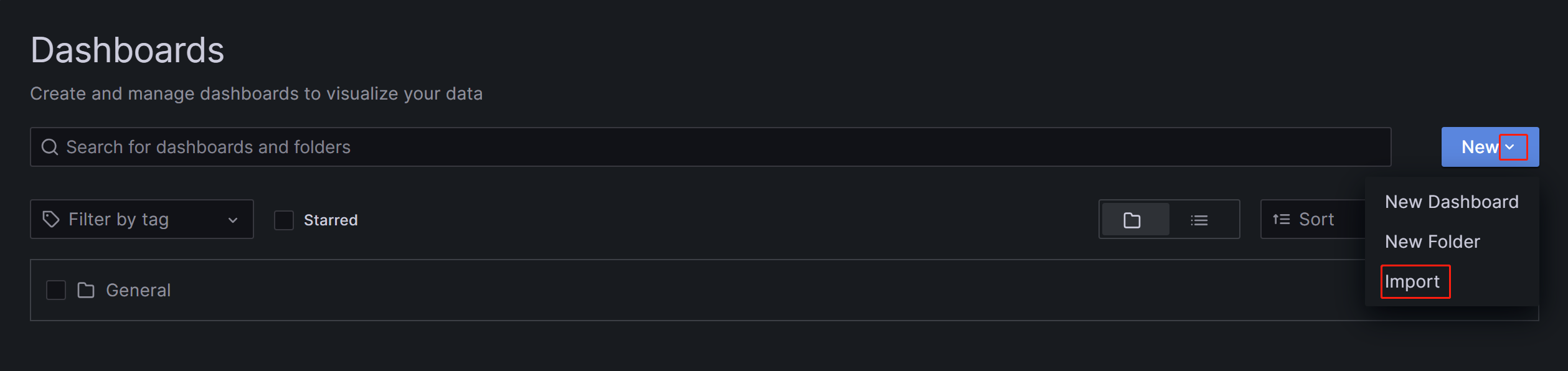
在新页面上,单击 Upload Dashboard JSON file 并上传您之前下载的模板文件。
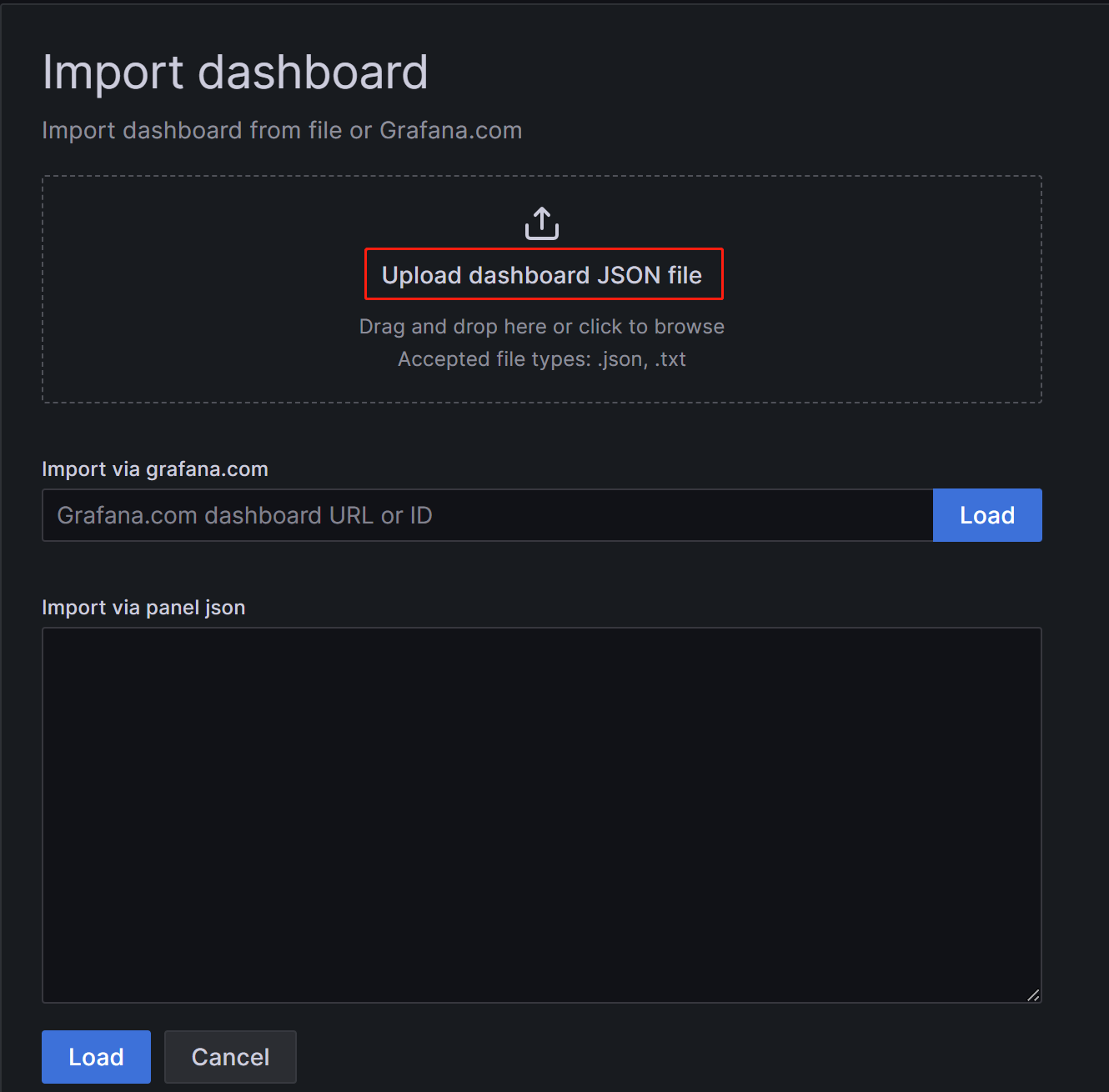
上传文件后,您可以重命名仪表盘。 默认情况下,它被命名为
StarRocks Overview。 然后,选择数据源,即您之前创建的数据源 (starrocks_monitor)。 然后,单击 Import。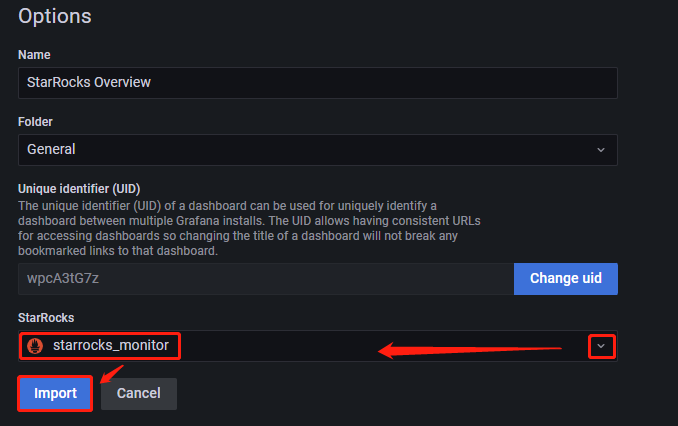
导入完成后,您应该会看到显示的 StarRocks 仪表盘。
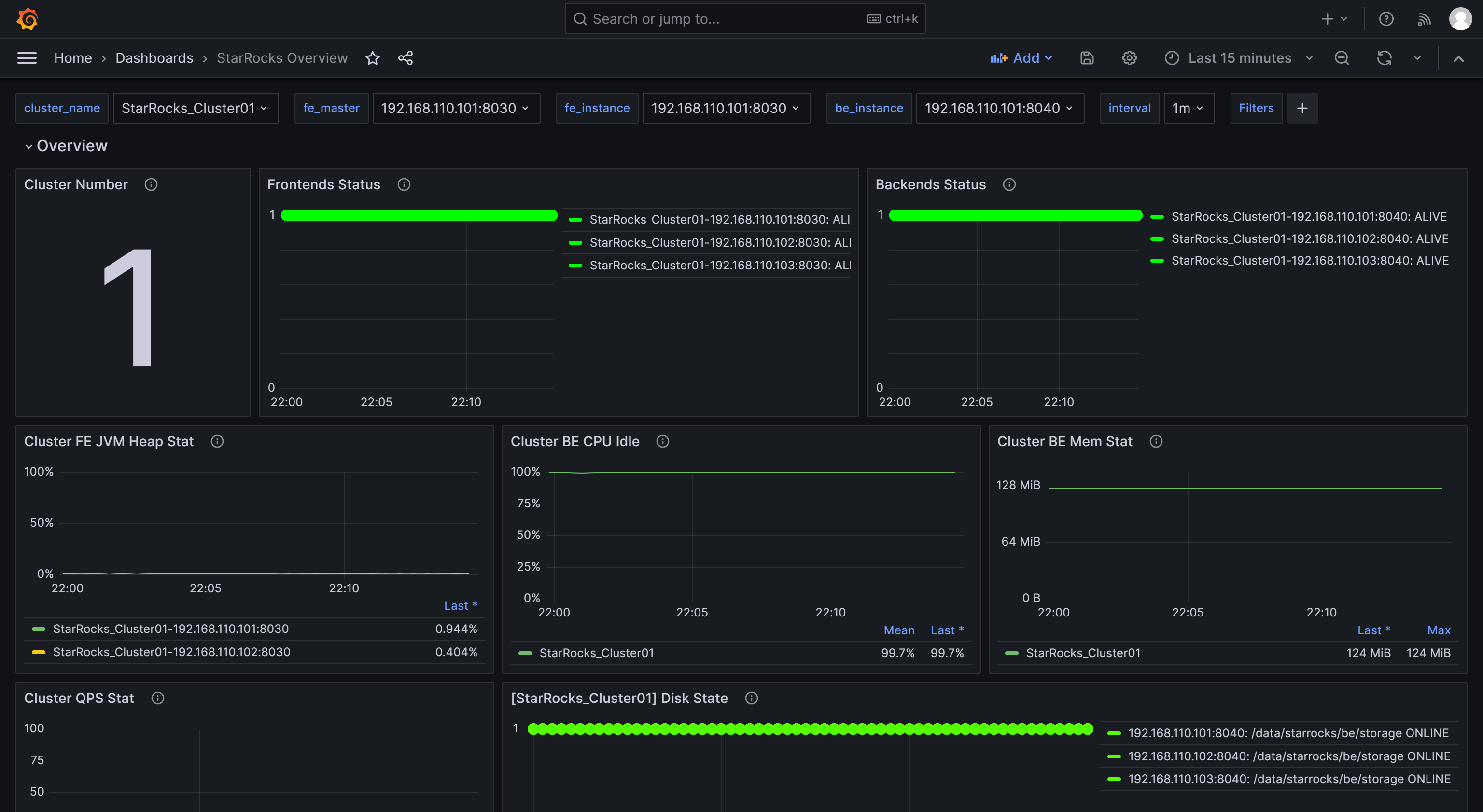
1.2.6 通过 Grafana 监控 StarRocks
登录到 Grafana Web UI,单击左上角的菜单按钮,然后单击 Dashboards。
在出现的页面上,从 General 目录中选择 StarRocks Overview。
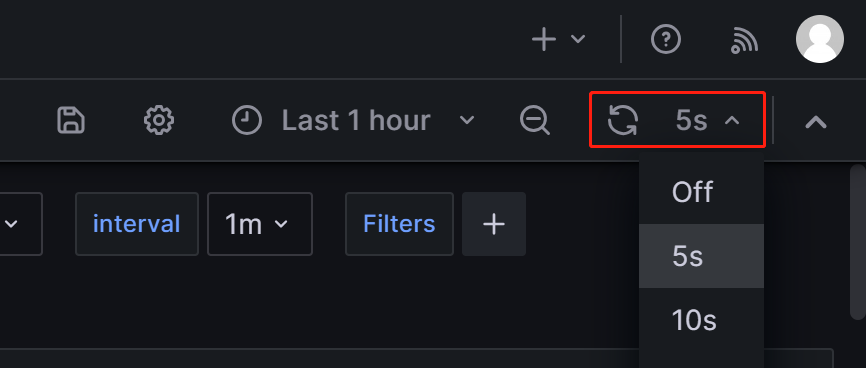
进入 StarRocks 监控仪表盘后,您可以手动刷新右上角的页面,或设置自动刷新间隔以监控 StarRocks 集群状态。
步骤 2:了解核心监控指标
为了满足开发、运维、DBA 等的需求,StarRocks 提供了广泛的监控指标。 本节仅介绍业务中常用的一些重要指标及其告警规则。 有关其他指标详细信息,请参阅 监控指标。
2.1 FE 和 BE 状态的指标
| 指标 | 描述 | 告警规则 | 注意 |
|---|---|---|---|
| 前端状态 | FE 节点状态。 活动节点的状态用 1 表示,而停机 (DEAD) 的节点将显示为 0。 | 所有 FE 节点的状态都应为活动状态,并且任何状态为 DEAD 的 FE 节点都应触发告警。 | 任何 FE 或 BE 节点的故障都被认为是关键的,需要及时进行故障排除以确定故障原因。 |
| 后端状态 | BE 节点状态。 活动节点的状态用 1 表示,而停机 (DEAD) 的节点将显示为 0。 | 所有 BE 节点的状态都应为活动状态,并且任何状态为 DEAD 的 BE 节点都应触发告警。 |
2.2 查询失败的指标
| 指标 | 描述 | 告警规则 | 注意 |
|---|---|---|---|
| 查询错误 | 一分钟内的查询失败(包括超时)率。 其值计算为一分钟内失败查询的次数除以 60 秒。 | 您可以根据业务的实际 QPS 配置此设置。 例如,0.05 可以用作初步设置。 您可以稍后根据需要进行调整。 | 通常,查询失败率应保持较低水平。 将此阈值设置为 0.05 意味着每分钟最多允许 3 个失败查询。 如果您收到来自此项目的告警,则可以检查资源利用率或适当地配置查询超时。 |
2.3 外部操作失败的指标
| 指标 | 描述 | 告警规则 | 注意 |
|---|---|---|---|
| Schema 更改 | Schema 更改操作失败率。 | Schema 更改是一种低频操作。 您可以设置此项以在失败时立即发送告警。 | 通常,Schema 更改操作不应失败。 如果为此项触发告警,您可以考虑增加 Schema 更改操作的内存限制,默认设置为 2GB。 |
2.4 内部操作失败的指标
| 指标 | 描述 | 告警规则 | 注意 |
|---|---|---|---|
| BE Compaction Score | 所有 BE 节点中的最高 Compaction Score,表示当前的 Compaction 压力。 | 在典型的离线场景中,此值通常低于 100。 但是,当存在大量加载任务时,Compaction Score 可能会显着增加。 在大多数情况下,当此值超过 800 时,需要进行干预。 | 通常,如果 Compaction Score 大于 1000,StarRocks 将返回错误“版本过多”。 在这种情况下,您可以考虑降低加载并发和频率。 |
| Clone | tablet clone 操作失败率。 | 您可以设置此项以在失败时立即发送告警。 | 如果为此项触发告警,您可以检查 BE 节点的状态、磁盘状态和网络状态。 |
2.5 服务可用性的指标
| 指标 | 描述 | 告警规则 | 注意 |
|---|---|---|---|
| Meta Log Count | FE 节点上的 BDB 元数据日志条目数。 | 建议配置此项,如果超过 100,000,则触发立即告警。 | 默认情况下,当日志数超过 50,000 时,leader FE 节点会触发一个检查点,将日志刷新到磁盘。 如果此值大幅超过 50,000,通常表示检查点失败。 您可以检查 fe.conf 中 Xmx 堆内存配置是否合理。 |
2.6 系统负载的指标
| 指标 | 描述 | 告警规则 | 注意 |
|---|---|---|---|
| BE CPU Idle | BE 节点的 CPU 空闲率。 | 建议配置此项,如果空闲率连续 30 秒低于 10%,则触发告警。 | 此项用于监控 CPU 资源瓶颈。 CPU 使用率可能会显着波动,设置较小的轮询间隔可能会导致误报。 因此,您需要根据实际业务情况调整此项。 如果您有多个批处理任务或大量查询,您可以考虑设置较低的阈值。 |
| BE Mem | BE 节点的内存使用量。 | 建议将此项配置为每个 BE 可用内存大小的 90%。 | 此值等效于 Process Mem 的值,BE 的默认内存限制是服务器内存大小的 90%(由 be.conf 中的配置 mem_limit 控制)。 如果您在同一服务器上部署了其他服务,请务必调整此值以避免 OOM。 此项的告警阈值应设置为 BE 实际内存限制的 90%,以便您可以确认 BE 内存资源是否已达到瓶颈。 |
| Disks Avail Capacity | 每个 BE 节点上本地磁盘的可用磁盘空间比率(百分比)。 | 建议配置此项,如果该值小于 20%,则触发告警。 | 建议根据您的业务需求为 StarRocks 保留足够的可用空间。 |
| FE JVM Heap Stat | 集群中每个 FE 节点的 JVM 堆内存使用率百分比。 | 建议配置此项,如果该值大于或等于 80%,则触发告警。 | 如果为此项触发告警,建议增加 fe.conf 中的 Xmx 堆内存配置; 否则,可能会影响查询效率或导致 FE OOM 问题。 |
步骤 3:通过电子邮件配置告警
3.1 配置 SMTP 服务
Grafana 支持各种告警解决方案,例如电子邮件和 Webhook。 本教程以电子邮件为例。
要启用电子邮件告警,您首先需要在 Grafana 中配置 SMTP 信息,以便 Grafana 可以向您的邮箱发送电子邮件。 最常用的电子邮件提供商支持 SMTP 服务,您需要为您的电子邮件帐户启用 SMTP 服务并获取授权码。
完成这些步骤后,修改部署 Grafana 的节点上的 Grafana 配置文件。
vim /usr/share/grafana/conf/defaults.ini
示例
###################### SMTP / Emailing #####################
[smtp]
enabled = true
host = <smtp_server_address_and_port>
user = johndoe@gmail.com
# If the password contains # or ; you have to wrap it with triple quotes.Ex """#password;"""
password = ABCDEFGHIJKLMNOP # The authorization password obtained after enabling SMTP.
cert_file =
key_file =
skip_verify = true ## Verify SSL for SMTP server
from_address = johndoe@gmail.com ## Address used when sending out emails.
from_name = Grafana
ehlo_identity =
startTLS_policy =
[emails]
welcome_email_on_sign_up = false
templates_pattern = emails/*.html, emails/*.txt
content_types = text/html
您需要修改以下配置项
enabled:是否允许 Grafana 发送电子邮件告警。 将此项设置为true。host:您的电子邮件的 SMTP 服务器地址和端口,以冒号 (:) 分隔。 示例:smtp.gmail.com:465。user:SMTP 用户名。password:启用 SMTP 后获得的授权密码。skip_verify:是否跳过 SMTP 服务器的 SSL 验证。 将此项设置为true。from_address:用于发送告警电子邮件的电子邮件地址。
配置完成后,重新启动 Grafana。
systemctl daemon-reload
systemctl restart grafana-server.service
3.2 创建告警渠道
您需要在 Grafana 中创建一个告警渠道(联系点),以指定在触发告警时如何通知联系人。
-
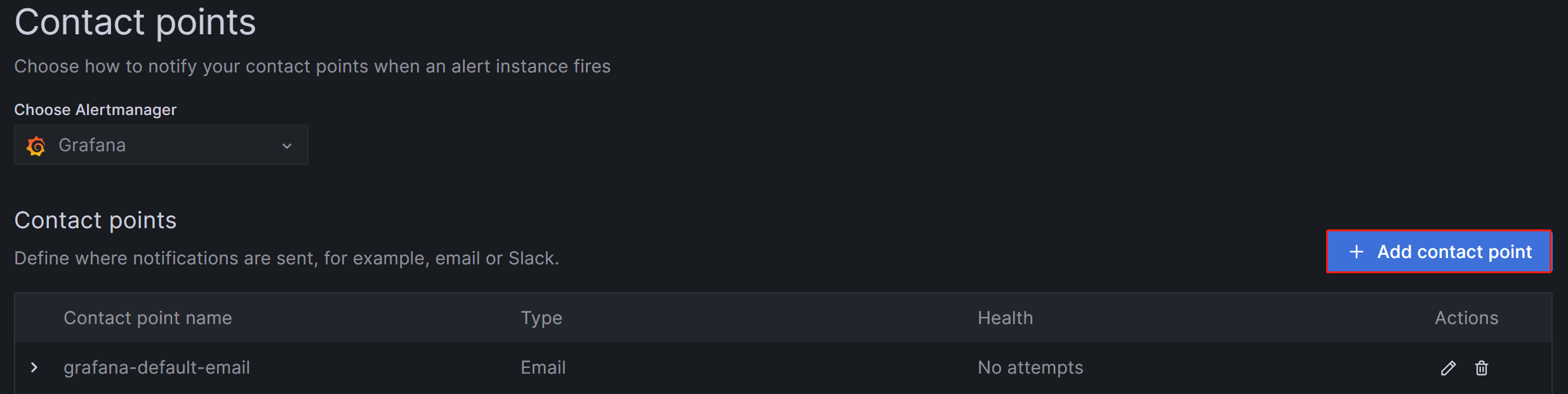
登录到 Grafana Web UI,单击左上角的菜单按钮,展开 Alerting,然后选择 Contact Points。 在 Contact points 页面上,单击 Add contact point 以创建新的告警渠道。
-
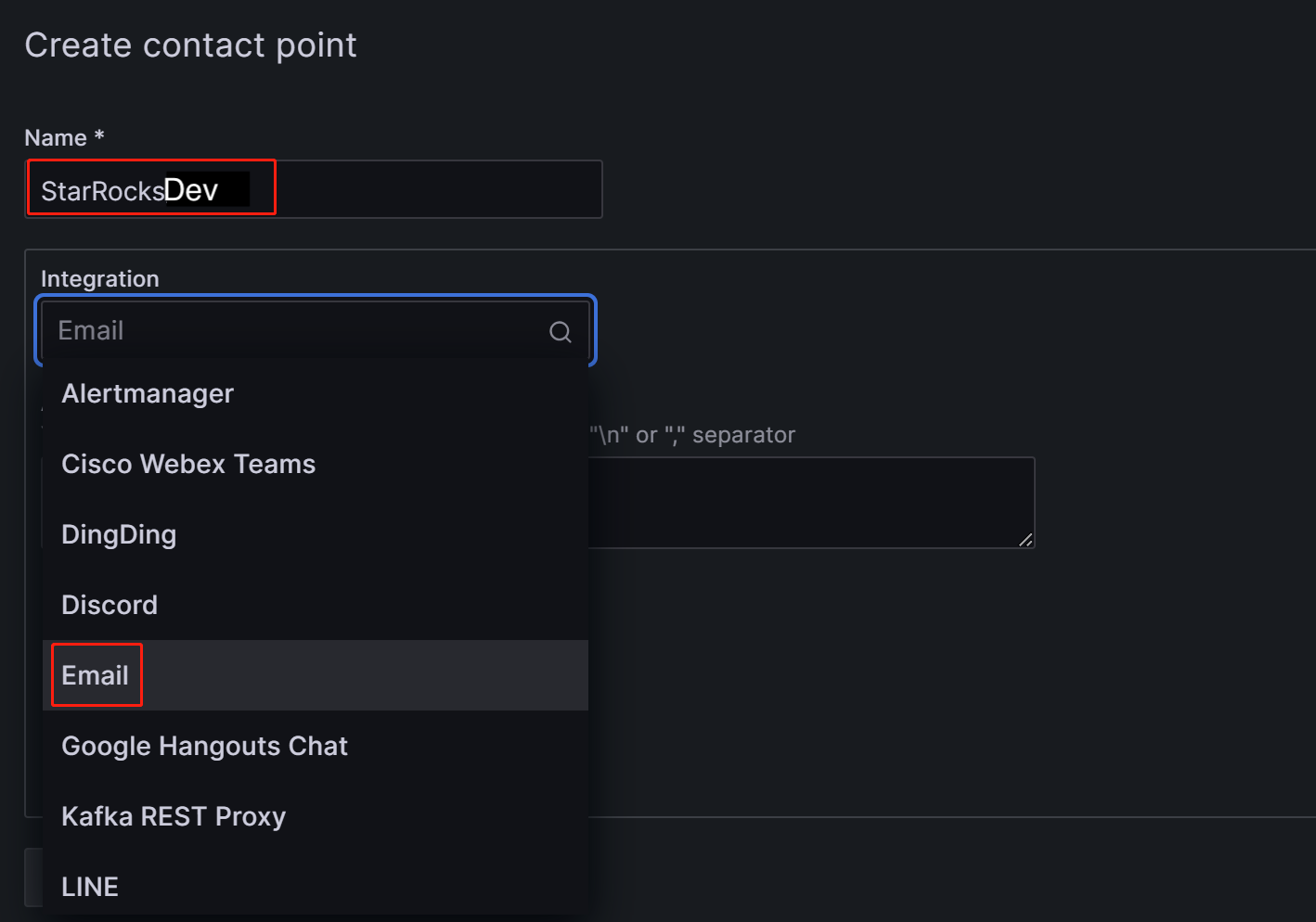
在 Name 字段中,自定义联系点的名称。 然后,在 Integration 下拉列表中,选择 Email。
-
在 Addresses 字段中,输入接收告警的联系人的电子邮件地址。 如果有多个电子邮件地址,请使用分号 (
;)、逗号 (,) 或换行符分隔地址。页面上的配置可以保留其默认值,但以下两项除外
- Single email:启用后,如果有多个联系人,告警将通过一封电子邮件发送给他们。 建议启用此项。
- Disable resolved message:默认情况下,当导致告警的问题得到解决时,Grafana 会发送另一个通知,通知服务已恢复。 如果您不需要此恢复通知,则可以禁用此项。 不建议禁用此选项。
-
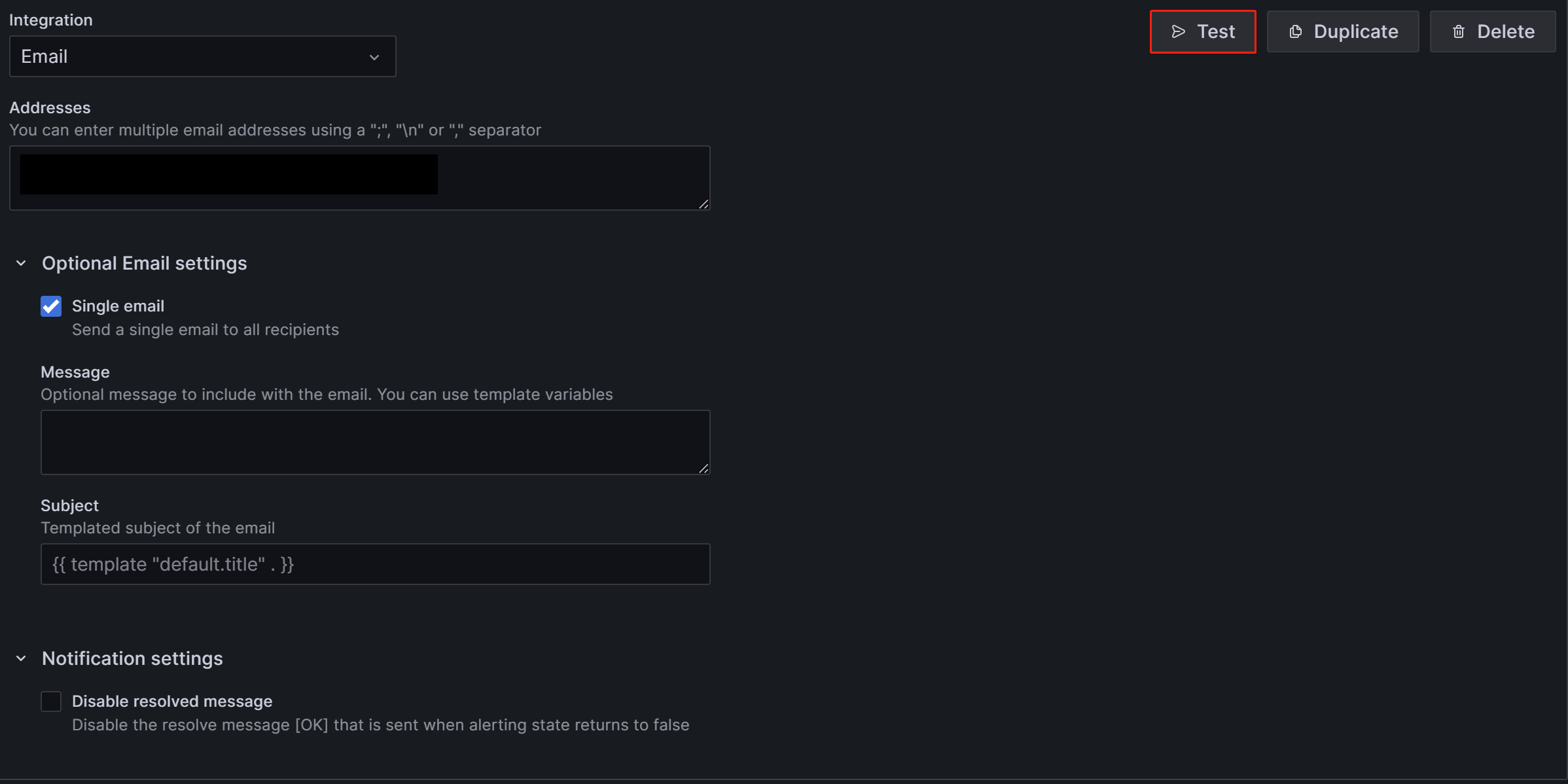
配置完成后,单击页面右上角的 Test 按钮。 在出现的提示中,单击 Sent test notification。 如果您的 SMTP 服务和地址配置正确,则目标电子邮件帐户应收到一封主题为“TestAlert Grafana”的测试电子邮件。 确认您可以成功收到测试告警电子邮件后,单击页面底部的 Save contact point 按钮以完成配置。
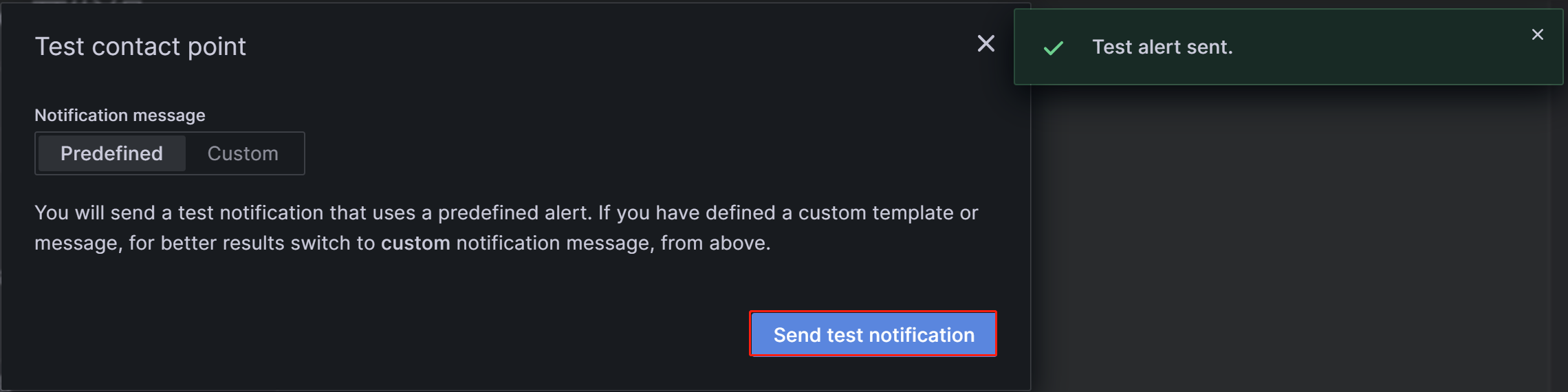
您可以通过“Add contact point integration”为每个联系点配置多种通知方法,此处不做详细介绍。 有关联系点的更多详细信息,您可以参考 Grafana 文档
对于后续演示,我们假设在此步骤中,您已使用不同的电子邮件地址创建了两个联系点“StarRocksDev”和“StarRocksOp”。
3.3 设置通知策略
Grafana 使用通知策略将联系点与告警规则相关联。 通知策略使用匹配标签来提供一种灵活的方式,将不同的告警路由到不同的联系人,从而允许在 O&M 期间进行告警分组。
-
登录到 Grafana Web UI,单击左上角的菜单按钮,展开 Alerting,然后选择 Notification policies。
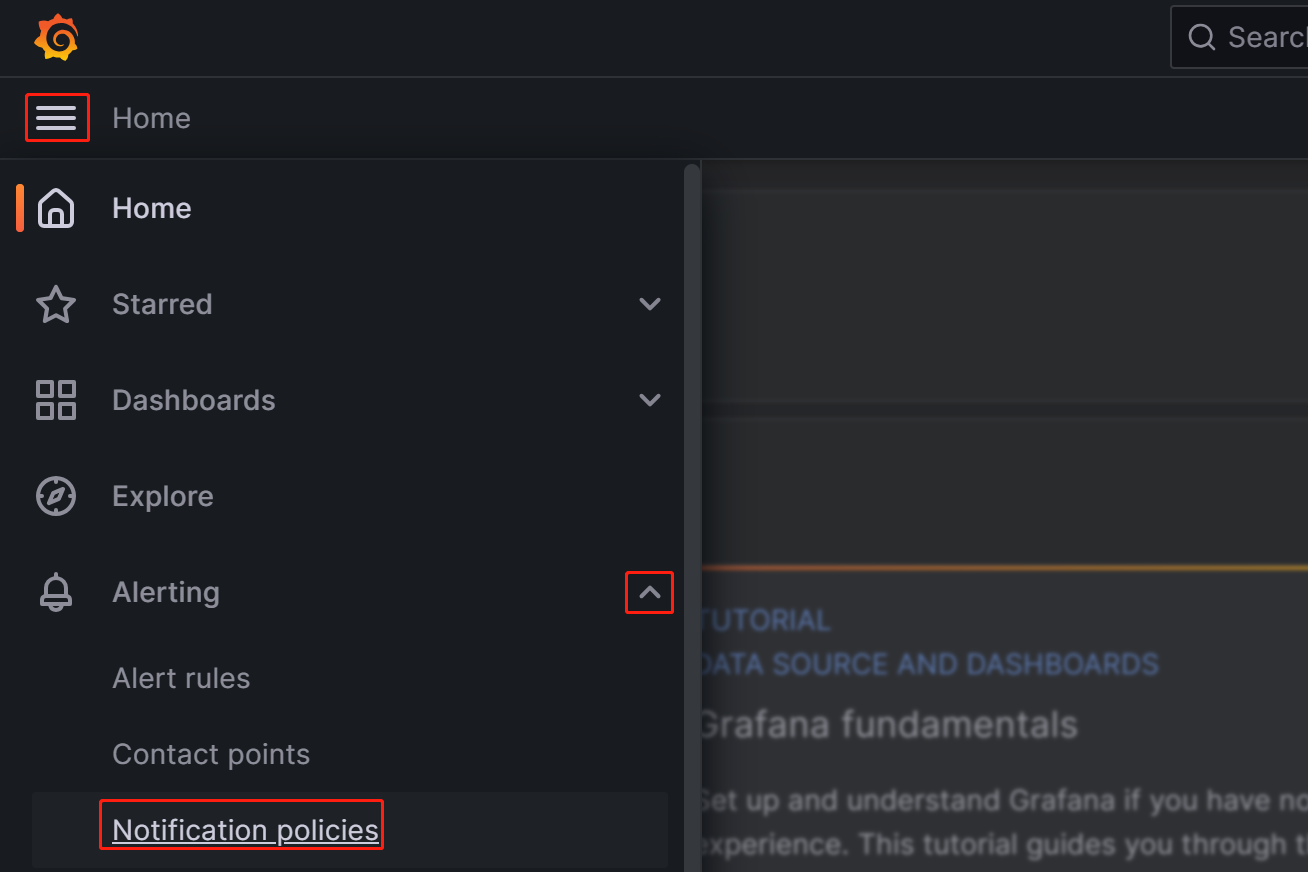
-
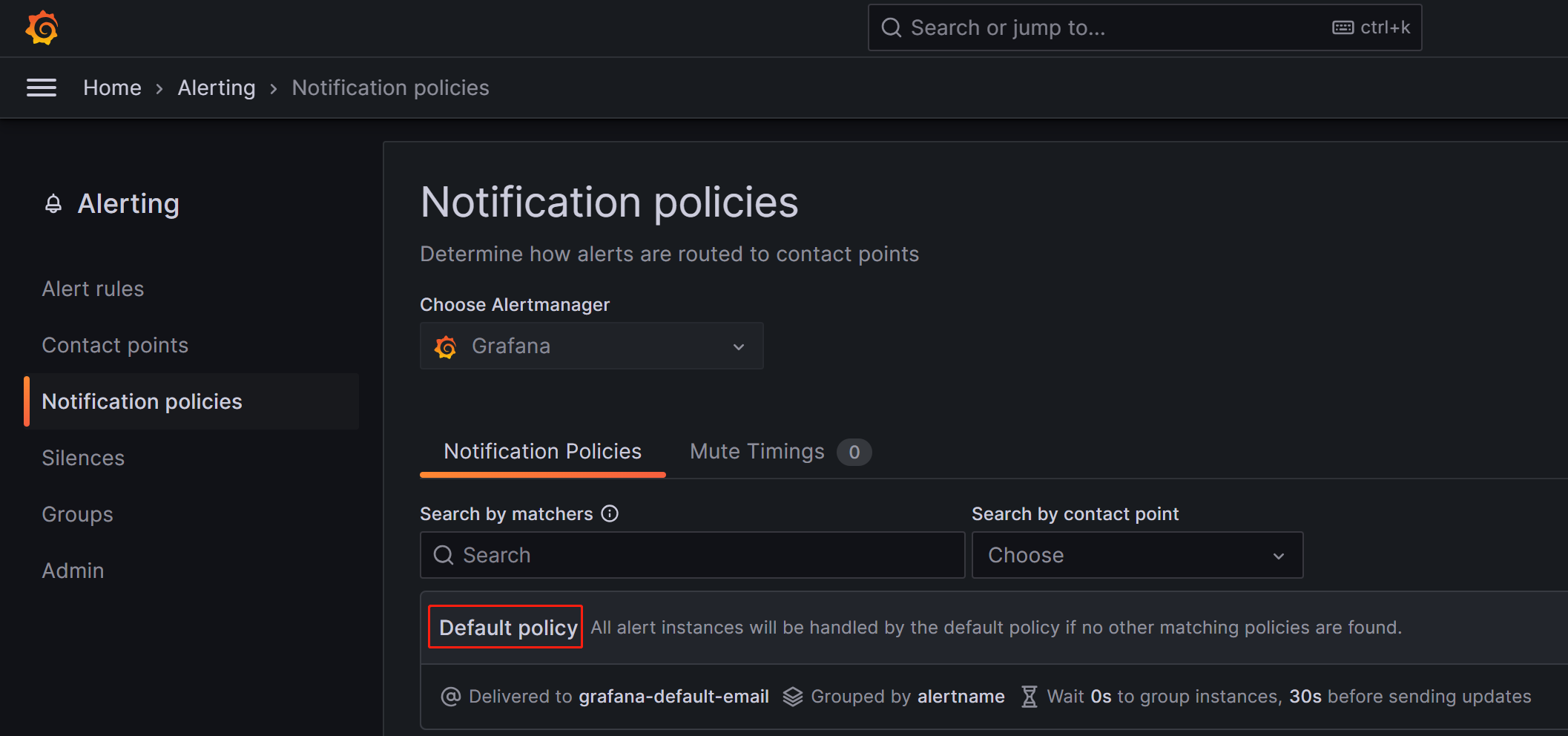
在 Notification policies 页面上,单击 Default policy 右侧的更多 (...) 图标,然后单击 Edit 以修改默认策略。
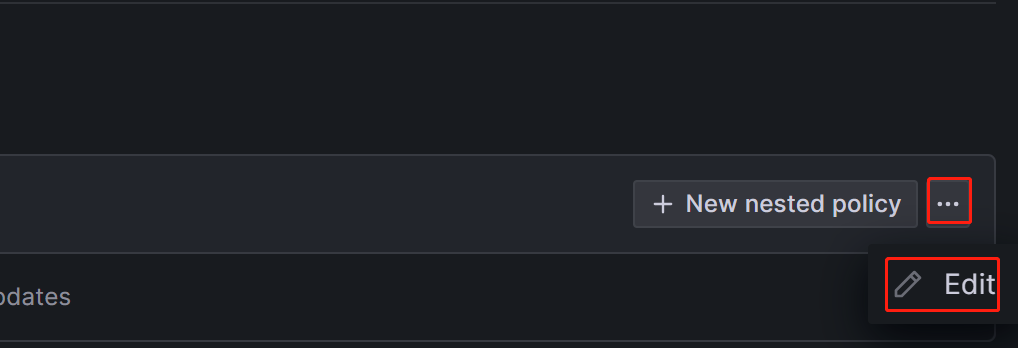
通知策略使用树状结构,默认策略表示通知的默认根策略。 当未设置其他策略时,所有告警规则将默认为匹配此策略。 然后,它将使用其中配置的默认联系点进行通知。
-
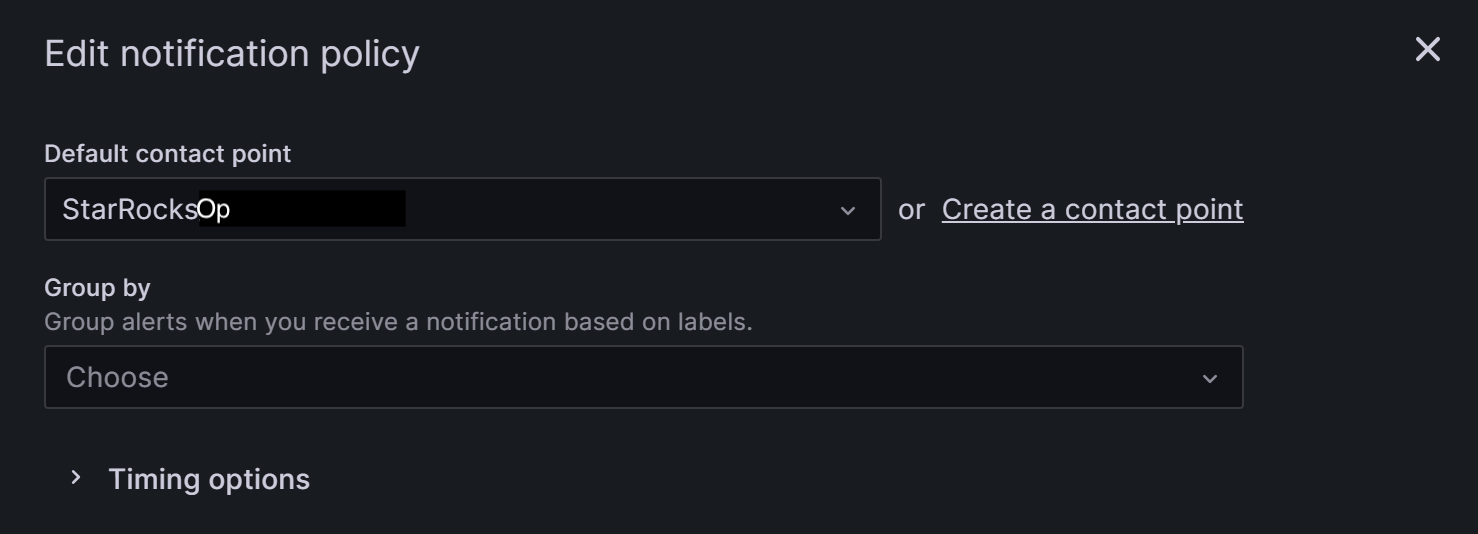
在 Default contact point 字段中,选择您之前创建的联系点,例如“StarRocksOp”。
-
Group by 是 Grafana Alerting 中的一个关键概念,它将具有相似特征的告警实例分组到一个漏斗中。 本教程不涉及分组,您可以使用默认设置。
-
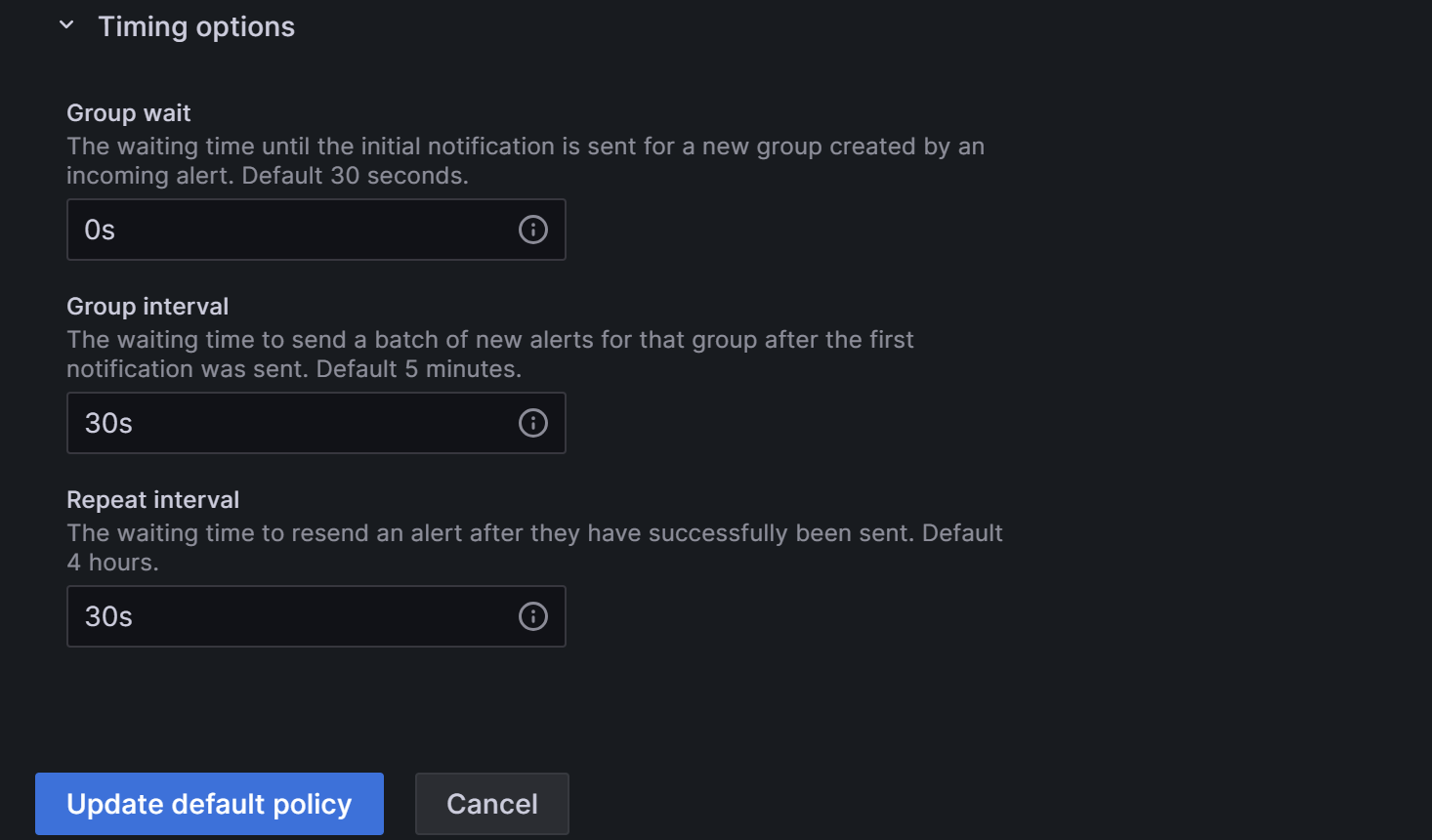
展开 Timing options 字段,然后配置 Group wait、Group interval 和 Repeat interval。
- Group wait:在新告警创建新组后,等待发送初始通知的时间。 默认为 30 秒。
- Group interval:现有组发送告警的间隔。 默认为 5 分钟,这意味着自上次发送告警以来,不会在 5 分钟之内向该组发送通知。 这意味着无论这些告警实例的告警规则间隔是否较低,都不会在自上次交付批量更新之后的 5 分钟(默认)之内发送通知。 默认为 5 分钟。
- Repeat interval:成功发送告警后重新发送告警的等待时间。 现有组发送告警的间隔。 默认为 5 分钟,这意味着自上次发送告警以来,不会在 5 分钟之内向该组发送通知。
您可以将参数配置为如下图所示,以便 Grafana 将按照以下规则发送告警:满足告警条件 后 0 秒(Group wait),Grafana 将发送第一封告警电子邮件。 之后,Grafana 将每 1 分钟重新发送告警(Group interval + Repeat interval)。
注意
前一段使用“满足告警条件”而不是“达到告警阈值”以避免误报。 建议将告警设置为在达到阈值后的一段时间内触发。
-
-
配置完成后,单击 Update default policy。
-
如果您需要创建嵌套策略,请单击 Notification policies 页面上的 New nested policy。
嵌套策略使用标签来定义匹配规则。 嵌套策略中定义的标签可以用作稍后配置告警规则时的匹配条件。 以下示例将标签配置为
Group=Development_team。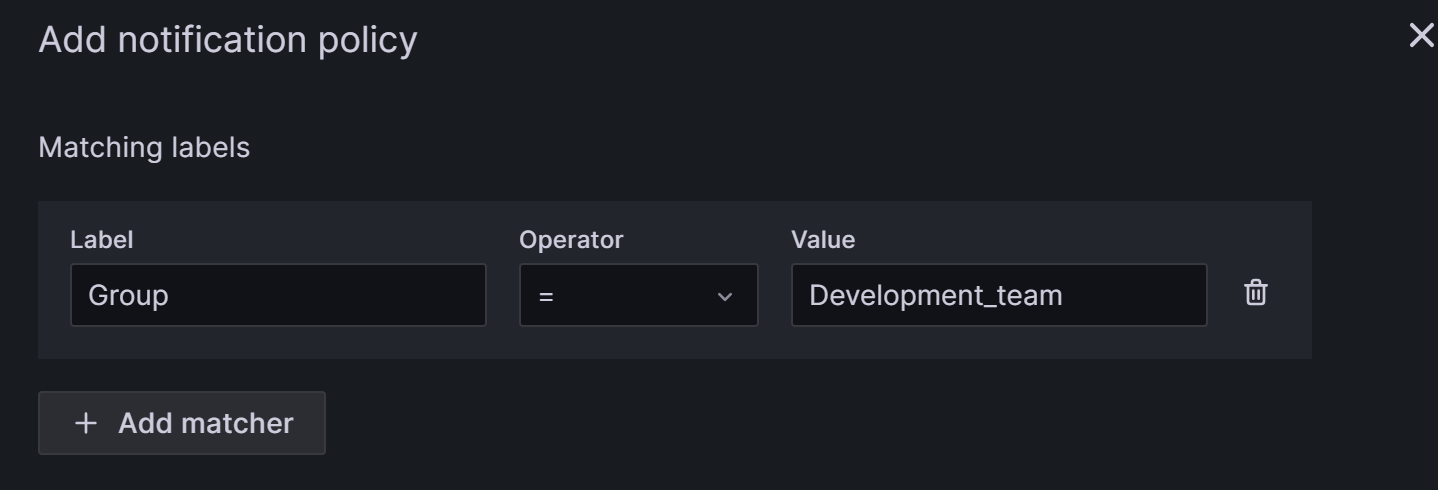
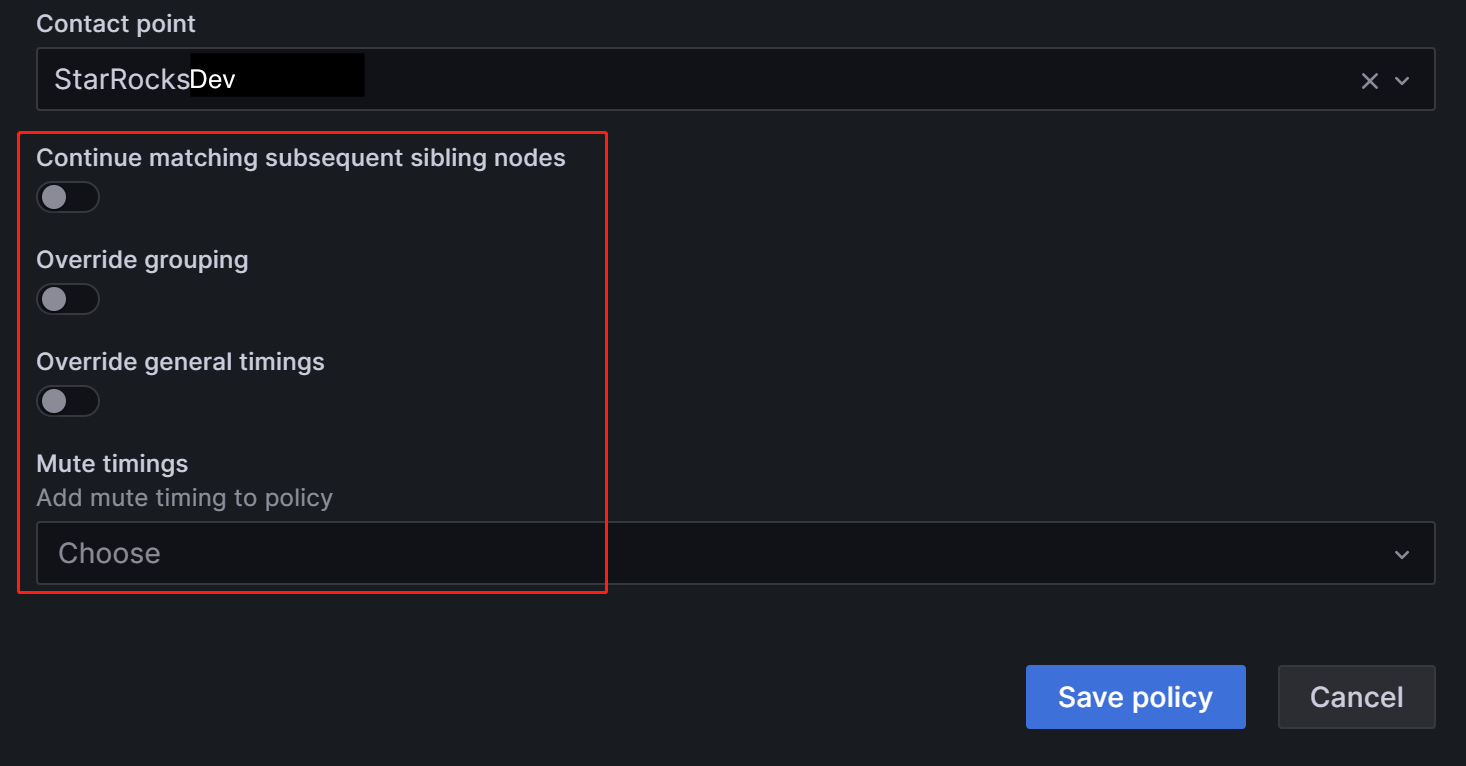
在 Contact point 字段中,选择“StarRocksDev”。 这样,当配置标签为
Group=Development_team的告警规则时,“StarRocksDev”设置为接收告警。您可以让嵌套策略继承父策略的时序选项。 配置完成后,单击 Save policy 以保存策略。
如果您对通知策略的详细信息感兴趣,或者您的业务有更复杂的告警场景,您可以参考 Grafana 文档 以获取更多信息。
3.4 定义告警规则
设置通知策略后,您还需要为 StarRocks 定义告警规则。
登录到 Grafana Web UI,搜索并导航到先前配置的 StarRocks Overview 仪表盘。

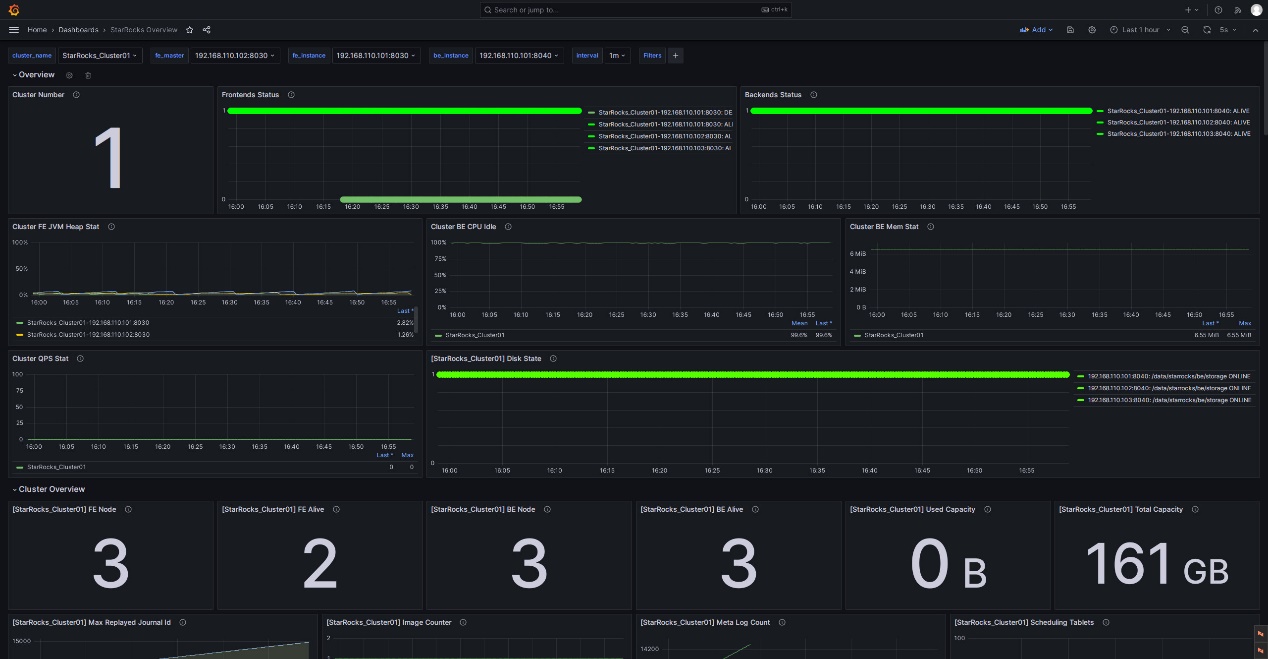
3.4.1 FE 和 BE 状态告警规则
对于 StarRocks 集群,所有 FE 和 BE 节点的状态必须为活动状态。 任何状态为 DEAD 的节点都应触发告警。
以下示例使用 StarRocks Overview 下的 Frontends Status 和 Backends Status 指标来监控 FE 和 BE 状态。 由于您可以在 Prometheus 中配置多个 StarRocks 集群,请注意 Frontends Status 和 Backends Status 指标适用于您已注册的所有集群。
配置 FE 的告警规则
请按照以下步骤配置 Frontends Status 的告警
-
单击 Frontends Status 监控项目右侧的更多 (...) 图标,然后单击 Edit。
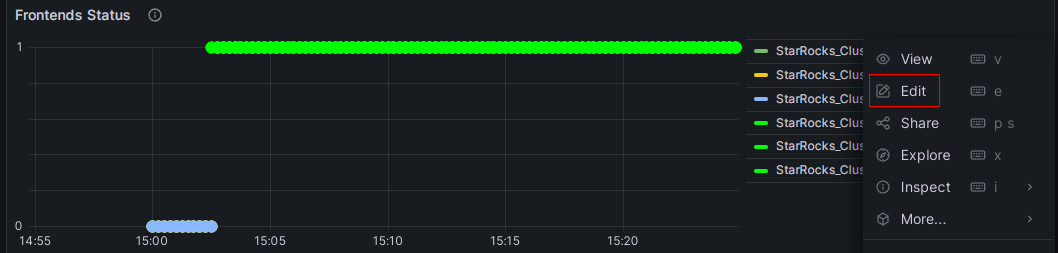
-
在新页面上,选择 Alert,然后单击此面板中的 Create alert rule 进入规则创建页面。
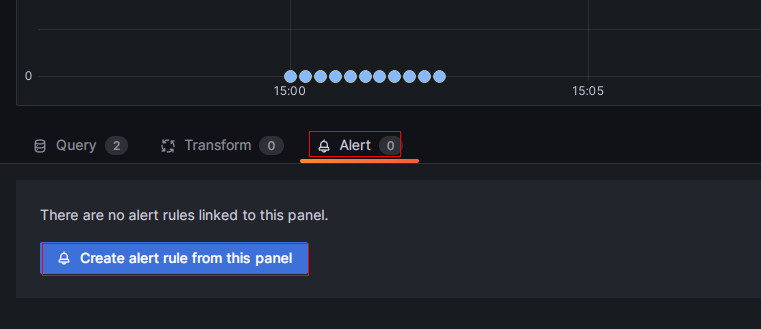
-
在 Rule name 字段中设置规则名称。 默认值为监控指标的标题。 如果您有多个集群,则可以添加集群名称作为前缀以进行区分,例如“[PROD]Frontends Status”。
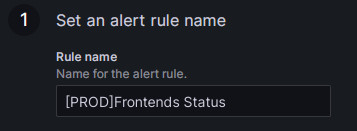
-
按如下方式配置告警规则。
- 选择 Grafana managed alert。
- 对于第 B 部分,将规则修改为
(up{group="fe"})。 - 单击第 A 部分右侧的删除图标以删除第 A 部分。
- 对于第 C 部分,将 Input 字段修改为 B。
- 对于第 D 部分,将条件修改为
IS BELOW 1。
完成这些设置后,页面将如下图所示
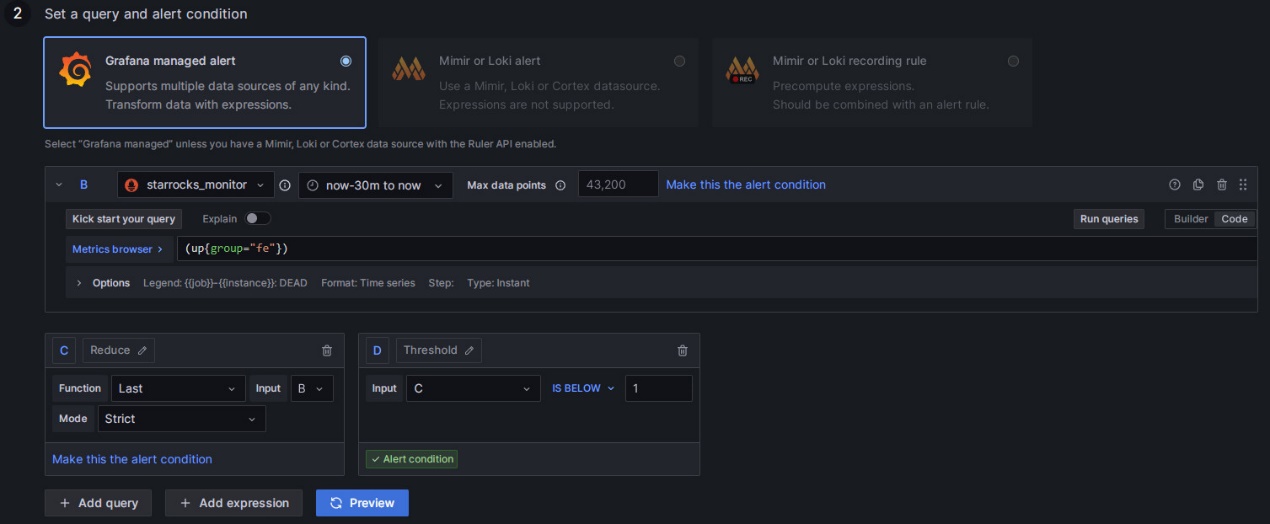
单击以查看详细说明
在 Grafana 中配置告警规则通常涉及三个步骤
- 通过 PromQL 查询从 Prometheus 检索指标值。PromQL 是 Prometheus 开发的一种数据查询 DSL 语言,也用于 Dashboard 的 JSON 模板中。每个监控项的
expr属性对应于各自的 PromQL。您可以点击规则设置页面上的运行查询来查看查询结果。 - 应用函数和模式来处理上述查询的结果数据。通常,您需要使用 Last 函数来检索最新值,并使用 Strict 模式来确保如果返回值是非数字数据,则可以显示为
NaN。 - 为处理后的查询结果设置规则。以 FE 为例,如果 FE 节点状态为 alive,则输出结果为
1。如果 FE 节点宕机,则结果为0。因此,您可以将规则设置为IS BELOW 1,这意味着当发生这种情况时将触发警报。
-
设置告警评估规则。
根据 Grafana 文档,您需要配置评估告警规则的频率以及其状态变化的频率。简单来说,这涉及配置“多久检查一次告警规则”以及“检测到异常状态后,异常状态必须持续多长时间才触发告警(以避免由瞬时峰值引起的误报)”。每个评估组包含一个独立的评估间隔,以确定检查告警规则的频率。您可以专门为 StarRocks 生产集群创建一个名为 PROD 的新文件夹,并在其中创建一个新的评估组
01。然后,将此组配置为每10秒检查一次,如果异常持续30秒则触发警报。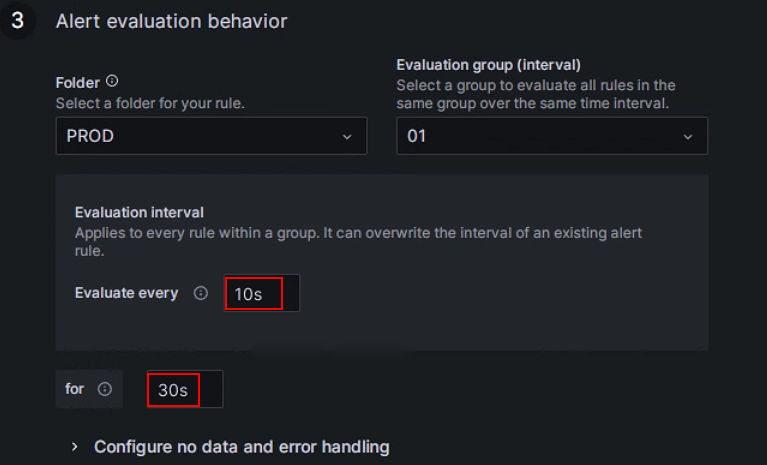
注意
前面提到的告警通道配置部分中的“禁用已解决消息”选项,它控制集群服务恢复时发送电子邮件的时间,也受到上述“Evaluate every”参数的影响。换句话说,当 Grafana 执行新的检查并检测到服务已恢复时,它会发送电子邮件通知联系人。
-
添加告警注解。
在为您的告警规则添加详细信息部分中,点击添加注解以配置告警电子邮件的内容。请注意不要修改 Dashboard UID 和 Panel ID 字段。
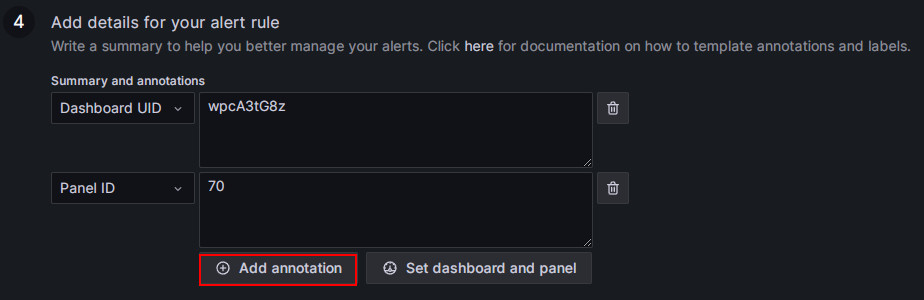
在选择下拉列表中,选择描述,并添加告警电子邮件的描述性内容,例如“您的 StarRocks 生产集群中的 FE 节点失败,请检查!”
-
匹配通知策略。
指定告警规则的通知策略。默认情况下,所有告警规则都匹配 Default 策略。当满足告警条件时,Grafana 将使用 Default 策略中的“StarRocksOp”联系点将告警消息发送到配置的电子邮件组。
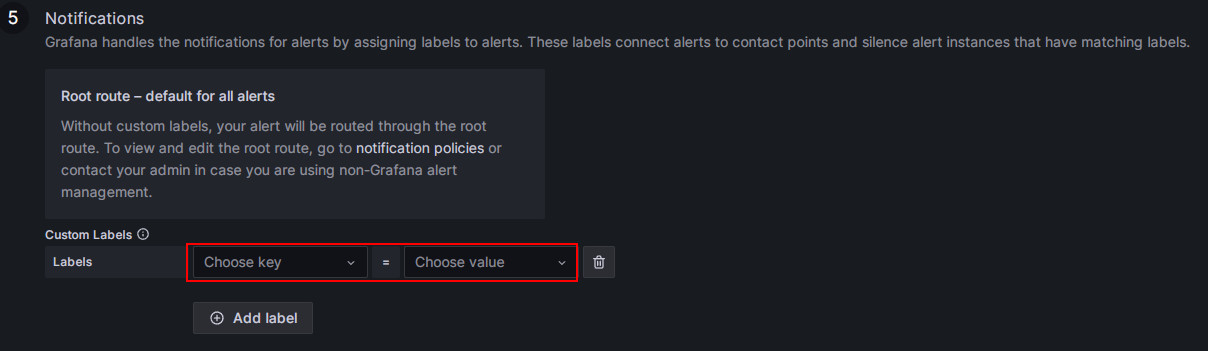
如果要使用嵌套策略,请将 Label 字段设置为相应的嵌套策略,例如
Group=Development_team。示例

当满足告警条件时,电子邮件将发送到“StarRocksDev”而不是 Default 策略中的“StarRocksOp”。
-
完成所有配置后,点击保存规则并退出。

测试告警触发
您可以手动停止一个 FE 节点来测试告警。此时,Frontends Status 右侧的心形符号将从绿色变为黄色,然后变为红色。
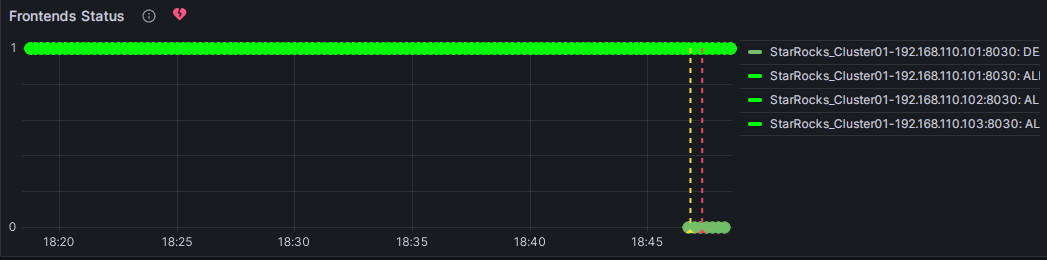
绿色:表示在上次定期检查期间,指标项的每个实例的状态都是正常的,并且没有触发告警。绿色状态不能保证当前节点处于正常状态。节点服务异常后,状态变化可能会有延迟,但通常情况下,延迟不会以分钟为单位。
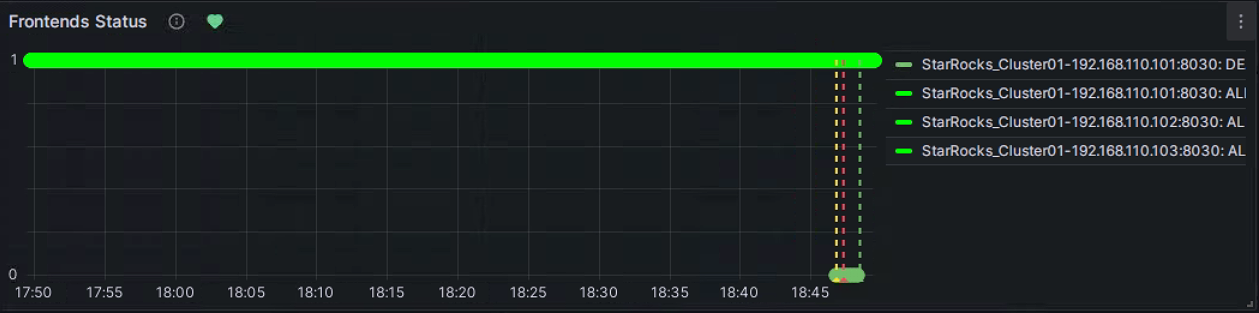
黄色:表示在上次定期检查期间,发现指标项的某个实例异常,但异常状态持续时间尚未达到上面配置的“Duration”。此时,Grafana 不会发送告警,并将继续定期检查,直到异常状态持续时间达到配置的“Duration”。在此期间,如果状态恢复,符号将变回绿色。
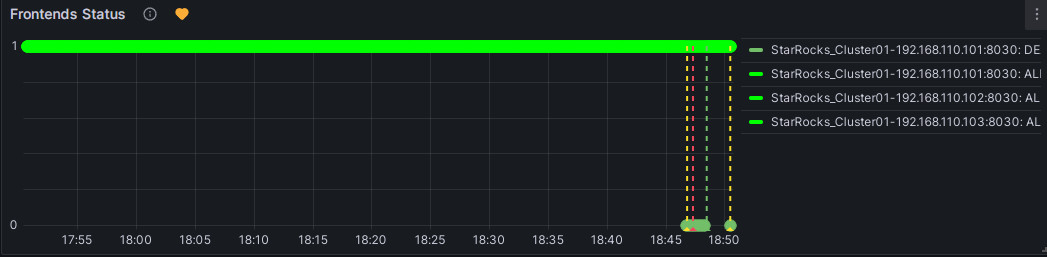
红色:当异常状态持续时间达到配置的“Duration”时,符号变为红色,Grafana 将发送电子邮件告警。该符号将保持红色,直到异常状态解决,届时它将变回绿色。
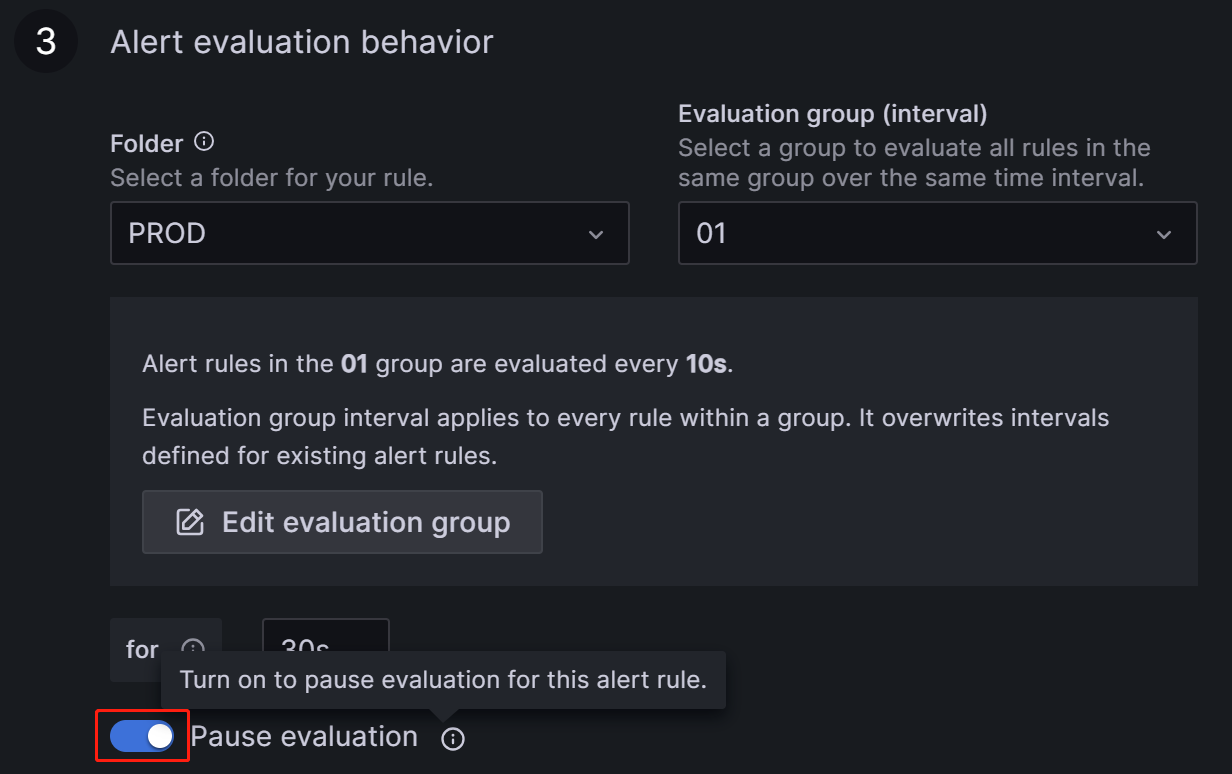
手动暂停告警
假设异常需要很长时间才能解决,或者由于异常以外的某些原因不断触发告警。您可以暂时暂停评估告警规则,以防止 Grafana 持续发送告警电子邮件。
导航到 Dashboard 上与指标项对应的 Alert 选项卡,然后点击编辑图标
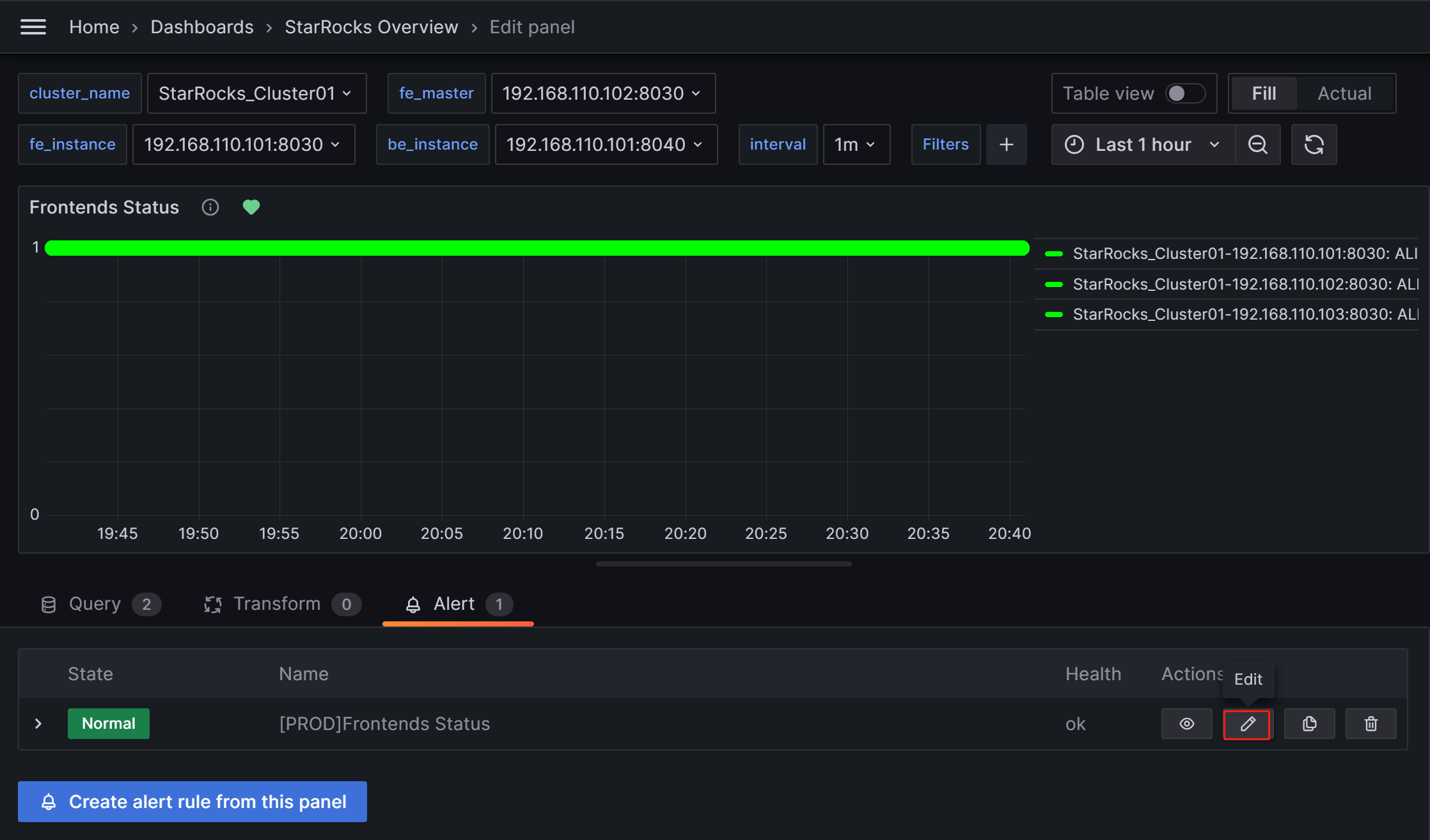
在告警评估行为部分中,将暂停评估开关切换到 ON 位置。
注意
暂停评估后,您将收到一封电子邮件,通知您服务已恢复。
配置 BE 的告警规则
您可以按照上述流程配置 BE 的告警规则。
编辑指标项 Backends Status 的配置
- 在设置告警规则名称部分中,将名称配置为“[PROD]Backends Status”。
- 在设置查询和告警条件部分中,将 PromSQL 设置为
(up{group="be"}),并对其他项目使用与 FE 告警规则中相同的设置。 - 在告警评估行为部分中,选择之前创建的 PROD 目录和评估组 01,并将持续时间设置为 30 秒。
- 在为您的告警规则添加详细信息部分中,点击添加注解,选择描述,并输入告警内容,例如“您的 StarRocks 生产集群中的 BE 节点失败,请检查!BE 故障的堆栈信息将打印在 BE 日志文件 be.out 中。您可以根据日志识别原因”。
- 在通知部分中,将 Labels 配置为与 FE 告警规则相同。如果未配置 Labels,Grafana 将使用 Default 策略并将告警电子邮件发送到“StarRocksOp”告警通道。
3.4.2 查询告警规则
查询失败的指标项是 Query Statistic 下的 Query Error。
按如下方式配置指标项“Query Error”的告警规则
- 在设置告警规则名称部分中,将名称配置为“[PROD] Query Error”。
- 在设置查询和告警条件部分中,移除 B 部分。将 A 部分中的 Input 设置为 C。在 C 部分中,使用 PromQL 的默认值,即
rate(starrocks_fe_query_err{job="StarRocks_Cluster01"}[1m]),表示每分钟失败的查询数除以 60 秒。这包括失败的查询和超过超时限制的查询。然后,在 D 部分中,将规则配置为A IS ABOVE 0.05。 - 在告警评估行为部分中,选择之前创建的 PROD 目录和评估组 01,并将持续时间设置为 30 秒。
- 在为您的告警规则添加详细信息部分中,点击添加注解,选择描述,并输入告警内容,例如“查询失败率高,请检查资源使用情况或合理配置查询超时。如果查询因超时而失败,您可以通过设置系统变量
query_timeout来调整查询超时”。 - 在通知部分中,将 Labels 配置为与 FE 告警规则相同。如果未配置 Labels,Grafana 将使用 Default 策略并将告警电子邮件发送到“StarRocksOp”告警通道。
3.4.3 用户操作失败告警规则
此项目监控 Schema Change 操作失败的速率,对应于 BE tasks 下的指标项 Schema Change。它应该配置为在大于 0 时发出警报。
- 在设置告警规则名称部分中,将名称配置为“[PROD] Schema Change”。
- 在设置查询和告警条件部分中,移除 A 部分。将 C 部分中的 Input 设置为 B。在 B 部分中,使用 PromQL 的默认值,即
irate(starrocks_be_engine_requests_total{job="StarRocks_Cluster01", type="create_rollup", status="failed"}[1m]),表示每分钟失败的 Schema Change 任务数除以 60 秒。然后,在 D 部分中,将规则配置为C IS ABOVE 0。 - 在告警评估行为部分中,选择之前创建的 PROD 目录和评估组 01,并将持续时间设置为 30 秒。
- 在为您的告警规则添加详细信息部分中,点击添加注解,选择描述,并输入告警内容,例如“检测到失败的 Schema Change 任务,请及时检查。您可以通过调整 BE 配置参数
memory_limitation_per_thread_for_schema_change来增加 Schema Change 可用的内存限制,默认设置为 2GB”。 - 在通知部分中,将 Labels 配置为与 FE 告警规则相同。如果未配置 Labels,Grafana 将使用 Default 策略并将告警电子邮件发送到“StarRocksOp”告警通道。
3.4.4 StarRocks 操作失败告警规则
BE Compaction Score
此项目对应于 Cluster Overview 下的 BE Compaction Score,用于监控集群上的 Compaction 压力。
- 在设置告警规则名称部分中,将名称配置为“[PROD] BE Compaction Score”。
- 在设置查询和告警条件部分中,将 C 部分中的规则配置为
B IS ABOVE 0。您可以对其他项目使用默认值。 - 在告警评估行为部分中,选择之前创建的 PROD 目录和评估组 01,并将持续时间设置为 30 秒。
- 在为您的告警规则添加详细信息部分中,点击添加注解,选择描述,并输入告警内容,例如“Compaction 压力高。请检查是否存在高频率或高并发的加载任务,并降低加载频率。如果集群有足够的 CPU、内存和 I/O 资源,请考虑调整集群 Compaction 策略”。
- 在通知部分中,将 Labels 配置为与 FE 告警规则相同。如果未配置 Labels,Grafana 将使用 Default 策略并将告警电子邮件发送到“StarRocksOp”告警通道。
Clone
此项目对应于 BE tasks 中的 Clone,主要用于监控 StarRocks 内的副本平衡或副本修复操作,通常不应失败。
- 在设置告警规则名称部分中,将名称配置为“[PROD] Clone”。
- 在设置查询和告警条件部分中,移除 A 部分。将 C 部分中的 Input 设置为 B。在 B 部分中,使用 PromQL 的默认值,即
irate(starrocks_be_engine_requests_total{job="StarRocks_Cluster01", type="clone", status="failed"}[1m]),表示每分钟失败的 Clone 任务数除以 60 秒。然后,在 D 部分中,将规则配置为C IS ABOVE 0。 - 在告警评估行为部分中,选择之前创建的 PROD 目录和评估组 01,并将持续时间设置为 30 秒。
- 在为您的告警规则添加详细信息部分中,点击添加注解,选择描述,并输入告警内容,例如“检测到 Clone 任务失败。请检查集群 BE 状态、磁盘状态和网络状态”。
- 在通知部分中,将 Labels 配置为与 FE 告警规则相同。如果未配置 Labels,Grafana 将使用 Default 策略并将告警电子邮件发送到“StarRocksOp”告警通道。
3.4.5 服务可用性告警规则
此项目监控 BDB 中的元数据日志计数,对应于 Cluster Overview 下的 Meta Log Count 监控项。
- 在设置告警规则名称部分中,将名称配置为“[PROD] Meta Log Count”。
- 在设置查询和告警条件部分中,将 C 部分中的规则配置为
B IS ABOVE 100000。您可以对其他项目使用默认值。 - 在告警评估行为部分中,选择之前创建的 PROD 目录和评估组 01,并将持续时间设置为 30 秒。
- 在为您的告警规则添加详细信息部分中,点击添加注解,选择描述,并输入告警内容,例如“检测到 FE BDB 中的元数据计数远高于预期值,这可能表明 Checkpoint 操作失败。请检查 FE 配置文件 fe.conf 中的 Xmx 堆内存配置是否合理”。
- 在通知部分中,将 Labels 配置为与 FE 告警规则相同。如果未配置 Labels,Grafana 将使用 Default 策略并将告警电子邮件发送到“StarRocksOp”告警通道。
3.4.6 系统过载告警规则
BE CPU Idle
此项目监控 BE 节点上的 CPU 空闲率。
- 在设置告警规则名称部分中,将名称配置为“[PROD] BE CPU Idle”。
- 在设置查询和告警条件部分中,将 C 部分中的规则配置为
B IS BELOW 10。您可以对其他项目使用默认值。 - 在告警评估行为部分中,选择之前创建的 PROD 目录和评估组 01,并将持续时间设置为 30 秒。
- 在为您的告警规则添加详细信息部分中,点击添加注解,选择描述,并输入告警内容,例如“检测到 BE CPU 负载持续较高。这将影响集群中的其他任务。请检查集群是否异常,或者是否存在 CPU 资源瓶颈”。
- 在通知部分中,将 Labels 配置为与 FE 告警规则相同。如果未配置 Labels,Grafana 将使用 Default 策略并将告警电子邮件发送到“StarRocksOp”告警通道。
BE Memory
此项目对应于 BE 下的 BE Mem,监控 BE 节点上的内存使用情况。
- 在设置告警规则名称部分中,将名称配置为“[PROD] BE Mem”。
- 在设置查询和告警条件部分中,将 PromSQL 配置为
starrocks_be_process_mem_bytes{job="StarRocks_Cluster01"}/(<be_mem_limit>*1024*1024*1024),其中<be_mem_limit>需要替换为当前 BE 节点的可用内存限制,即服务器的内存大小乘以 BE 配置项mem_limit的值。示例:starrocks_be_process_mem_bytes{job="StarRocks_Cluster01"}/(49*1024*1024*1024)。然后,在 C 部分中,将规则配置为B IS ABOVE 0.9。 - 在告警评估行为部分中,选择之前创建的 PROD 目录和评估组 01,并将持续时间设置为 30 秒。
- 在为您的告警规则添加详细信息部分中,点击添加注解,选择描述,并输入告警内容,例如“检测到 BE 内存使用率持续较高。为防止查询失败,请考虑扩大内存大小或添加 BE 节点”。
- 在通知部分中,将 Labels 配置为与 FE 告警规则相同。如果未配置 Labels,Grafana 将使用 Default 策略并将告警电子邮件发送到“StarRocksOp”告警通道。
Disks Avail Capacity
此项目对应于 BE 下的 Disk Usage,监控 BE 存储路径所在目录中的剩余空间比率。
- 在设置告警规则名称部分中,将名称配置为“[PROD] Disks Avail Capacity”。
- 在设置查询和告警条件部分中,将 C 部分中的规则配置为
B IS BELOW 0.2。您可以对其他项目使用默认值。 - 在告警评估行为部分中,选择之前创建的 PROD 目录和评估组 01,并将持续时间设置为 30 秒。
- 在为您的告警规则添加详细信息部分中,点击添加注解,选择描述,并输入告警内容,例如“检测到 BE 磁盘可用空间低于 20%,请释放磁盘空间或扩展磁盘”。
- 在通知部分中,将 Labels 配置为与 FE 告警规则相同。如果未配置 Labels,Grafana 将使用 Default 策略并将告警电子邮件发送到“StarRocksOp”告警通道。
FE JVM Heap Stat
此项目对应于 Overview 下的 Cluster FE JVM Heap Stat,监控 FE 的 JVM 内存使用量与 FE 堆内存限制的比例。
- 在设置告警规则名称部分中,将名称配置为“[PROD] FE JVM Heap Stat”。
- 在设置查询和告警条件部分中,将 C 部分中的规则配置为
B IS ABOVE 80。您可以对其他项目使用默认值。 - 在告警评估行为部分中,选择之前创建的 PROD 目录和评估组 01,并将持续时间设置为 30 秒。
- 在为您的告警规则添加详细信息部分中,点击添加注解,选择描述,并输入告警内容,例如“检测到 FE 堆内存使用率较高,请调整 FE 配置文件 fe.conf 中的堆内存限制”。
- 在通知部分中,将 Labels 配置为与 FE 告警规则相同。如果未配置 Labels,Grafana 将使用 Default 策略并将告警电子邮件发送到“StarRocksOp”告警通道。
Q&A
Q:为什么 Dashboard 无法检测到异常?
A:Grafana Dashboard 依赖于其托管服务器的系统时间来获取监控项的值。如果在集群异常后 Grafana Dashboard 页面保持不变,您可以检查服务器的系统时钟是否同步,然后执行集群时间校准。
Q:如何实现告警分级?
A:以 Query Error 项为例,您可以为其创建两个具有不同告警阈值的告警规则。例如
- 风险级别:将失败率设置为大于 0.05,表示存在风险。将告警发送给开发团队。
- 严重级别:将失败率设置为大于 0.20,表示严重性。此时,告警通知将同时发送给开发和运维团队。