自动集群快照
本主题介绍如何在共享数据集群上自动执行集群快照以进行灾难恢复。
此功能从 v3.4.2 开始支持,并且仅在共享数据集群上可用。
概述
共享数据集群灾难恢复的基本思想是确保完整的集群状态(包括数据和元数据)存储在对象存储中。 这样,如果集群遇到故障,只要数据和元数据保持完好,就可以从对象存储中恢复。 此外,云提供商提供的备份和跨区域复制等功能可用于实现远程恢复和跨区域灾难恢复。
在共享数据集群中,CN 状态(数据)存储在对象存储中,但 FE 状态(元数据)仍然是本地的。 为了确保对象存储具有用于恢复的所有集群状态,StarRocks 现在支持对象存储中数据和元数据的自动集群快照。
工作流程
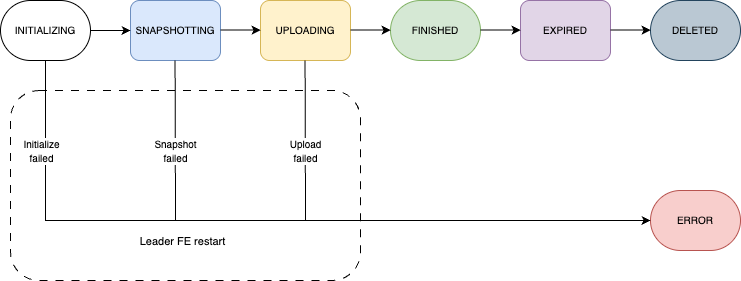
术语
-
集群快照
集群快照是指集群在某个时刻的状态快照。 它包含集群中的所有对象,例如目录、数据库、表、用户和权限、加载任务等。 它不包括所有外部依赖对象,例如外部目录的配置文件和本地 UDF JAR 包。
-
自动集群快照
系统自动维护紧随最新集群状态之后的快照。 历史快照将在创建最新快照后立即删除,始终只保留一个快照可用。 目前,用于自动化集群快照的任务仅由系统触发。 不支持手动创建快照。
-
集群恢复
从快照恢复集群。
用法
启用自动集群快照
默认情况下禁用自动集群快照。
使用以下语句启用此功能
语法
ADMIN SET AUTOMATED CLUSTER SNAPSHOT ON
[STORAGE VOLUME <storage_volume_name>]
参数
storage_volume_name:指定用于存储快照的存储卷。 如果未指定此参数,将使用默认存储卷。 有关创建存储卷的详细信息,请参阅CREATE STORAGE VOLUME。
每次 FE 在完成元数据检查点后创建新的元数据镜像时,它都会自动创建一个快照。 快照的名称由系统生成,格式为 automated_cluster_snapshot_{timestamp}。
元数据快照存储在 /{storage_volume_locations}/{service_id}/meta/image/automated_cluster_snapshot_timestamp 下。 数据快照存储在与原始数据相同的位置。
FE 配置项 automated_cluster_snapshot_interval_seconds 控制快照自动化周期。 默认值为 600 秒(10 分钟)。
禁用自动集群快照
使用以下语句禁用自动集群快照
ADMIN SET AUTOMATED CLUSTER SNAPSHOT OFF
禁用自动集群快照后,系统将自动清除历史快照。
查看集群快照
您可以查询视图 information_schema.cluster_snapshots 以查看最新的集群快照和尚未删除的快照。
SELECT * FROM information_schema.cluster_snapshots;
返回
| 字段 | 描述 |
|---|---|
| snapshot_name | 快照的名称。 |
| snapshot_type | 快照的类型。 目前,只有 automated 可用。 |
| created_time | 创建快照的时间。 |
| fe_journal_id | FE 日志的 ID。 |
| starmgr_journal_id | StarManager 日志的 ID。 |
| properties | 适用于尚未提供的功能。 |
| storage_volume | 存储快照的存储卷。 |
| storage_path | 存储快照的存储路径。 |
查看集群快照作业
您可以查询视图 information_schema.cluster_snapshot_jobs 以查看集群快照的作业信息。
SELECT * FROM information_schema.cluster_snapshot_jobs;
返回
| 字段 | 描述 |
|---|---|
| snapshot_name | 快照的名称。 |
| job_id | 作业的 ID。 |
| created_time | The time at which the job was created. |
| finished_time | 作业完成的时间。 |
| state | 作业的状态。 有效值:INITIALIZING、SNAPSHOTING、FINISHED、EXPIRED、DELETED 和 ERROR。 |
| detail_info | 当前执行阶段的特定进度信息。 |
| error_message | 作业的错误消息(如果有)。 |
恢复集群
按照以下步骤使用集群快照恢复集群。
-
(可选)如果存储集群快照的存储位置(存储卷)已更改,则必须将原始存储路径下的所有文件复制到新路径。 为此,您必须修改 Leader FE 节点的目录
fe/conf下的配置文件 cluster_snapshot.yaml。 有关 cluster_snapshot.yaml 的模板,请参阅 附录。 -
启动 Leader FE 节点。
./fe/bin/start_fe.sh --cluster_snapshot --daemon -
在清除
meta目录后启动其他 FE 节点。./fe/bin/start_fe.sh --helper <leader_ip>:<leader_edit_log_port> --daemon -
在清除
storage_root_path目录后启动 CN 节点。./be/bin/start_cn.sh --daemon
如果您已在步骤 1 中修改了 cluster_snapshot.yaml,则将在新集群中根据文件中的信息重新配置节点和存储卷。
附录
cluster_snapshot.yaml 的模板
# Information of the cluster snapshot to be downloaded for restoration.
cluster_snapshot:
# The URI of the snapshot.
# Example 1: s3://defaultbucket/test/f7265e80-631c-44d3-a8ac-cf7cdc7adec811019/meta/image/automated_cluster_snapshot_1704038400000
# Example 2: s3://defaultbucket/test/f7265e80-631c-44d3-a8ac-cf7cdc7adec811019/meta
cluster_snapshot_path: <cluster_snapshot_uri>
# The name of the storage volume to store the snapshot. You must define it in the `storage_volumes` section.
# NOTE: It must be identical with that in the original cluster.
storage_volume_name: my_s3_volume
# [Optional] Node information of the new cluster where the snapshot is to be restored.
# If this section is not specified, the new cluster after recovery only has the Leader FE node.
# CN nodes retain the information of the original cluster.
# NOTE: DO NOT include the Leader FE node in this section.
frontends:
# FE host.
- host: xxx.xx.xx.x1
# FE edit_log_port.
edit_log_port: 9010
# The FE node type. Valid values: `follower` (Default) and `observer`.
type: follower
- host: xxx.xx.xx.x2
edit_log_port: 9010
type: observer
compute_nodes:
# CN host.
- host: xxx.xx.xx.x3
# CN heartbeat_service_port.
heartbeat_service_port: 9050
- host: xxx.xx.xx.x4
heartbeat_service_port: 9050
# Information of the storage volume in the new cluster. It is used for restoring a cloned snapshot.
# NOTE: The name of the storage volume must be identical with that in the original cluster.
storage_volumes:
# Example for S3-compatible storage volume.
- name: my_s3_volume
type: S3
location: s3://defaultbucket/test/
comment: my s3 volume
properties:
- key: aws.s3.region
value: us-west-2
- key: aws.s3.endpoint
value: https://s3.us-west-2.amazonaws.com
- key: aws.s3.access_key
value: xxxxxxxxxx
- key: aws.s3.secret_key
value: yyyyyyyyyy
# Example for HDFS storage volume.
- name: my_hdfs_volume
type: HDFS
location: hdfs://127.0.0.1:9000/sr/test/
comment: my hdfs volume
properties:
- key: hadoop.security.authentication
value: simple
- key: username
value: starrocks
有关 AWS 凭据的更多信息,请参阅验证到 AWS S3 的身份。